一文彻底搞懂zookeeper核心知识点,
一文彻底搞懂zookeeper核心知识点,
初识 zookeeper
Zookeeper 它作为Hadoop项目中的一个开源子项目,是一个经典的分布式数据一致性解决方案,致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务。
1、zookeeper数据模型
zookeeper 维护了一个类似文件系统的数据结构,每个子目录(/微信、/微信/公众号)都被称作为 znode 即节点。和文件系统一样,我们可以很轻松的对 znode 节点进行增加、删除等操作,而且还可以在一个znode下增加、删除子znode,区别在于文件系统的是,znode可以存储数据(严格说是必须存放数据,默认是个空字符)。
由于zookeeper是目录节点结构,在获取和创建节点时,必须要以“/” 开头,否则在获取节点时会报错 Path must start with / character。
- [zk: localhost:2181(CONNECTED) 13] get test
- Command failed: java.lang.IllegalArgumentException: Path must start with / character
根节点名必须为“/XXX”,创建子节点时必须要带上根节点目录“/XXX/CCC”、“/XXX/AAA”。
例如:想要获取下图 程序员内点事 节点必须拼接完整的路径 get /微信/公众号/程序员内点事
get /微信/公众号/程序员内点事

在这里插入图片描述
znode被用来存储 byte级 或 kb级 的数据,可存储的最大数据量是1MB(请注意:一个节点的数据量不仅包含它自身存储数据,它的所有子节点的名字也要折算成Byte数计入,因此znode的子节点数也不是无限的)虽然可以手动的修改节点存储量大小,但一般情况下并不推荐这样做。
2、znode节点属性
一个znode节点不仅可以存储数据,还有一些其他特别的属性。接下来我们创建一个/test节点分析一下它各个属性的含义。
- [zk: localhost:2181(CONNECTED) 6] get /test
- 456
- cZxid = 0x59ac //
- ctime = Mon Mar 30 15:20:08 CST 2020
- mZxid = 0x59ad
- mtime = Mon Mar 30 15:22:25 CST 2020
- pZxid = 0x59ac
- cversion = 0
- dataVersion = 2
- aclVersion = 0
- ephemeralOwner = 0x0
- dataLength = 3
- numChildren = 0
| 节点属性 | 注解 |
|---|---|
| cZxid | 该数据节点被创建时的事务Id |
| mZxid | 该数据节点被修改时最新的事物Id |
| pZxid | 当前节点的父级节点事务Id |
| ctime | 该数据节点创建时间 |
| mtime | 该数据节点最后修改时间 |
| dataVersion | 当前节点版本号(每修改一次值+1递增) |
| cversion | 子节点版本号(子节点修改次数,每修改一次值+1递增) |
| aclVersion | 当前节点acl版本号(节点被修改acl权限,每修改一次值+1递增) |
| ephemeralOwner | 临时节点标示,当前节点如果是临时节点,则存储的创建者的会话id(sessionId),如果不是,那么值=0 |
| dataLength | 当前节点所存储的数据长度 |
| numChildren | 当前节点下子节点的个数 |
我们看到一个znode节点的属性比较多,但比较主要的属性还是zxid、version、acl 这三个。
Zxid:
znode节点状态改变会导致该节点收到一个zxid格式的时间戳,这个时间戳是全局有序的,znode节点的建立或者更新都会产生一个新的。如果zxid1的值 < zxid2的值,那么说明zxid2发生的改变在zxid1之后。每个znode节点都有3个zxid属性,cZxid(节点创建时间)、mZxid(该节点修改时间,与子节点无关)、pZxid(该节点或者该节点的子节点的最后一次创建或者修改时间,孙子节点无关)。
zxid属性主要应用于zookeeper的集群,这个后边介绍集群时详细说。
Version:
znode属性中一共有三个版本号dataversion(数据版本号)、cversion(子节点版本号)、aclversion(节点所拥有的ACL权限版本号)。
znode中的数据可以有多个版本,如果某一个节点下存有多个数据版本,那么查询这个节点数据就需要带上版本号。每当我们对znode节点数据修改后,该节点的dataversion版本号会递增。当客户端请求该znode节点时,会同时返回节点数据和版本号。另外当dataversion为 -1的时候可以忽略版本进行操作。对一个节点设置权限时aclVersion版本号会递增,下边会详细说ACL权限控制。
验证一下,我们修改/test节点的数据看看dataVersion有什么变化,发现dataVersion属性变成了 3,版本号递增了。
- [zk: localhost:2181(CONNECTED) 10] set /test 8888
- cZxid = 0x59ac
- ctime = Mon Mar 30 15:20:08 CST 2020
- mZxid = 0x59b6
- mtime = Mon Mar 30 16:58:08 CST 2020
- pZxid = 0x59ac
- cversion = 0
- dataVersion = 3
- aclVersion = 0
- ephemeralOwner = 0x0
- dataLength = 4
- numChildren = 0
3、znode的类型
zookeeper 有四种类型的znode,在用客户端 client 创建节点的时候需要指定类型。
- zookeeper.create("/公众号/程序员内点事", "".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
- PERSISTENT-持久化目录节点 :client创建节点后,与zookeeper断开连接该节点将被持久化,当client再次连接后节点依旧存在。
- PERSISTENT_SEQUENTIAL-持久化顺序节点 :client创建节点后,与zookeeper断开连接该节点将被持久化,再次连接节点还存在,zookeeper会给该节点名称进行顺序编号,例如:/lock/0000000001、/lock/0000000002、/lock/0000000003。
- EPHEMERAL-临时目录节点 :client与zookeeper断开连接后,该节点即会被删除
- EPHEMERAL_SEQUENTIAL-临时顺序节点 :client与zookeeper断开连接后,该节点被删除,会给该节点名称进行顺序编号,例如:/lock/0000000001、/lock/0000000002、/lock/0000000003。
节点的ACL权限控制
ACL:即 Access Control List (节点的权限控制),通过ACL机制来解决znode节点的访问权限问题,要注意的是zookeeper对权限的控制是基于znode级别的,也就说节点之间的权限不具有继承性,即子节点不继承父节点的权限。
zookeeper中设置ACL权限的格式由<schema>:<id>:<acl>三段组成。
schema :表示授权的方式
- world:表示任何人都可以访问
- auth:只有认证的用户可以访问
- digest:使用username :password用户密码生成MD5哈希值作为认证ID
- host/ip:使用客户端主机IP地址来进行认证
id:权限的作用域,用来标识身份,依赖于schema选择哪种方式。
acl:给一个节点赋予哪些权限,节点的权限有create,、delete、write、read、admin 统称 cdwra。
1、world:表示任何人都可以访问
我们用 getAcl 命令来看一下,没有设置过权限的znode节点,默认情况下的权限情况。
- [zk: localhost:2181(CONNECTED) 12] getAcl /test
- 'world,'anyone
- : cdrwa
看到没有设置ACL属性的节点,默认schema 使用的是world,作用域是anyone,节点权限是cdwra,也就是说任何人都可以访问。
那我们如果要给一个schema 为非world的节点设置world权限咋搞?
- setAcl /test world:anyone:crdwa
2、auth:只有认证的用户可以访问
schema 用auth授权表示只有认证后的用户才可以访问,那么首先就需要添加认证用户,添加完以后需要对认证的用户设置ACL权限。
addauth digest test:password(明文)
需要注意的是设置认证用户时的密码是明文的。
- [zk: localhost:2181(CONNECTED) 2] addauth digest user:user //用户名:密码
- [zk: localhost:2181(CONNECTED) 5] setAcl /test auth:user:crdwa
- [zk: localhost:2181(CONNECTED) 6] getAcl /test
- 'digest,'user:ben+k/3JomjGj4mfd4fYsfM6p0A=
- : cdrwa
实际上我们这样设置以后,就是将这个节点开放给所有认证的用户,setAcl /test auth:user:crdwa 相当于setAcl /test auth::crdwa。
3、digest:用户名:密码的验证方式
用户名:密码方式授权是针对单个特定用户,这种方式是不需要先添加认证用户的。
如果在代码中使用zookeeper客户端设置ACL,那么密码是明文的,但若是zk.cli等客户端操作就需要将密码进行sha1及base64处理。
- setAcl <path> digest:<user>:<password(密文)>:<acl>
- setAcl /test digest:user:jalRr+knv/6L2uXdenC93dEDNuE=:crdwa
那么密码如何加密嘞?有以下几种方式:
通过shell命令加密
- echo -n <user>:<password> | openssl dgst -binary -sha1 | openssl base64
使用zookeeper自带的类库org.apache.zookeeper.server.auth.DigestAuthenticationProvider生成
- java -cp /zookeeper-3.4.13/zookeeper-3.4.13.jar:/zookeeper-3.4.13/lib/slf4j-api-1.7.25.jar \
- org.apache.zookeeper.server.auth.DigestAuthenticationProvider \
- root:root
- root:root->root:qiTlqPLK7XM2ht3HMn02qRpkKIE=
4、host/ip:使用客户端主机IP地址来进行认证
这种方式就比较好理解了,通过对特定的IP地址,也可以是一个IP段进行授权。
- [zk: localhost:2181(CONNECTED) 3] setAcl /test0000000014 ip:127.0.0.1:crdwa
- cZxid = 0x59ac
- ctime = Mon Mar 30 15:20:08 CST 2020
- mZxid = 0x59b6
- mtime = Mon Mar 30 16:58:08 CST 2020
- pZxid = 0x59ac
- cversion = 0
- dataVersion = 3
- aclVersion = 3 // 这个版本一直在增加
- ephemeralOwner = 0x0
- dataLength = 4
- numChildren = 0
zookeeper 灵魂 watcher
我们在开头就说过:zookeeper可以为dubbo提供服务的注册与发现,作为注册中心,但你有想过zookeeper为啥能够实现服务的注册与发现吗?这就不得不说一下zookeeper的灵魂 Watcher(监听者)。
1、watcher是个啥?
watcher 是zooKeeper中一个非常核心功能 ,客户端watcher 可以监控节点的数据变化以及它子节点的变化,一旦这些状态发生变化,zooKeeper服务端就会通知所有在这个节点上设置过watcher的客户端 ,从而每个客户端都很快感知,它所监听的节点状态发生变化,而做出对应的逻辑处理。
简单的介绍了一下watcher ,那么我们来分析一下,zookeeper是如何实现服务的注册与发现。zookeeper的服务注册与发现,主要应用的是zookeeper的znode节点数据模型和watcher机制,大致的流程如下:
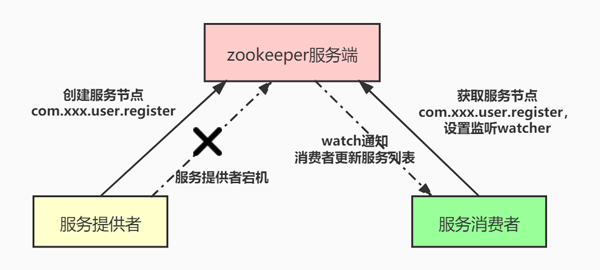
在这里插入图片描述
- 服务注册: 服务提供者(Provider)启动时,会向zookeeper服务端注册服务信息,也就是创建一个节点,例如:用户注册服务com.xxx.user.register,并在节点上存储服务的相关数据(如服务提供者的ip地址、端口等)。
- 服务发现: 服务消费者(Consumer)启动时,根据自身配置的依赖服务信息,向zookeeper服务端获取注册的服务信息并设置watch监听,获取到注册的服务信息之后,将服务提供者的信息缓存在本地,并进行服务的调用。
- 服务通知: 一旦服务提供者因某种原因宕机不再提供服务之后,客户端与zookeeper服务端断开连接,zookeeper服务端上服务提供者对应服务节点会被删除(例如:用户注册服务com.xxx.user.register),随后zookeeper服务端会异步向所有消费用户注册服务com.xxx.user.register,且设置了watch监听的服务消费者发出节点被删除的通知,消费者根据收到的通知拉取最新服务列表,更新本地缓存的服务列表。
上边的过程就是zookeeper可以实现服务注册与发现的大致原理。
2、watcher类型
znode节点可以设置两类watch,一种是DataWatches,基于znode节点的数据变更从而触发 watch 事件,触发条件getData()、exists()、setData()、 create()。
另一种是Child Watches,基于znode的孩子节点发生变更触发的watch事件,触发条件 getChildren()、 create()。
而在调用 delete() 方法删除znode时,则会同时触发Data Watches和Child Watches,如果被删除的节点还有父节点,则父节点会触发一个Child Watches。
3、watcher特性
watch对节点的监听事件是一次性的!客户端在指定的节点设置了监听watch,一旦该节点数据发生变更通知一次客户端后,客户端对该节点的监听事件就失效了。
如果还要继续监听这个节点,就需要我们在客户端的监听回调中,再次对节点的监听watch事件设置为True。否则客户端只能接收到一次该节点的变更通知。
zookeeper 实现的功能
服务的注册与发现功能只是zookeeper的冰山一角,它还能实现诸如分布式锁、队列、配置中心等一系列功能,接下来我们只分析一下原理,具体的实现大家上网查一下资料还是比较全的。
1、分布式锁
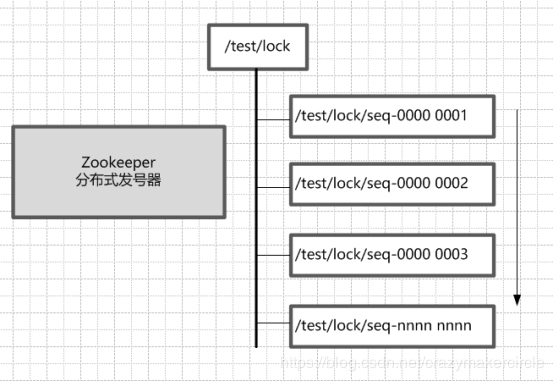
zookeeper基于watcher机制和znode的有序节点,天生就是一个分布式锁的坯子。首先创建一个/test/lock父节点作为一把锁,尽量是持久节点(PERSISTENT类型),每个尝试获取这把锁的客户端,在/test/lock父节点下创建临时顺序子节点。
由于序号的递增性,我们规定序号最小的节点即获得锁。例如:客户端来获取锁,在/test/lock节点下创建节点为/test/lock/seq-00000001,它是最小的所以它优先拿到了锁,其它节点等待通知再次获取锁。/test/lock/seq-00000001执行完自己的逻辑后删除节点释放锁。
那么节点/test/lock/seq-00000002想要获取锁等谁的通知呢?
这里我们让/test/lock/seq-00000002节点监听/test/lock/seq-00000001节点,一旦/test/lock/seq-00000001节点删除,则通知/test/lock/seq-00000002节点,让它再次判断自己是不是最小的节点,是则拿到锁,不是继续等通知。
以此类推/test/lock/seq-00000003节点监听/test/lock/seq-00000002节点,总是让后一个节点监听前一个节点,不用让所有节点都监听最小的节点,避免设置不必要的监听,以免造成大量无效的通知,形成“羊群效应”。
zookeeper分布式锁和redis分布式锁相比,因为大量的创建、删除节点性能上比较差,并不是很推荐。
2、分布式队列
zookeeper实现分布式队列也很简单,应用znode的有序节点天然的“先进先出”,后创建的节点总是最大的,出队总是拿序号最小的节点即可。
3、配置管理
现在有很多开源项目都在使用Zookeeper来维护配置,像消息队列Kafka中,就使用Zookeeper来维护broker的信息;dubbo中管理服务的配置信息。原理也是基于watcher机制,例如:创建一个/config节点存放一些配置,客户端监听这个节点,一点修改/config节点的配置信息,通知各个客户端数据变更重新拉取配置信息。
4、命名服务
zookeeper的命名服务:也就是我们常说的服务注册与发现,主要是根据指定名字来获取资源或服务的地址,服务提供者等信息,利用其znode节点的特点和watcher机制,将其作为动态注册和获取服务信息的配置中心,统一管理服务名称和其对应的服务器列表信息,我们能够近乎实时地感知到后端服务器的状态(上线、下线、宕机)。
评论暂时关闭