Perf Event :Linux下的系统性能调优工具(1)(3)
使用 perf record, 解读 report
使用 top 和 stat 之后,您可能已经大致有数了。要进一步分析,便需要一些粒度更细的信息。比如说您已经断定目标程序计算量较大,也许是因为有些代码写的不够精简。那么面对长长的代码文件,究竟哪几行代码需要进一步修改呢?这便需要使用 perf record 记录单个函数级别的统计信息,并使用 perf report 来显示统计结果。
您的调优应该将注意力集中到百分比高的热点代码片段上,假如一段代码只占用整个程序运行时间的 0.1%,即使您将其优化到仅剩一条机器指令,恐怕也只能将整体的程序性能提高 0.1%。俗话说,好钢用在刀刃上,不必我多说了。
仍以 t1 为例。
perf record – e cpu-clock ./t1 perf report
结果如下图所示:
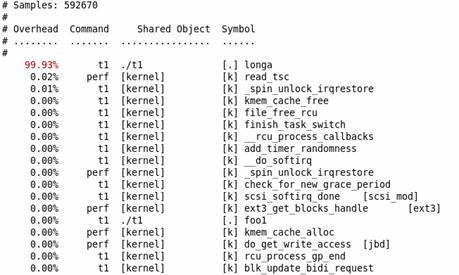
图 2. perf report 示例
不出所料,hot spot 是 longa( ) 函数。
但,代码是非常复杂难说的,t1 程序中的 foo1() 也是一个潜在的调优对象,为什么要调用 100 次那个无聊的 longa() 函数呢?但我们在上图中无法发现 foo1 和 foo2,更无法了解他们的区别了。
我曾发现自己写的一个程序居然有近一半的时间花费在 string 类的几个方法上,string 是 C++ 标准,我绝不可能写出比 STL 更好的代码了。因此我只有找到自己程序中过多使用 string 的地方。因此我很需要按照调用关系进行显示的统计信息。
使用 perf 的 -g 选项便可以得到需要的信息:
perf record – e cpu-clock – g ./t1 perf report
结果如下图所示:
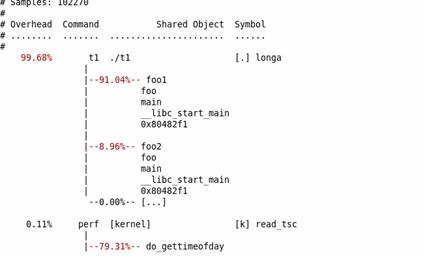
图 3. perf – g report 示例
通过对 calling graph 的分析,能很方便地看到 91% 的时间都花费在 foo1() 函数中,因为它调用了 100 次 longa() 函数,因此假如 longa() 是个无法优化的函数,那么程序员就应该考虑优化 foo1,减少对 longa() 的调用次数。
使用 PMU 的例子
例子 t1 和 t2 都较简单。所谓魔高一尺,道才能高一丈。要想演示 perf 更加强大的能力,我也必须想出一个高明的影响性能的例子,我自己想不出,只好借助于他人。下面这个例子 t3 参考了文章“Branch and Loop Reorganization to Prevent Mispredicts”[6]
该例子考察程序对奔腾处理器分支预测的利用率,如前所述,分支预测能够显著提高处理器的性能,而分支预测失败则显著降低处理器的性能。首先给出一个存在 BTB 失效的例子:
清单 3. 存在 BTB 失效的例子程序
//test.c
#include
#include
void foo()
{
int i,j;
for(i=0; i< 10; i++)
j+=2;
}
int main(void)
{
int i;
for(i = 0; i< 100000000; i++)
foo();
return 0;
}
用 gcc 编译生成测试程序 t3:
gcc – o t3 – O0 test.c
用 perf stat 考察分支预测的使用情况:
[lm@ovispoly perf]$ ./perf stat ./t3 Performance counter stats for './t3': 6240.758394 task-clock-msecs # 0.995 CPUs 126 context-switches # 0.000 M/sec 12 CPU-migrations # 0.000 M/sec 80 page-faults # 0.000 M/sec 17683221 cycles # 2.834 M/sec (scaled from 99.78%) 10218147 instructions # 0.578 IPC (scaled from 99.83%) 2491317951 branches # 399.201 M/sec (scaled from 99.88%) 636140932 branch-misses # 25.534 % (scaled from 99.63%) 126383570 cache-references # 20.251 M/sec (scaled from 99.68%) 942937348 cache-misses # 151.093 M/sec (scaled from 99.58%) 6.271917679 seconds time elapsed
可以看到 branche-misses 的情况比较严重,25% 左右。我测试使用的机器的处理器为 Pentium4,其 BTB 的大小为 16。而 test.c 中的循环迭代为 20 次,BTB 溢出,所以处理器的分支预测将不准确。
对于上面这句话我将简要说明一下,但关于 BTB 的细节,请阅读参考文献 [6]。
for 循环编译成为 IA 汇编后如下:
清单 4. 循环的汇编
// C code
for ( i=0; i < 20; i++ )
{ … }
//Assembly code;
mov esi, data
mov ecx, 0
ForLoop:
cmp ecx, 20
jge
EndForLoop
…
add ecx, 1
jmp ForLoop
EndForLoop:
可以看到,每次循环迭代中都有一个分支语句 jge,因此在运行过程中将有 20 次分支判断。每次分支判断都将写入 BTB,但 BTB 是一个 ring buffer,16 个 slot 写满后便开始覆盖。假如迭代次数正好为 16,或者小于 16,则完整的循环将全部写入 BTB,比如循环迭代次数为 4 次,则 BTB 应该如下图所示:

图 4. BTB buffer
这个 buffer 完全精确地描述了整个循环迭代的分支判定情况,因此下次运行同一个循环时,处理器便可以做出完全正确的预测。但假如迭代次数为 20,则该 BTB 随着时间推移而不能完全准确地描述该循环的分支预测执行情况,处理器将做出错误的判断。
我们将测试程序进行少许的修改,将迭代次数从 20 减少到 10,为了让逻辑不变,j++ 变成了 j+=2;
评论暂时关闭