Linux的页面回收与反向映射机制(1)(5)
使用反向映射
在进行页面回收的时候,Linux 2.6 在前边介绍的 shrink_page_list() 函数中调用 try_to_unmap() 函数去更新所有引用了回收页面的页表项。其代码流程如下所示:
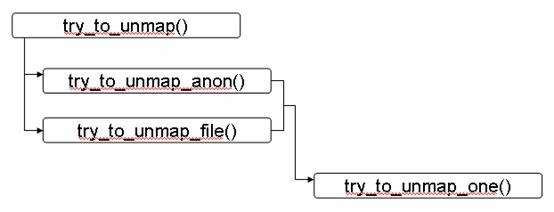
图 6. 实现函数 try_to_unmap() 的关键代码流程图
函数 try_to_unmap() 分别调用了两个函数 try_to_unmap_anon() 和 try_to_unmap_file(),其目的都是检查并确定都有哪些页表项引用了同一个物理页面,但是,由于匿名页面和文件映射页面分别采用了不同的数据结构,所以二者采用了不同的方法。
函数 try_to_unmap_anon() 用于匿名页面,该函数扫描相应的 anon_vma 表中包含的所有内存区域,并对这些内存区域分别调用 try_to_unmap_one() 函数。
函数 try_to_unmap_file() 用于文件映射页面,该函数会在优先级搜索树中进行搜索,并为每一个搜索到的内存区域调用 try_to_unmap_one() 函数。
两条代码路径最终汇合到 try_to_unmap_one() 函数中,更新引用特定物理页面的所有页表项的操作都是在这个函数中实现的。该函数实现的关键功能如下图所示:
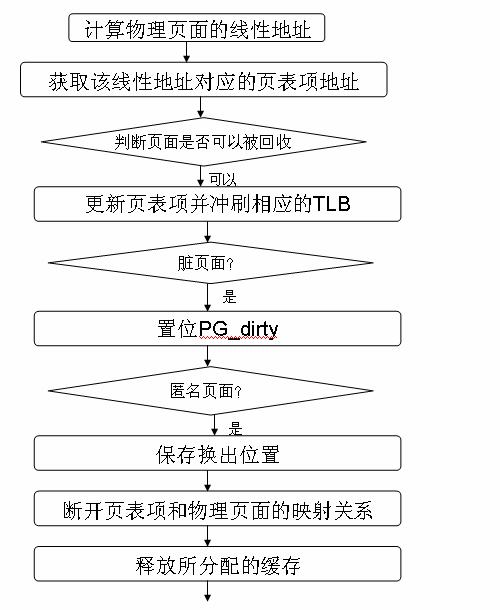
图 7. 函数 try_to_unmap_one() 实现的关键功能
对于给定的物理页面来说,该函数会根据计算出来的线性地址找到对应的页表项地址,并更新页表项。对于匿名页面来说,换出的位置必须要被保存下来,以便于该页面下次被访问的时候可以被换进来。并非所有的页面都是可以被回收的,比如被 mlock() 函数设置过的内存页,或者最近刚被访问过的页面,等等,都是不可以被回收的。一旦遇上这样的页面,该函数会直接跳出执行并返回错误代码。如果涉及到页缓存中的数据,需要设置页缓存中的数据无效,必要的时候还要置位页面标识符以进行数据回写。该函数还会更新相应的一些页面使用计数器,比如前边提到的 _mapcount 字段,还会相应地更新进程拥有的物理页面数目等。
使用反向映射的优缺点
使用反向映射机制所带来的好处是显而易见的:可以快速定为引用了某个物理页面的所有页表项,这极大地方便了操作系统进行页面回收。相对于之前的遍历方法来说,反向映射机制在很大程度上减少了操作系统在页面回收上所占用的 CPU 时间。
但是,使用反向映射所面临的挑战也是很明显的,不管采用上述介绍的哪种方法建立反向映射,都不可避免地要消耗掉一定的内存空间,区别就在于用哪种方法占用的空间会更少,整体性能会更好。
总结
页面回收是 Linux 内存管理中比较复杂的一个部分,涉及到的相关内容非常多,本文也不是面面俱到。反向映射是 Linux 2.5 开发过程中一个比较大的亮点,该技术在后续 Linux 2.6 版本中又得到了更进一步的发展。本文的目的是想帮助读者理清 Linux 2.6 中的页面回收和反向映射机制,本文通过相关的数据结构和关键的代码流程介绍了 Linux 操作系统如何利用反向映射机制有效地进行页面回收。关于 Linux 操作系统如何建立反向映射的内容,本文没有做详尽介绍,感兴趣的读者可以自行参考内核源代码。
原文连接:http://www.ibm.com/developerworks/cn/linux/l-cn-pagerecycle/index.html?ca=drs-
评论暂时关闭