用Flood测试Web服务器响应时间(1)(2)
设置Flood
Flood通过一个XML格式的设置文件来定义测试中使用的各种参数,我们不妨通过一个形象的比喻也说明一下Flood的工作过程和需要设置的各个方面。首先,Flood使用一个模型profile)来定义一组给定的URL如何被访问,具体的访问由一个或多个农夫(farmer)来进行,而这些农夫又属于一个或多个农场(farm),我们来看一下下面这个示意图:
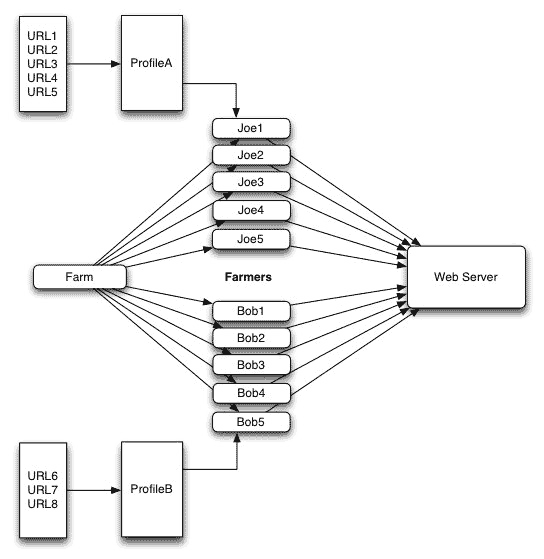 |
如图所示,现在我们使用一个农场,这个农场有两组农夫,其中农夫组Joe使用访问模型A与一个包含五个地址的URL列表,农夫组B使用访问模型B与一个包含三个URL的地址列表,这些家夫直接向WEB服务器请求列表中的地址。Flood使用线程来创建各个农夫,然后比较各个农夫收集到的数据并存入一个单独的文件以便之后做进一步的处理。
XML文件包括了这个测试需要定义的四个方面:URL列表,访问模型,农夫和农场。
URL列表也即一组即将被访问的地址的列表,这些URL地址可以被简单的引用进一步定义特定的请求方法GET,POST,HEAD)。
访问模型定义测试使用哪一个地址列表,它们如何被访问,使用哪一种Socket,收集的信息如何被报告。
农夫负责实际的请求过程,对农夫唯一的可设置选项是使用哪一个访问模型和对一个访问模型的调用次数。每个农夫独立的执行自己的访问模型,但一个访问模型可以执行多次,因此最后的请求过程可能是这样:地址一、地址二、地址一、地址二、……。
对家场的定义涉及到创建农夫的数目和时间,通过增加一个家场创建农夫的数目,可以增加并发请求的数目。并通一些附加的设置,你可以设置一些初始数目的农夫,然后每隔特定的时间增加一定的农夫数量。例如,你可以开始创建两个农夫,然后每5秒钟增加一个农夫,直到农夫数目达到20时停止增加。这可以在一个给定的期间形成一个最大20的并发访问升级过程,然后又逐步将并发请求数降到0。另外也可以模拟这种访问情况,一定数目的访问者长时期的访问一系列页面,并操持最大并发请求数在5-6之间。
注意:到写这篇文章的时候为止,目前的Flood仅支持一个农场,而且它的名子必须是"Bingo",不过,通过为一个农场定义多个农夫,你可以取得同样的基本效果。
通过调节农夫,农场和URL列表的参数,你可以控制总请求数,并发请求数,测试时间基于URL列表,重复次数和农夫的数量可以决定这一点),以及这些请求在整个测试期间的分布,这就允许你针对不同的条件订制你的测试。
在使用Flood进行测试设置时你应该记住的三个基本点是:
●地址列表定义了农夫们将访问的地址
●每个农夫的重复数目定义了一个用户访问你的站点的次数。
●一个农场的农夫数目定义了并发访问用户的数目。
在Flood发行包里的examples目录下有一个样例设置文件,round-robin.xml可能是一个最适合初学者学习的例子,不过本文并不准备就编辑此XML文件的规则或处理产生的数据文件做进一步的解说。
这里,我们主要想讲一下如何针对不同类型的WEB服务器来调整测试的参数。为了便于理解后面的内容,这里我们先看一下使用examples目录下的analyze-relative测试脚本得到的一个结果。在这个例子中,测试对象是一台内部服务器。
Slowest pages on average (worst 5):
Average times (sec)
connect write read close hits URL
0.0022 0.0034 0.0268 0.0280 100 http://test.mcslp.pri/java.html
0.0020 0.0028 0.0183 0.0190 700 http://www.mcslp.pri/
0.0019 0.0033 0.0109 0.0120 100 http://test.mcslp.pri/random.html
0.0022 0.0031 0.0089 0.0107 100 http://test.mcslp.pri/testr.html
0.0019 0.0029 0.0087 0.0096 100 http://test.mcslp.pri/index.html
Requests: 1200 Time: 0.14 Req/Sec: 9454.08
在这里你可以看到测试中进行连接connect),请求write/request),回应read /response),关闭连接close)的平均时间。你也可以对服务器每称处理的请求数目有个基本的印象。
评论暂时关闭