使用strace命令定位和诊断故障的实例分享,strace实例
使用strace命令定位和诊断故障的实例分享,strace实例
这篇文章主要介绍了使用strace命令定位和诊断故障的实例分享,Linux中可以使用strace命令来检查各种错误,需要的朋友可以参考下通过Strace定位故障原因
这是一个Nginx错误日志:
connect() failed (110: Connection timed out) while connecting to upstream
connect() failed (111: Connection refused) while connecting to upstream
看上去是Upstream出了问题,在本例中Upstream就是PHP(版本:5.2.5)。可惜监控不完善,我搞不清楚到底是哪出了问题,无奈之下只好不断重启PHP来缓解故障。
如果每次都手动重启服务无疑是个苦差事,幸运的是可以通过CRON设置每分钟执行:
代码如下:
#/bin/bash</p>
<p>LOAD=$(awk '{print $1}' /proc/loadavg)</p>
<p>if [ $(echo "$LOAD > 100" | bc) = 1 ]; then
/etc/init.d/php-fpm restart
fi
可惜这只是一个权宜之计,要想彻底解决就必须找出故障的真正原因是什么。
闲言碎语不要讲,轮到Strace出场了,统计一下各个系统调用的耗时情况:
代码如下:
shell> strace -c -p $(pgrep -n php-cgi)
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
30.53 0.023554 132 179 brk
14.71 0.011350 140 81 mlock
12.70 0.009798 15 658 16 recvfrom
8.96 0.006910 7 927 read
6.61 0.005097 43 119 accept
5.57 0.004294 4 977 poll
3.13 0.002415 7 359 write
2.82 0.002177 7 311 sendto
2.64 0.002033 2 1201 1 stat
2.27 0.001750 1 2312 gettimeofday
2.11 0.001626 1 1428 rt_sigaction
1.55 0.001199 2 730 fstat
1.29 0.000998 10 100 100 connect
1.03 0.000792 4 178 shutdown
1.00 0.000773 2 492 open
0.93 0.000720 1 711 close
0.49 0.000381 2 238 chdir
0.35 0.000271 3 87 select
0.29 0.000224 1 357 setitimer
0.21 0.000159 2 81 munlock
0.17 0.000133 2 88 getsockopt
0.14 0.000110 1 149 lseek
0.14 0.000106 1 121 mmap
0.11 0.000086 1 121 munmap
0.09 0.000072 0 238 rt_sigprocmask
0.08 0.000063 4 17 lstat
0.07 0.000054 0 313 uname
0.00 0.000000 0 15 1 access
0.00 0.000000 0 100 socket
0.00 0.000000 0 101 setsockopt
0.00 0.000000 0 277 fcntl
------ ----------- ----------- --------- --------- ----------------
100.00 0.077145 13066 118 total
看上去「brk」非常可疑,它竟然耗费了三成的时间,保险起见,单独确认一下:
代码如下:
shell> strace -T -e brk -p $(pgrep -n php-cgi)
brk(0x1f18000) = 0x1f18000 <0.024025>
brk(0x1f58000) = 0x1f58000 <0.015503>
brk(0x1f98000) = 0x1f98000 <0.013037>
brk(0x1fd8000) = 0x1fd8000 <0.000056>
brk(0x2018000) = 0x2018000 <0.012635>
说明:在Strace中和操作花费时间相关的选项有两个,分别是「-r」和「-T」,它们的差别是「-r」表示相对时间,而「-T」表示绝对时间。简单统计可以用「-r」,但是需要注意的是在多任务背景下,CPU随时可能会被切换出去做别的事情,所以相对时间不一定准确,此时最好使用「-T」,在行尾可以看到操作时间,可以发现确实很慢。
在继续定位故障原因前,我们先通过「man brk」来查询一下它的含义:
brk() sets the end of the data segment to the value specified by end_data_segment, when that value is reasonable, the system does have enough memory and the process does not exceed its max data size (see setrlimit(2)).
简单点说就是内存不够用时通过它来申请新内存(data segment),可是为什么呢?
代码如下:
shell> strace -T -p $(pgrep -n php-cgi) 2>&1 | grep -B 10 brk
stat("/path/to/script.php", {...}) = 0 <0.000064>
brk(0x1d9a000) = 0x1d9a000 <0.000067>
brk(0x1dda000) = 0x1dda000 <0.001134>
brk(0x1e1a000) = 0x1e1a000 <0.000065>
brk(0x1e5a000) = 0x1e5a000 <0.012396>
brk(0x1e9a000) = 0x1e9a000 <0.000092>
通过「grep」我们很方便就能获取相关的上下文,反复运行几次,发现每当请求某些PHP脚本时,就会出现若干条耗时的「brk」,而且这些PHP脚本有一个共同的特点,就是非常大,甚至有几百K,为何会出现这么大的PHP脚本?实际上是程序员为了避免数据库操作,把非常庞大的数组变量通过「var_export」持久化到PHP文件中,然后在程序中通过「include」来获取相应的变量,因为变量太大,所以PHP不得不频繁执行「brk」,不幸的是在本例的环境中,此操作比较慢,从而导致处理请求的时间过长,加之PHP进程数有限,于是乎在Nginx上造成请求拥堵,最终导致高负载故障。
下面需要验证一下推断似乎否正确,首先查询一下有哪些地方涉及问题脚本:
代码如下:
shell> find /path -name "*.php" | xargs grep "script.php"
直接把它们都禁用了,看看服务器是否能缓过来,或许大家觉得这太鲁蒙了,但是特殊情况必须做出特殊的决定,不能像个娘们儿似的优柔寡断,没过多久,服务器负载恢复正常,接着再统计一下系统调用的耗时:
代码如下:
shell> strace -c -p $(pgrep -n php-cgi)
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
24.50 0.001521 11 138 2 recvfrom
16.11 0.001000 33 30 accept
7.86 0.000488 8 59 sendto
7.35 0.000456 1 360 rt_sigaction
6.73 0.000418 2 198 poll
5.72 0.000355 1 285 stat
4.54 0.000282 0 573 gettimeofday
4.41 0.000274 7 42 shutdown
4.40 0.000273 2 137 open
3.72 0.000231 1 197 fstat
2.93 0.000182 1 187 close
2.56 0.000159 2 90 setitimer
2.13 0.000132 1 244 read
1.71 0.000106 4 30 munmap
1.16 0.000072 1 60 chdir
1.13 0.000070 4 18 setsockopt
1.05 0.000065 1 100 write
1.05 0.000065 1 64 lseek
0.95 0.000059 1 75 uname
0.00 0.000000 0 30 mmap
0.00 0.000000 0 60 rt_sigprocmask
0.00 0.000000 0 3 2 access
0.00 0.000000 0 9 select
0.00 0.000000 0 20 socket
0.00 0.000000 0 20 20 connect
0.00 0.000000 0 18 getsockopt
0.00 0.000000 0 54 fcntl
0.00 0.000000 0 9 mlock
0.00 0.000000 0 9 munlock
------ ----------- ----------- --------- --------- ----------------
100.00 0.006208 3119 24 total
显而易见,「brk」已经不见了,取而代之的是「recvfrom」和「accept」,不过这些操作本来就是很耗时的,所以可以定位「brk」就是故障的原因。
用 strace 诊断问题
早些年,如果你知道有个 strace 命令,就很牛了,而现在大家基本都知道 strace 了,如果你遇到性能问题求助别人,十有八九会建议你用 strace 挂上去看看,不过当你挂上去了,看着满屏翻滚的字符,却十有八九看不出个所以然。本文通过一个简单的案例,向你展示一下在用 strace 诊断问题时的一些套路。
如下真实案例,如有雷同,实属必然!让我们看一台高负载服务器的 top 结果: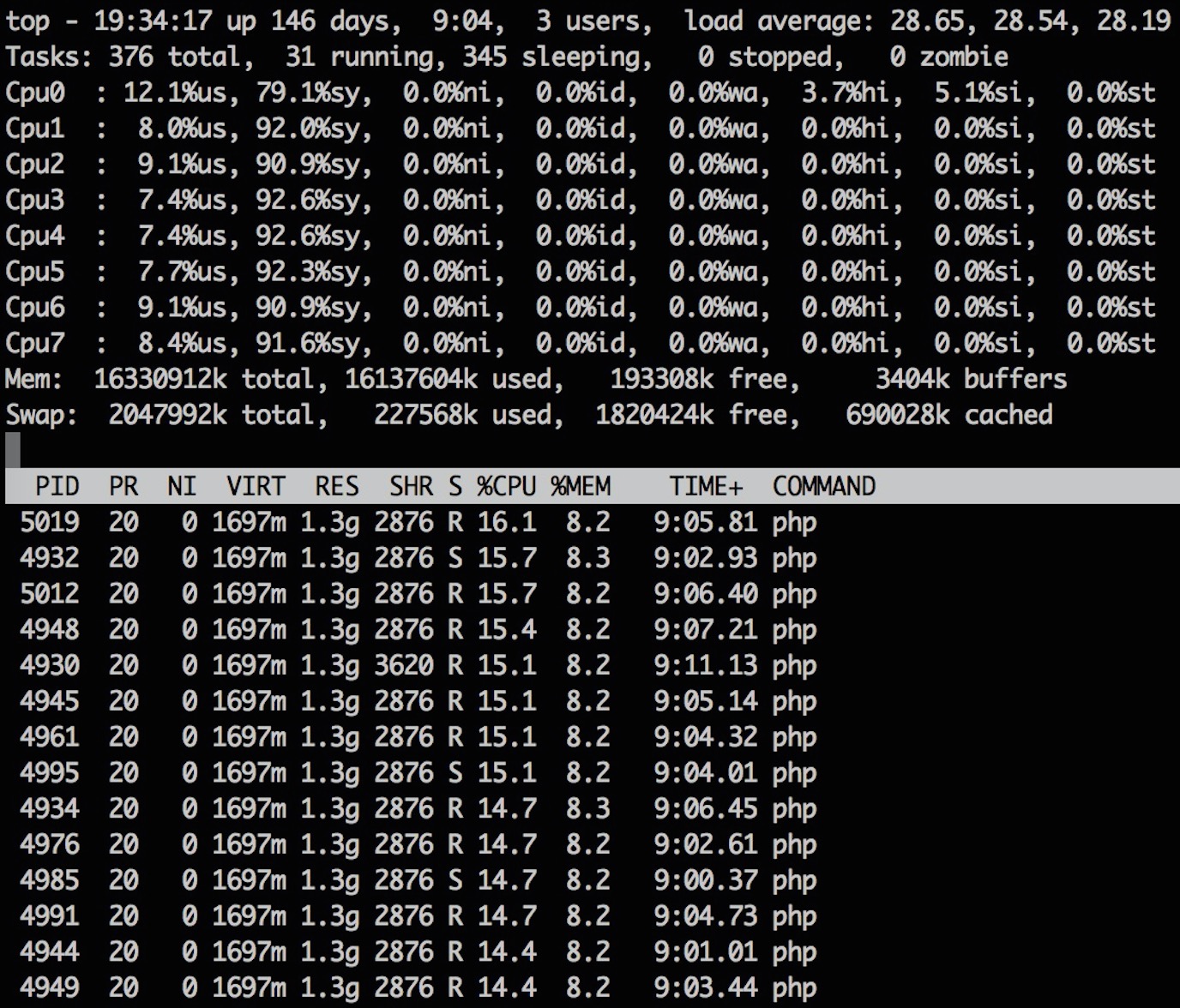
技巧:运行 top 时,按「1」打开 CPU 列表,按「shift+p」以 CPU 排序。
在本例中大家很容易发现 CPU 主要是被若干个 PHP 进程占用了,同时 PHP 进程占用的比较多的内存,不过系统内存尚有结余,SWAP 也不严重,这并不是问题主因。
不过在 CPU 列表中能看到 CPU 主要消耗在内核态「sy」,而不是用户态「us」,和我们的经验不符。Linux 操作系统有很多用来跟踪程序行为的工具,内核态的函数调用跟踪用「strace」,用户态的函数调用跟踪用「ltrace」,所以这里我们应该用「strace」:
代码如下:
shell> strace -p <PID>
不过如果直接用 strace 跟踪某个进程的话,那么等待你的往往是满屏翻滚的字符,想从这里看出问题的症结并不是一件容易的事情,好在 strace 可以按操作汇总时间:
代码如下:
shell> strace -cp <PID>
通过「c」选项用来汇总各个操作的总耗时,运行后的结果大概如下图所示: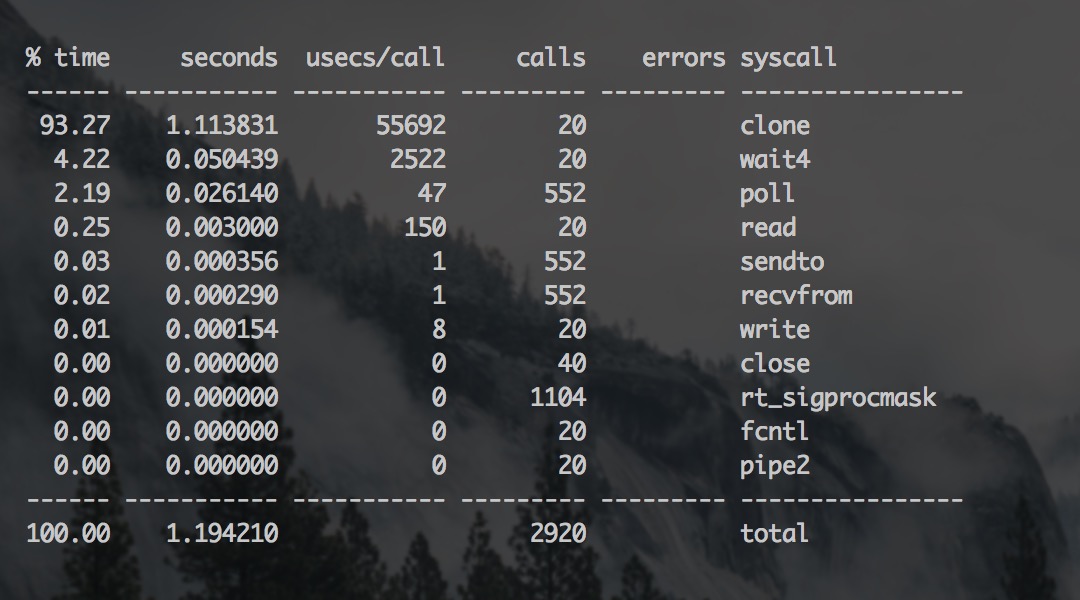
很明显,我们能看到 CPU 主要被 clone 操作消耗了,还可以单独跟踪一下 clone:
代码如下:
shell> strace -T -e clone -p <PID>
通过「T」选项可以获取操作实际消耗的时间,通过「e」选项可以跟踪某个操作: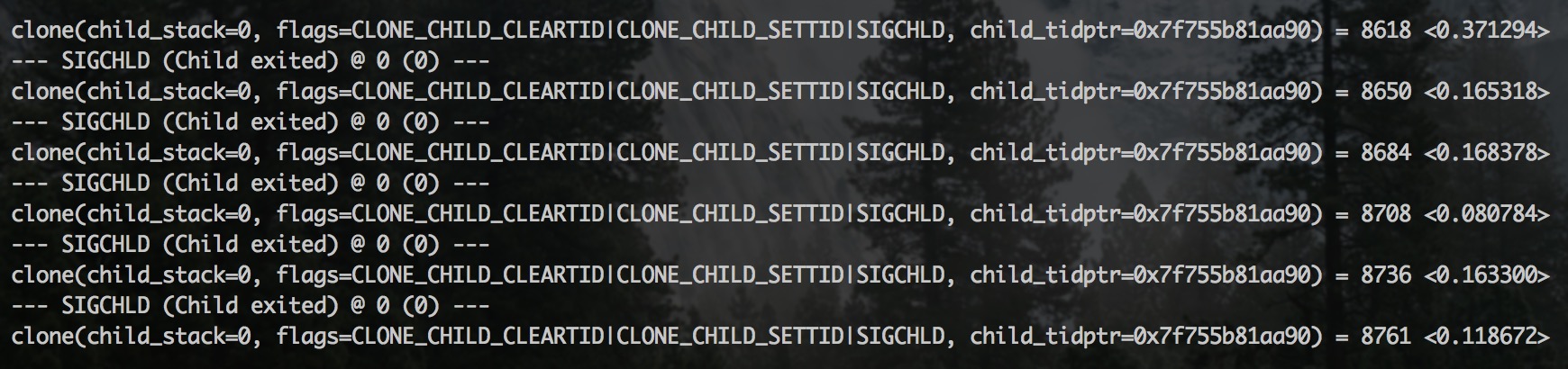
很明显,一个 clone 操作需要几百毫秒,至于 clone 的含义,参考 man 文档:
clone() creates a new process, in a manner similar to fork(2). It is actually a library function layered on top of the underlying clone() system call, hereinafter referred to as sys_clone. A description of sys_clone is given towards the end of this page.
Unlike fork(2), these calls allow the child process to share parts of its execution context with the calling process, such as the memory space, the table of file descriptors, and the table of signal handlers. (Note that on this manual page, “calling process” normally corresponds to “parent process”. But see the description of CLONE_PARENT below.)
简单来说,就是创建一个新进程。那么在 PHP 里什么时候会出现此类系统调用呢?查询业务代码看到了 exec 函数,通过如下命令验证它确实会导致 clone 系统调用:
代码如下:
shell> strace -eclone php -r 'exec("ls");'
最后再考大家一个题:如果我们用 strace 跟踪一个进程,输出结果很少,是不是说明进程很空闲?其实试试 ltrace,可能会发现别有洞天。记住有内核态和用户态之分。
评论暂时关闭