当基础设施故障后,声网SD-RTN™如何保障RTE服务的高可用性,
当基础设施故障后,声网SD-RTN™如何保障RTE服务的高可用性,
云计算的出现为企业的管理、业务开展、资源整合等带来了极大的便利性,也是数字化建设的核心基建之一,然而局部宕机或者大面积宕机事件对于云厂商来说却也无法避免,全球领先的计算平台也不例外。例如,美国东部时间12月7日上午10点45分,亚马逊 AWS 遭遇宕机,导致了迪斯尼+、奈飞等一些网站的在线服务受到影响,此次故障也在业内引发了较大的关注。
之所以说云厂商的宕机故障无法100%避免,核心在于造成的原因有很多种,例如人为失误、网络中断或者区域性网络拥塞、停电、自然灾害等,作为云厂商,能做的就是不断优化技术与服务来应对这些问题,将宕机发生的概率降到最低。
声网作为全球领先的实时互动云服务商,在海外的部分业务也使用了 AWS 的基础设施资源,在AWS 宕机事件中,声网的实时音视频服务并没有受到波及,背后的核心原因在于声网 SD-RTN™大网的独特架构设计保障了 RTE (实时互动)服务的高可用性,做到机房、硬件、网络等基础设施出现故障的情况下,仍然可以给用户提供高可用的 RTE 服务。
首先我们要了解什么是高可用性。一般来讲,一个靠谱的云服务一定是可用性非常高的,可用性的评判标准 SLA:服务等级协议(Service Level Agreement)对于云厂商来说就是服务可用性的一个保证,国内很多云厂商在售卖云服务时都会承诺99.9%的可用性,9越多代表全年服务可用时间越长服务更可靠,反之亦然。例如以全年365天做计算,99.9%的可用性,每年只有8.76小时的服务是不可用的,可用性的每一次提升都是一次技术的挑战,当遇上环境灾害、公网基础设施不可靠等问题时,怎么样快速地面对这些问题,多长时间恢复,是否有成熟的备案这是任何一个云厂商都要诚实面对的问题。
想要提升服务的可用性,需要从多个层面进行布局,例如机房布置、服务基础架构、运维自动化等,那么声网具体是如何在实践中保障RTE服务的高可用性,我们可以从四个层面展开来讲:
一、SD-RTN™架构设计:故障实时感知与智能调度、异地多活
业务架构:众所周知,基础设施会因为突发的网络拥塞、硬件故障、不可抗力等因素导致或大或小的一段时间的不可用。在这样的前提下,声网 SD-RTN™大网的架构师团队从设计之初就充分考虑到了基础设施的不稳定因素。如果要用几个关键词来描述 SD-RTN™,那就是全球覆盖、故障实时感知与智能调度、超低延时、弹性能力、异地多活、超高并发,而一旦基础设施出现故障,SD-RTN™的故障实时感知与智能调度能力以及异地多活的构建方式将发挥重要作用,保障服务的高可用。
1、故障实时感知与智能调度:从全球来看,公网网络的波动是较为频繁的,SD-RTN™的网络嗅探服务能够实时的感知网络的质量,结合AI Ops(智能运维)的分析能力,能够实现分钟级的用户迁移,保障用户的音视频体验。
2、异地多活:SD-RTN™大网将全球资源划分为多个Region(区域),在Region内依然能够做到最低N+3(即:在最大的3个资源集群不可用的情况下,剩余的资源依然能够承接当前Region的负载)资源冗余的要求,不仅如此,Region之间依然能够形成互补的态势,某个Region故障时,可以通过互补Region进行承接。
3、灵活的扩弹性缩容能力:SD-RTN™大网的每个Region至少具备200%的实时弹性扩缩容能力,具备应对突发事件的能力,配合智能调度能够充分合理的进行资源使用。
SDK:同时,在音视频 SDK 侧声网也进行了大量的优化工作,包括抗弱网优化,音视频体验优化等,形成和业务层进行"里应外合"的局面,提升服务的可用性。
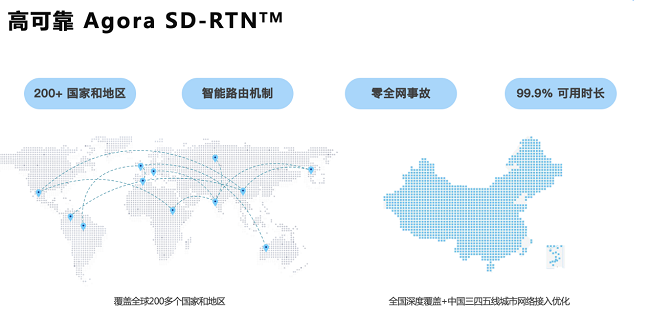
二、基础设施层面:机房全球分布、五地三中心资源覆盖
基础资源选点: SD-RTN™ 在全球部署了250+数据中心,覆盖全球200多个国家与地区,对于主要区域的最低要求是五地三中心的资源覆盖,每个区域采用核心节点+POP点的方式。这样一旦某区域其中一个或两个机房发生故障,依靠技术可以将故障城市的流量全部切换到运行正常的机房。
供应链管理:不依赖单家供应商的基础资源(包括:机房、硬件、网络等),当一家供应商出现问题,可以快速切换到其他服务正常的供应商。
三、智能运维,快速阻断故障
如今行业都有一个共识,即运维复杂度在迅速增加,然而传统运维已经捉襟见肘,为此, 声网投入了巨大的资源和人力,克服了 AI 工程化落地的难点,将智能运维全面应用于 SD-RTN™的日常运维中,解决了传统运维的痛点:7*24H 不间断保障;高一致性和高质量的执行结果;统一高效的运维效率。
声网的 AI Ops(智能运维)能在 1 min之内(包含了数据聚合、上报、判断、执行、恢复等整体端到端时间)识别机房异常并且自动运维,,快速阻断故障影响蔓延, 保障边缘服务高可用。例如,边缘节点的网络拥塞是无法避免的, 在出现拥塞之后, 用户的音视频体验会打折(卡顿, 延时增大),这种情况下经验丰富的运维人员在 daytime 时期从故障发现到处理平均要花费20分钟, 如果故障发生在深夜或者处理不及时, 时间会更长, 这对用户的体验影响很大. 这时候 AI OPS的价值就体现出来了, 它能在2.5分钟之内识别并处理异常, 并且7*24不间断高一致性地执行, 以保障用户高质量的 RTC 体验。
四、RTE行业首个体验质量标准-XLA
前面我们提到,SLA 是很多云厂商与电信行业对服务可用性的评判标准,但在声网看来,SLA 对设备和网络接入标准进行规范,关注的是服务的可用性。但是在 RTE 行业,仅仅达到“可用”标准远远不够,用户渴望的是清晰流畅、没有卡顿的音视频互动,那么在实时互动体验质量上就必须达到“好用”的标准。对此,声网在2020年7月设计定义并推出了实时互动行业首个体验质量标准-XLA (Experience Level Agreement),这也是为 RTE 服务的可用性与体验质量推出的首个可量化、可查证、可赔付的体验质量标准。
与 SLA 不同的是,XLA 不仅关心实时互动的可用性和服务质量,还关注用户的体验质量,同时这也是第一个将质量保证焦点由设备转移到人的标准。XLA 主要包含四项体验指标,即5s登陆成功率、600ms 视频卡顿率、200ms 音频卡顿率和400ms 网络延时达标率,四个指标的月度达标率(1-不达标切片总时长/月度总时长)均需超过 99.5%。5s 登录成功率是指登录成功耗时需小于5秒才算合格,这项指标主要考验实时互动的可用性与等待体验;600ms 视频卡顿率与 200ms 音频卡顿率主要考验实时互动过程中流畅性体验;400ms 的网络延时指标面向音视频互动的实时性,延时需低于 400ms。

通过 XLA,客户可以获得声网对登陆成功率、端到端延时、音视频卡顿率等多个维度的实时互动体验质量承诺和保证,不需要再去担心终端用户的体验质量问题,真正做到用的放心,用的称心!
定义实时互动体验质量标准看似只是几个指标,但实际背后承载了声网团队长期的付出。XLA 质量标准的推出,是经过上百名技术专家针对全链路数据反复打磨、改进、验证,经历了10个版本的反复迭代,适配了50+网络模型、200+国家与地区的优化、6000+不同类型终端体验的优化以及全链路1万亿分钟的数据打磨。这背后代表的也是声网在实时互动云行业的长期深耕与积累。
评论暂时关闭