IPv4/IPv6翻译与封装过渡——IVI/MAP-T/MAP-E(1)(4)
2.3 端口映射
MAP的核心技术之一是无状态地址和端口映射算法,其思想是利用16位的传输层( 传输控制协议(TCP)、数据报协议(UDP))端口对于IPv4地址进行扩展。不复用IPv4地址时,一个终端设备可用的并发TCP或UDP的端口数为65 536;如复用比为16,则一个终端可用的并发TCP或UDP的端口数为4096;如复用比为128,则一个终端可用的并发TCP或UDP的端口数为512。根据统计,一个普通终端的并发TCP或UDP的端口数为有限的,因此可以利用无状态地址和端口映射算法高效率地复用公有IPv4地址资源。在使用无状态地址和端口映射算法时,需要给每一个终端定义一个端口标识集(PSID),端口标识集和可用端口的映射关系由扩展的模算法来决定。
扩展的模算法的定义为:
(1)给定PSID,该端系统可以使用的传输层端口P 为:P =R×M×j+M×K+i ,其中R为复用比,M为连续端口数,i和j为整数变量。
(2)给定传输层端口P,该端系统的PSID为:P=floor(P/M)%R ,其中floor为只舍不入的取整算法,%为常规定义的模运算符。
扩展的模算法是一个适应性很广的算法,即可以使持有不同PSID终端所使用的传输层端口在整个端口空间均匀分布,也可以按块分布,还可以制订每一块包含的连续端口数量。此外,扩展的模算法还可以支持类似与无分类地址域间路由(CIDR)类似的地址聚类,即对应于特定的PSID,可以定义PSID长度,对于可用端口进行聚类使用。
通过扩展的模算法,在给定复用比、连续端口数量和端口聚类长度的条件下,可以通过PSID的值计算出特定终端可以使用的所有的TCP或UDP端口;也可以对于任意给定端口计算出对应的PSID,实现端系统的无状态公有IPv4地址复用,因而可以极大地减小管理开销,并极大地提高安全性和可溯源性。由于ICMP和ICMPv6没有源和目标端口的域,只有标识域(ID),因此要对标识域ID作扩展的模算法映射。
2.4 地址格式
MAP的地址格式是RFC6052的扩展,如图5 所示。
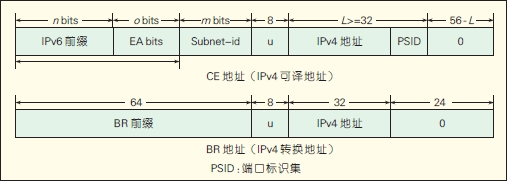
图5 MAP地址格式
与RFC6052的区别主要有:
(1)MAP的地址格式是RFC6052当Prefix长度为64的一个特例,其Prefix里包含IPv6 Prefix、EA-bits(由IPv4 子网标识和PSID组成,用于唯一标识不同的用户)和Subnet-id(用于标识一个用户使用的大于等于/64 的IPv6 子网)。
(2)在MAP中Suffix不为0,而是嵌入了PSID。
(3)MAP对于转换地址和可译地址使用不同的Prefix,以解决为终端用户分配前缀,而不是响应单个地址的要求。
利用EA-bits可以为每一个家庭网关CE分配唯一的Prefix,不使用EA-bits,而为每个CE分配不同的Prefix 也可以达到同样的目的。采用EA-bits的好处是可以进行地址聚类,可扩展性好;不采用EA-bits的好处是IPv6前缀与IPv4地址独立。这两种方法各有优缺点,可以根据不同需要进行选择。
2.5 统一双重翻译和封装模式的机制
无状态双重IPv4/IPv6翻译可以支持纯IPv4应用程序(如Skype),同时对于嵌入IP地址的应用程序(如Ftp)也不需要IPv4/IPv6之间的应用层网关(ALG),此外双重翻译不需要DNS64和DNS46。无状态双重翻译可以看成是具有头压缩功能的、无状态IPv4 over IPv6的封装技术。无状态双重翻译技术(MAP-T)和无状态封装技术(MAP-E)采用同样扩展的模算法和同样的地址格式(在封装模式下BR地址可以蜕化为单个地址),因此具有众多的相似性,唯一的不同是数据流处理模式。在双重翻译模式(MAP-T)下数据流的处理依据为翻译,由RFC6145定义,在封装模式(MAP-E)下数据流的处理为数据封装,由RFC2473定义[13]。
MAP-T模式的优点是可以蜕化为一次翻译,有利于过渡到纯IPv6网络,但仍然保持与IPv4互联网的互联互通。同时,在IPv6接入网内的IPv6数据报文没有封装的数据结构,可以使用IPv6路由器上的所有网络层和传输层的管理和控制功能,而MAP-E必须对于数据报文进行解封装,才能进行管理和控制。MAP-E模式的优点是可以完全保持IPv4报文承载的所有信息,同时不需要对传输层的校验和进行修改。由于RFC2473定义的封装模式与传输层的TCP、UDP均由IPv6头结构的下一个头定义,因此,只有从IPv4到IPv6的处理需要定义采用翻译模式还是封装模式,从IPv6到IPv4的处理可以根据下一个头自动适应性完成翻译或封装模式的选择。因此,MAP-T和MAP-E可以根据需求灵活配置,其分析参见MAP测试文档[14]。
评论暂时关闭