实战:使用MATLAB进行GPU高级编程
实战:使用MATLAB进行GPU高级编程
在GPU上执行能够加快我的应用程序吗?
GPU能够对符合以下标准的应用程序进行加速:
大规模并行—计算能够被分割成上百个或上千个独立的工作单元。
计算密集型—计算消耗的时间显著超过了花费转移数据到GPU内存以及从GPU内存转移出数据的时间。
不满足上述标准的应用程序在GPU上运行时可能会比CPU要慢。
使用MATLAB进行GPU编程
FFT,IFFT以及线性代数运算超过了100个内置的MATLAB函数,通过提供一个类型为GPUArray(由并行计算工具箱提供的特殊数组类型)的输入参数,这些函数就能够直接在GPU上运行。这些启用GPU的函数都是重载的,换句话说,这些函数根据传递的参数类型的不同而执行不同的操作。
例如,以下代码使用FFT算法查找CPU上伪随机数向量的离散傅里叶变换:
A = rand(2^16,1);
B = fft (A);
为在GPU上执行相同的操作,我们首先使用gpuArray命令将数据从MATLAB工作空间转移至GPU设备内存。然后我们能够运行重载函数fft:
A = gpuArray(rand(2^16,1));
B = fft (A);
fft操作在GPU上而不是在CPU上执行,因为输入参数(GPUArray)位于GPU的内存中。
结果B存储在GPU当中。然而,B在MATLAB工作空间中依旧可见。通过运行class(B),我们看到B是一个GPUArray。
class(B)
ans =
parallel.gpu.GPUArray
我们能够使用启用GPU的函数继续对B进行操作。例如,为可视化操作结果,plot命令自动处理GPUArrays。
plot(B);
为将数据返回至本地的MATLAB工作集,你可以使用gather命令。例如
C = gather(B);
C现在是MATLAB中的double,能够被处理double变量的所有MATLAB函数操作。
在这个简单的例子当中,执行单个FFT函数节省的时间通常少于将向量从MATLAB工作集移动到设备内存的时间。一般来说是这样的但是也取决于硬件和阵列规模。数据传输开销可能变得异常显著以至于降低了应用的总体性能,尤其是当你重复地在CPU和GPU之间交换数据,执行相对来说很少的计算密集型操作时。更有效率的方式是当数据处于GPU当中时对数据进行一些操作,只在必要的情况下才将数据返回至CPU。
需要指出的是,和CPU类似,GPU的内存也是有限的。然而,与CPU不同,GPU不能在内存和硬盘之间交换数据。因此,你必须核实你希望保留在GPU当中的数据不会超出内存的限制,尤其是当用到大规模矩阵时。通过运行gpuDevice命令,可以查询GPU卡,获取信息比如名称,总内存以及可用内存。
采用MATLAB解波动方程
为将上述例子应用到具体的环境中,我们在一个实际的问题中实现GPU的功能。计算目标是解二阶波动方程。
当u=0时到达临界值。我们使用基于波谱法的算法解空间方程,使用基于二阶中心有限差分法的算法解时间方程。
波谱法通常用于解决偏微分方程。采用波谱法的解决方案接近连续基函数比如正弦和余弦的线性组合。在这个例子中,我们应用了切比雪夫波谱法,使用切比雪夫多项式作为基函数。
我们在每一个时间步长使用切比雪夫波普法计算当前解决方案的在x象限和y象限的二次导数。我们同时使用这些中间数值与旧的解决方案和新的解决方案,应用二阶中心有限差分法(也称为蛙跳法)计算新的解决方案。我们选择了保持蛙跳法稳定性的时间步长。
MATLAB算法是计算密集型的,当网格中元素的数目超过了计算解决方案的增长,算法的执行时间将显著增加。当在单个CPU上使用2048x2048的网格执行时,完成50个时间步长需要一分多钟。需要指出的是我们计算的时间已经包括了MATLAB内在的多线程性能优势。自从R2007a起,MATLAb的一些函数就支持多线程计算。这些函数自动在多线程上执行,并不需要在代码中显示指定命令去创建线程。
当考虑如何使用并行计算工具箱加速计算时,我们将关注每个时间步长所执行的计算指令代码。图3距离说明了为获取在GPU上运行的算法需要做出的改变。需要指出的是涉及MATLAB操作的计算指令、启用GPU的重载函数可以从并行计算工具箱获取。这些操作包括FFT,IFFT,矩阵乘法,以及各种元素明智(element-wise)操作。因此,我们不必改变算法就能够在GPU执行。只需要在进入每个时间步长计算结果的循环前使用gpuArray将数据转移到GPU当中。
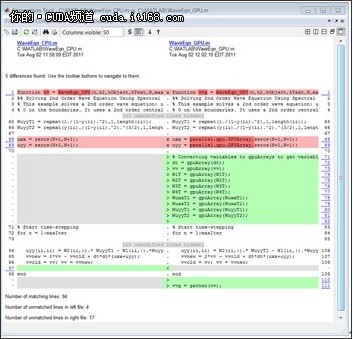
图 3. 代码对比工具显示了CPU版本和GPU版本的差异。
CPU和GPU版本共享的代码超过了84%(在111行当中有94行)。
计算指令在GPU上执行后,我们将计算结果从GPU转移至CPU。被启用GPU的函数所引用的每个变量必须在GPU上创建或者在使用前转移到GPU上。
为将用于光谱分化的一个权重转变为GPUArray变量,我们使用
W1T = gpuArray(W1T);
某些类型的数组能够直接在GPU上构造,不用从MATLAB工作集转移。例如,为直接在GPU上创建全零矩阵,我们使用
uxx = parallel.gpu.GPUArray.zeros(N+1,N+1);
我们使用gather函数将数据从GPU中转移回MATLAB工作集;例如:
vvg = gather(vv);
需要指出的是这只是将一个数据转移至GPU,然后从GPU转移回MATLAB工作集。每个时间步长的所有计算指令都是在GPU上执行的。
评论暂时关闭