Linux基础介绍【第四篇】,linux基础第四篇
Linux基础介绍【第四篇】,linux基础第四篇

Linux文件和目录的属性及权限
命令:
第一列:inode(index node)索引节点编号,文件或目录在磁盘里的唯一标识,linux读取文件首先要读取到这个文件的索引节点(类似书的目录)。
第二列:
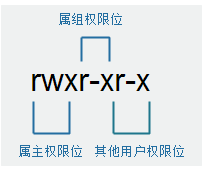
第1个字符:文件类型,-普通文件,d目录。(windows扩展名.jpg,.avi)
第2—10个字符rw-r—r--:文件权限(r(read)读取权限、w(write)写权限,x(execute)执行权限,-无权限)
第11个字符.:SELINUX相关。
第三列:文件硬链接数。文件硬链接是文件的又一个入口。硬链接inode一样。
第四列:文件的属主或用户。
第五列:文件对应的属组或用户组(团体)。
权限对应关系图:
第六列:文件或目录的大小。
第七八九列:文件最近修改时间。
第十列:文件或目录名。
索引节点inode
inode概述
硬盘要分区,然后格式化,创建文件系统。
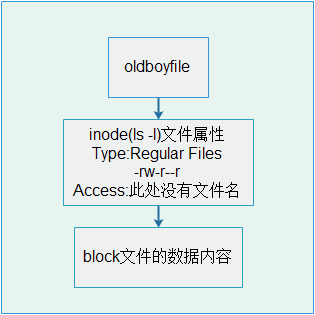
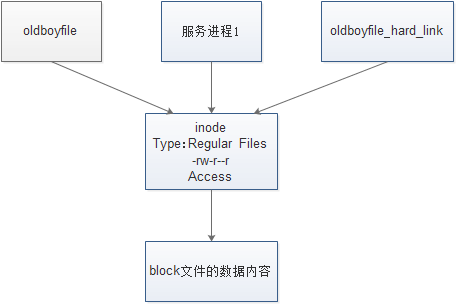
inode,索引节点(index node)。在每个linux存储设备或存储设备的分区(存储设备可以是硬盘、软盘、U盘等)被格式化为ext4文件系统后,一般都有两部分:第一部分是inode(很多个),第二部分是block(很多个)。
block是用来存储实际数据用的,例如:照片、视频等普通文件数据。inode就是用来存储这些数据属性信息的(也就是ls -l的结果),inode包含的属性信息包括文件大小、宿主、归属的用户组、读写权限、文件类型,修改时间,还包含指向文件实体的指针的功能(inode节点—block的对应关系等),但是,inode唯独不包含文件名。
inode除了记录文件属性的信息外,还会为每个文件进行信息索引,所以就有了inode的数值。操作系统根据指令,即可通过inode的值最快的找到相对应的文件实体。文件,inode、block之间的关系见下图:
查看inode大小:
查看inode大小:
查看挂载的磁盘inode使用情况:
查看挂载的磁盘block使用情况:
有关inode的小结:
1、磁盘分区格式化ext4文件系统后会生成一定数量的inode和block。
2、inode的索引节点,作用是存放文件的属性信息以及作为文件的索引(指向文件的实体)。
3、ext3/ext4文件系统的block存放的是文件的实际内容。
4、inode是一块存储空间,c6非启动分区inode默认大小256字节,c5是128字节。
5、inode是一串数字,不同的文件对应的inode(一串数字)在文件系统里是唯一的。
6、inode号相同的文件,互为硬链接文件(文件的又一个入口)。
7、一个文件被创建后至少要占用一个inode和一个block。
8、block的大小一般有1k、2k、4k几种,其中引导分区等为1k,其他普通分区为4k(c6)。
9、如果一个文件很大,可能占多个block。
10、如果文件很小,至少占一个,并且剩余空间不能被其它文件使用。
11、inode大小和总量查看。
12、查看inode的总量和使用量命令df -i。
13、生成及指定inode大小mkfs.ext4 -b 2048 -I 256 /dev/sdb1。
block的知识:
1、磁盘读取数据是按block为单位读取的。
2、一个文件可能占用多个block。每读取一个block就会消耗一次磁盘I/O。
3、如果要提升磁盘I/O性能,那么就要尽可能一次性读取数据尽量的多。
4、一个block只能存放一个文件的内容,无论内容有多小。如果block 4k,那么存放1k的文件,剩余3k就浪费了。
5、block并非越大越好。block太大对于小文件存放就会浪费磁盘空间。例如:1000k的文件,block为4k,占用250个block,block为1k,占用1000个block。消耗I/O分别为250次和1000次。
6、大文件(大于16k)一般设置block大一点,小文件(小于1k)一般设置block小一点。
7、block太大例如4k,文件都是0.1k的,大量浪费磁盘空间。
8、block的设置也是格式化分区的时候,mkfs.ext4 -b 2048 -l 256 /dev/sdb。
9、文件较大时,block设置大一些会提升磁盘访问效率。
10、ext3/ext4文件一般设置为4k。
当前的生产环境一般设置为4k。特殊的业务,如视频可以加大block大小。
linux的文件类型和扩展名
linux中的文件类型
在linux系统中,可以说一切皆文件。文件类型包含有普通文件、目录、字符设备文件、块设备文件、符号链接文件等。
普通文件(regular file):第一个属性为"-",按照文件内容,又大略可分为如下三种:
1、纯文本文件(ascii):文件内容可以直接读到数据,例如:字母、数字等。可以用cat命令读出文件内容。
2、二进制文件(binary):linux当中可执行文件(命令)就是属于这种格式。例如cat这个执行文件就是一个二进制文件。
3、数据格式文件(data):有些程序在运行的过程中会读取某些特定格式的文件,那些特定格式的文件可以被称为数据文件。例如:linux在用户登录时,都会将登录的数据记录在/var/log/wtmp那个文件内,该文件是一个数据文件。通过last命令读出来。cat命令会读出乱码。因为它属于一种特殊格式的文件。
文件类型小结:
1、- regular file普通文件
纯文本、二进制文件、数据文件。
2、d directory目录。
3、l link符号链接或者软链接文件。
快捷方式,指向文件的实体。
4、字符文件,块设备文件
c character串口设备、猫
b block硬盘、光驱。
5、.sock进程之间通信
s sock
6、管道文件
p
linux下扩展名的作用
1、源码.tar、tar.gz、.tgz、.zip、.tar.bz表示压缩文件,创建命令tar、gzip、zip等。
2、.sh表示shell脚本文件,通过shell语言开发的程序。
3、.pl表示perl语言文件,通过perl语言开发的程序。
4、.py表示python语言文件,通过python语言开发的程序。
5、.html、.htm、.php、.jsp、.do表示网页语言的文件。
6、.conf表示系统服务的配置文件。
7、.rpm表示rpm安装包文件。
linux系统硬链接和软链接
在linux系统中,链接可分为两种,一种是硬链接(Hard Link),另一种为软链接或符号链接(Symbolic Link or Soft link)。
创建硬链接:ln 源文件 目标文件
创建软链接:ln -s 源文件 目标文件(目标文件不能事先存在)
硬链接
硬链接是指通过索引节点(Inode)来进行链接。在linux(ex2、ex3、ex4)文件系统中,保存在磁盘分区中的文件不管是什么类型都会给它分配一个编号,这个编号被称为索引节点编号(index inode)简称inode,即在系统中文件的编号。
在linux文件系统中,多个文件名指向同一个索引节点(inode)是正常且允许的。这种情况的文件就称为硬链接。提示:硬链接文件就相当于文件的另外一个入口。硬链接的作用之一是允许一个文件拥有多个有效路径名(多个入口),这样用户存储中的快照功能就应用了这个原理,增加一个快照就多了一个硬链接。
为什么一个文件建立了硬链接就会防止数据误删呢?
因为文件系统(ex2)的原理是,只要文件的索引节点(inode index)还有一个以上的硬链接。只删除其中一个硬链接(即仅仅删除了该文件的链接指向)并不影响索引节点本身和其它的链接(即数据文件实体并未被删除),只有当文件的最后一个链接被删除后,此时如果有新数据要存储到硬盘上时或者系统通过类似fsck做磁盘检查的时候。被删除文件的数据块及目录的链接才会被释放,空间被新数据占用并覆盖。此时,数据就再也无法找回了。也就是说,在linux系统中,删除静态文件(没有进程调用)(目录也是文件)的条件是与之相关的所有硬链接文件均被删除。
硬链接原理图:
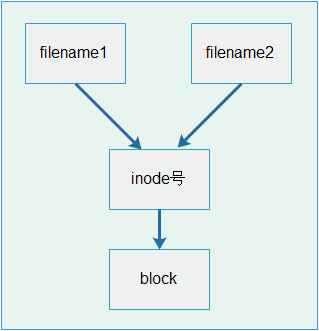
硬链接示意图:

硬链接小结:
1、具有相同inode节点号的多个文件是互为硬链接文件。
2、删除硬链接文件或者删除源文件任意之一,文件实体并未被删除。
3、只有删除了源文件及所有对应的硬链接文件,文件实体才会被删除。
4、当所有的硬链接文件及源文件被删除后,再存放新的数据会占用这个文件的空间,或者磁盘fsck检查的时候,删除的数据也会被系统回收。
5、硬链接文件就是文件的又一个入口(相当于超市的前门、后门一样)。
6、可以通过给文件设置硬链接文件,来防止重要文件被误删。
7、通过执行命令"ln 源文件 硬链接文件",即可完成创建硬链接。
8、硬链接文件可以用rm命令删除。
9、对于静态文件(没有进程正在调用的文件)来讲,当对应硬链接数为0(i_link),文件就被删除。i_link的查看方法(ls -l结果的第三列)。
软链接
软链接(Soft Link)也称为符号链接(Symbolic Link)。linux里的软链接文件就类似于windows系统中的快捷方式。linux里的软链接文件实际上是一个特殊的文件,文件类型是i。软链接文件实际上可以理解为一个文本文件,这个文件中包含有软链接指向另一个源文件的位置信息内容,因此,通过访问这个"快捷方式"就可以迅速定位到软链接所指向的源文件实体。
软链接原理图:
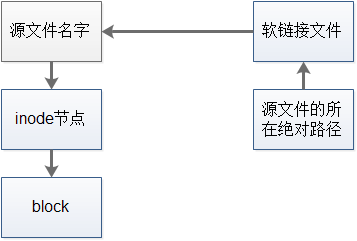
注意:创建软链接文件是需要存在的,要创建的软链接文件是不能存在的,要用ln命令创建。
软链接小结:
1、软链接类似windows的快捷方式(可以通过readlink查看其指向)。
2、软链接类似一个文本文件,里面存放的是源文件的路径,指向源文件实体。
3、删除源文件,软链接文件依然存在,但是无法访问指向的源文件路径内容了。
4、失效的时候一般是白字红底闪烁提示。
5、执行命令"ln -s 源文件 软链接文件",即可完成创建软链接(目标不能存在)。
6、软链接和源文件是不同类型的文件,也是不同的文件,inode号不同。
7、删除软链接文件可以用rm命令。
目录创建软链接:
总结:当删除原始文件oldboyfile后,其硬链接文件oldboyfile_hard_link不受影响,对应的数据依然存在,但是其对应的软链接文件oldboyfile_soft_link失效了,找不到源文件了,此时,可以删除软链接文件重建,或者创建一个oldboyfile_hard_link的硬链接文件oldboyfile。
企业生产软链接作用:
1、编译软件时指定版本号(/application/apache2.2.23),访问时希望去掉版本号(/application/apache),可以设置软链接到编译的路径。所有程序都访问软链接文件(/application/apache),当软件升级高版本后,只需删除链接文件重建到高版本路径的软链接即可(/application/apache)。
2、企业代码发布时(php程序),需要把所有代码传到一个新发布的临时目录或者新的站点目录。发布时要么使用mv,也可以重建软链接指向到这个新的临时目录或者新的站点目录。
3、不方便目录移动,使用ln -s。
有关文件的链接小结
1、删除软链接oldboyfile_soft_link,对oldboyfile、oldboyfile_hard_link无影响;
全局结论:删除软链接文件对源文件及硬链接文件无任何影响。
2、删除硬链接oldboyfile_hard_link,对oldboyfile、oldboyfile_soft_link都无影响;
全局结论:删除硬链接文件对源文件及软链接文件无任何影响。
3、删除源文件oldboyfile,对硬链接oldboyfile_hard_link没有影响,但是会导致软链接oldboyfile_soft_link失效;
全局结论:删除源文件,对硬链接文件没有影响,但是会导致软链接文件失效,呈现红底白字闪烁。
4、同时删除源文件oldboyfile,硬链接文件oldboyfile_hard_link,整个文件会真正的被删除。
5、很多硬件设备中的快照功能,就是利用了硬链接的原理。
6、源文件和硬链接文件具有相同的索引节点号,可以认为是同一个文件或一个文件的多个入口。
7、源文件和软链接文件的索引节点号不同,是不同的文件,软链接相当于源文件的快捷方式,含有源文件的位置指向。
有关目录链接小结:
1、对于目录,不可以创建硬链接,但可以创建软链接。
2、对于目录的软链接是生产场景运维中常用的技巧。
3、目录的硬链接不能跨文件系统(从硬链接原理可以理解)。
4、每个目录下面都有一个硬链接"."号,和对应上级目录的硬链接".."。
5、在父目录里创建一个子目录,父目录的连接数加1(子目录里都有..来指向父目录)。但是在父目录里创建文件,父目录的链接数不会增加。
linux下文件删除原理
删除原理描述
linux的文件名是存在父目录的block里面,并指向这个文件的inode节点,这个文件的inode节点再标记指向存放这个文件的block的数据块。我们删除一个文件,实际上并不是清楚inode节点和block的数据。只是在这个文件的父目录里面的block中,删除这个文件的名字,从而使这个文件名消失,并且无法指向这个文件的inode节点,当没有文件名指向这个inode节点的时候,会同时释放inode节点和存放这个文件的数据块,并更新inode MAP和block MAP今后让这些位置可以用于放置其他文件数据。
linux下文件删除的原理
文件删除控制的变量:
i_link:文件硬链接数量
i_count:引用计数(有一个程序使用i_count加1)
文件删除的条件:
i_link=0 and i_count=0
说明:以上图形i_link=2和i_count=1。
linux是通过link的数量来控制文件删除的,只有当一个文件不存在任何link的时候,这个文件才会被删除。一般来说,每个文件都有2个link计数器i_link和i_count。
i_count的意义是当前文件使用者(或被调用)的数量,i_link是磁盘的引用计数器。当一个文件被某一个进程引用时,对应i_count数就会增加;当创建文件的硬链接的时候,对应i_link数就会增加。
对于删除命令rm而言,实际就是减少磁盘引用计数i_link。这里就会有一个问题,如果一个文件正在被某个进程调用,而用户却执行rm操作把文件删除了,那么会出现什么结果呢?
当用户执行rm操作删除文件后,再执行ls或者其他文件管理命令,无法再找到这个文件了,但是调用这个删除的文件的进程却在继续正常执行,依然能够从文件中正确的读取及写入内容。这又是为什么呢?
这是因为rm操作只是将文件的i_link减少了,如果没有其它的链接i_link就为0了;但由于该文件依然被进程引用。因此,此文件对应的i_count并不为0,所以即使执行rm操作,但系统并没有真正删除这个文件,当只有i_link和i_count都为0的时候,这个文件才会真正被删除。也就是说,还需要解除该进程对该文件的调用才行。
i_link及i_count是文件删除的真实条件,但是当文件没有被调用时,执行了rm操作删除文件后是否还可以找回被删除的文件呢?
rm操作只是将文件的i_link减少了,或者说置0了,实际就是将文件名到inode的链接删除了,此时,并没有删除文件的实体即(block数据块),此时,如果及时停止机器工作,数据是可以找回的,如果此时继续写入数据,那么新数据就可能被分配到被删除的数据的block数据块,此时,文件就会真正的回收了。
实验:inode耗尽。
查看新增的磁盘:
格式化:
取消自动检查:
挂载:
查看inode:
创建26220个文件:
上述可以看出inode耗尽,不能继续创建文件。
磁盘空间未满:
inode耗尽:
删除:
查看inode:
总结:ln命令不能对目录创建硬链接,但可以对目录创建软链接,对于目录的软链接也是生产场景运维中常用的功能。
linux系统用户和用户组
linux用户划分:
1、超级用户
root uid=0 gid=0。
2、虚拟用户
存在linux中没有实际意义,满足文件或者程序运行的需要而创建的。不能登录,不能使用,UID、GID范围1——499 。在/etc/passwd中末尾以nologin结尾。
3、普通用户
管理员root创建的用户,UID、GID从500开始。
linux系统下的账户文件主要有/etc/passwd、/etc/shadow、/etc/group、/etc/gshadow文件
passwd文件中一行的各个字段简述
账号名称:账号密码:账号UID:账号组GID:用户说明:用户家目录:shell解释器
shadow文件中一行的各个字段详细说明
字段名称 | 注释说明 |
账号名称 | 用户的账号名称 |
账号密码 | 用户密码,这是加密过的口令 |
最近更改密码的时间 | 从1970年1月1日起,到用户最近一次更改口令的天数 |
禁止修改密码的天数 | 从1970年1月1日起,到用户可以更改密码的天数 |
用户必须更改口令的天数 | 从1970年1月1日起,到用户必须更改密码的天数 |
警告更改密码的期限 | 在用户密码过期前多少天提醒用户更改密码 |
不活动时间 | 在用户密码过期之后到禁用账号的天数 |
失效时间 | 从1970年1月1日起,到用户被禁用的天数(useradd -f) |
标志 | 保留 |
ls -l:显示的时间是修改时间。
文件的时间:
Access: 2016-12-11 20:05:12.647999994 +0800(访问时间)find -atime
Modify: 2016-12-10 16:02:10.162999297 +0800(修改时间,内容发生变化)find -mtime
Change: 2016-12-10 16:02:10.162999297 +0800(变化时间,包含Modify、权限、属主、用户组)find -ctime
stat命令查看时间等的属性
linux正则表达式
使用正则表达式注意事项:
1、linux正则一般以行为单位匹配处理的。
2、注意字符集,export LC_ALL=C。
基础正则表达式:元字符意义BRE(basic regular expression)。
1、^word搜索以word开头的。vi ^一行的开头。
2、word$搜索以word结尾的。vi $一行的结尾。
3、^$表示空行。
4、.代表且只能代表任意一个字符。
5、\例如\.只代表点本身,转义符号,让有着特殊身份意义的字符脱掉马甲还原原型。
6、*例如o*重复0个或多个前面的一个字符。
7、.*匹配所有字符。^.*以任意多个字符开头。
8、[abc]匹配字符集合内的任意一个字符[a-zA-Z],[0-9]。
9、[^abc]匹配不包含^后的任意一个字符。
10、a\{n,m\}重复n到m次前面一个重复的字符。如果用egrep、grep -E或sed -r可以去掉斜线。
\{n,\}重复至少n次前面一个重复的字符。
\{,m\}无效
\{n\}重复n次前面一个重复的字符。
扩展的正则表达式:
1、+重复一个或一个以上前面的字符。
2、?重复0或一个0前面的字符。
3、|用或的方式查找多个符合的字符串。
4、()找出"用户组"字符串。
设置别名过滤的内容显示颜色:
过滤以m开头
过滤以m结尾
过滤空行显示
过滤空行显示行号
匹配以.结尾
精确匹配-o
grep一般常用参数:
-a:在二进制文件中以文本文件的方式搜索数据。
-c:计算找到"搜索字符串"的次数。
-o:仅显示出匹配regexp的内容(用于统计出现在文中的次数)。
-i:忽略大小写的不同,所有大小写视为相同。
-n:在行首显示行号。
-v:反向选择,即显示没有"搜索字符串"的内容的那一行。
-E:扩展的grep,及egrep。
--color=auto:以特定颜色高亮显示匹配关键字。
-A:After的意思,显示匹配字符串及其后n行的数据。
-B:Before的意思,显示匹配字符串及其前n行的数据。
-C:显示匹配字符串及其前后各num行。
取出ip地址:
方法一:
方法二:
取出HWaddr:
方法一:
方法二:
stat /etc/hosts中取出0644:
评论暂时关闭