HBase学习(十四)LINUX下用Eclipse构建HBase开发环境,eclipsehbase
HBase学习(十四)LINUX下用Eclipse构建HBase开发环境,eclipsehbase
Eclipse,HBase版本目前没有发现需要特别指定
1:从HBase集群中复制一份Hbase部署文件,放置在开发端某一目录下(如在/app/hadoop/hbase096目录下)。
2:在eclipse里新建一个java项目HBase,然后选择项目属性,在Libraries->Add External JARs...,然后选择/app/hadoop/hbase096/lib下相关的JAR包,如果只是测试用的话,就简单一点,将所有的JAR选上。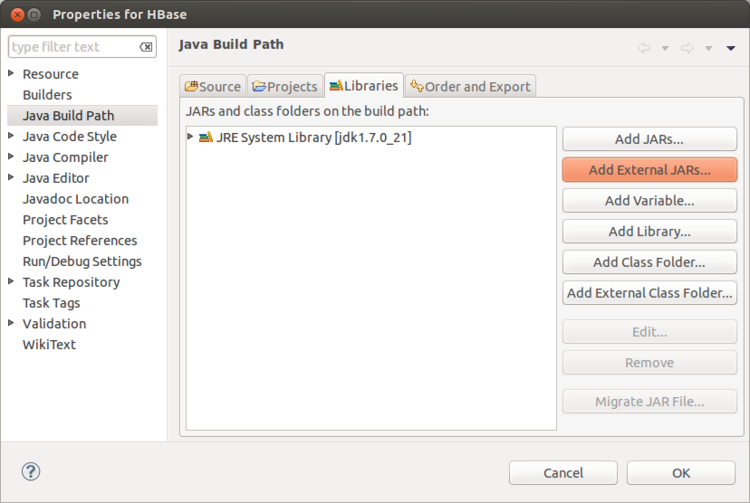
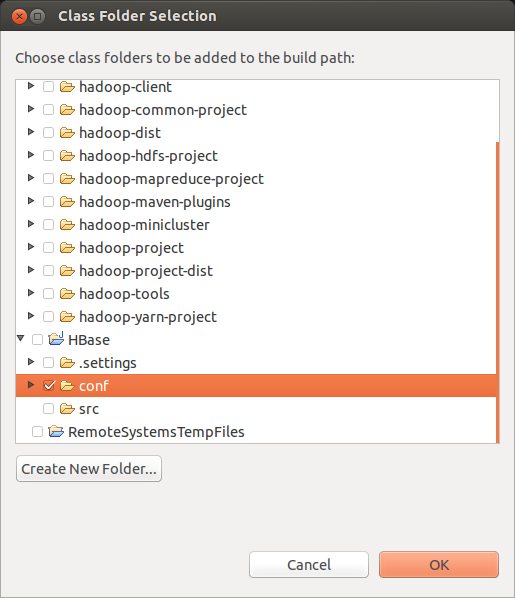
3:在项目HBase下增加一个文件夹conf,将Hbase集群的配置文件hbase-site.xml复制到该目录,然后选择项目属性在Libraries->Add Class Folder,将刚刚增加的conf目录选上。
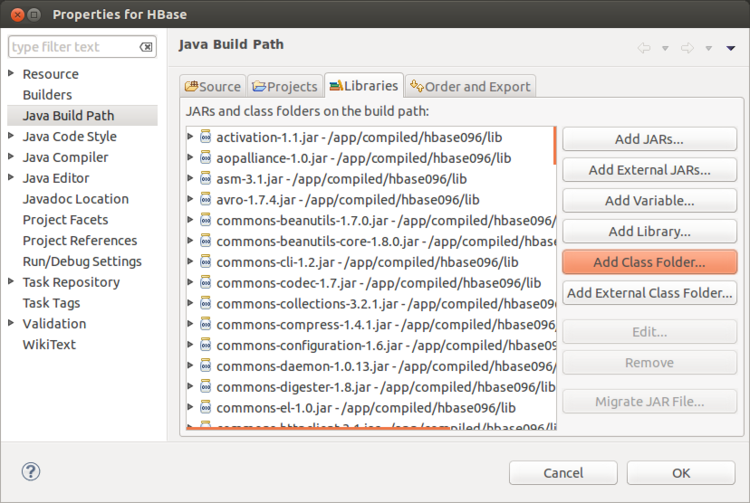
4:在HBase项目中增加一个chapter12的package,然后增加一个HBaseTestCase的class,然后将陆嘉恒老师的《Hadoop实战第2版》12章的代码复制进去,做适当的修改,代码如下:
package chapter12;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseTestCase {
//声明静态配置 HBaseConfiguration
static Configuration cfg=HBaseConfiguration.create();
//创建一张表,通过HBaseAdmin HTableDescriptor来创建
public static void creat(String tablename,String columnFamily) throws Exception {
HBaseAdmin admin = new HBaseAdmin(cfg);
if (admin.tableExists(tablename)) {
System.out.println("table Exists!");
System.exit(0);
}
else{
HTableDescriptor tableDesc = new HTableDescriptor(tablename);
tableDesc.addFamily(new HColumnDescriptor(columnFamily));
admin.createTable(tableDesc);
System.out.println("create table success!");
}
}
//添加一条数据,通过HTable Put为已经存在的表来添加数据
public static void put(String tablename,String row, String columnFamily,String column,String data) throws Exception {
HTable table = new HTable(cfg, tablename);
Put p1=new Put(Bytes.toBytes(row));
p1.add(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(data));
table.put(p1);
System.out.println("put '"+row+"','"+columnFamily+":"+column+"','"+data+"'");
}
public static void get(String tablename,String row) throws IOException{
HTable table=new HTable(cfg,tablename);
Get g=new Get(Bytes.toBytes(row));
Result result=table.get(g);
System.out.println("Get: "+result);
}
//显示所有数据,通过HTable Scan来获取已有表的信息
public static void scan(String tablename) throws Exception{
HTable table = new HTable(cfg, tablename);
Scan s = new Scan();
ResultScanner rs = table.getScanner(s);
for(Result r:rs){
System.out.println("Scan: "+r);
}
}
public static boolean delete(String tablename) throws IOException{
HBaseAdmin admin=new HBaseAdmin(cfg);
if(admin.tableExists(tablename)){
try
{
admin.disableTable(tablename);
admin.deleteTable(tablename);
}catch(Exception ex){
ex.printStackTrace();
return false;
}
}
return true;
}
public static void main (String [] agrs) {
String tablename="hbase_tb";
String columnFamily="cf";
try {
HBaseTestCase.creat(tablename, columnFamily);
HBaseTestCase.put(tablename, "row1", columnFamily, "cl1", "data");
HBaseTestCase.get(tablename, "row1");
HBaseTestCase.scan(tablename);
/* if(true==HBaseTestCase.delete(tablename))
System.out.println("Delete table:"+tablename+"success!");
*/
}
catch (Exception e) {
e.printStackTrace();
}
}
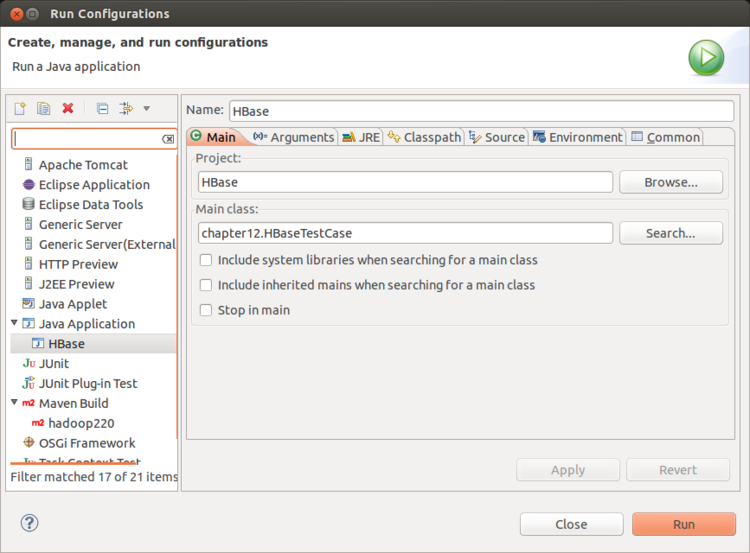
}5:设置运行配置,然后运行。运行前将Hbase集群先启动。
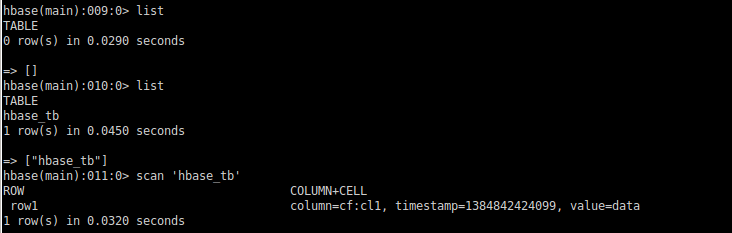
6:检验,使用hbase shell查看hbase,发现已经建立表hbase_tb。
期间自己遇到点问题:
1.引入jar包,有两个包没有读取权限,导致项目出现红色感叹号
2.因为我是虚拟机,每次都要重新启动hadoop和HBase,所以也不要忘了设置hadoop为非安全模式
1.数据查询模式已经确定,且不易改变,就是说hbase使用在某种种特定的情况下,且不能变动。2.告诉插入,大量读取。因为分布式系统对大量数据的存取更具优势。3.尽量少的有数据修改。因为hbase中的数据修改知识在后面添加一行新数据,表示覆盖前一条,大量修改浪费大量空间。(hbase基于hdfs存储不支持修改)以淘宝网为例:淘宝网有一项最近浏览商品的功能,用传统的关系型数据库有以下困难:orderby'耗费性能大;大量数据处理,而且无法分布处理;需要实时看到足迹,无法满足要求,因为数据量太大。而且不能使用缓存技巧(即把一天或者一小时前的数据处理得到结果,写入缓存表,然后给客户,没有时效性)。hbase的优势:有时间戳,适合告诉时间查询;基于行健的查询异常快(行健可参考后面hbase的表结构),特别是最近的数据可能还在memstore里,没有io开销;分布式处理。
是有说不支持的,所以我只是用eclipse写代码,运行还是用的cygwin。
hbase是数据库,可以用也可以不用,支持hadoop比较好只是
评论暂时关闭