分析演示:RIP动态路由协议引发的HSRP收敛问题(1)(6)
第五步:通过制造R1的E1/1故障的现象来验证R2接管故障的事实,如下所示的配置,在路由器R1上切断E1/1接口。
R1(config)#intee1/1
R1(config-if)#shutdown
R1(config-if)#exit
系统提示:跟踪状态E1/1从up转为down。
*Jul 24 11:43:52.967: %TRACKING-5-STATE: 2 interfaceEt1/1 line-protocol Up->Down
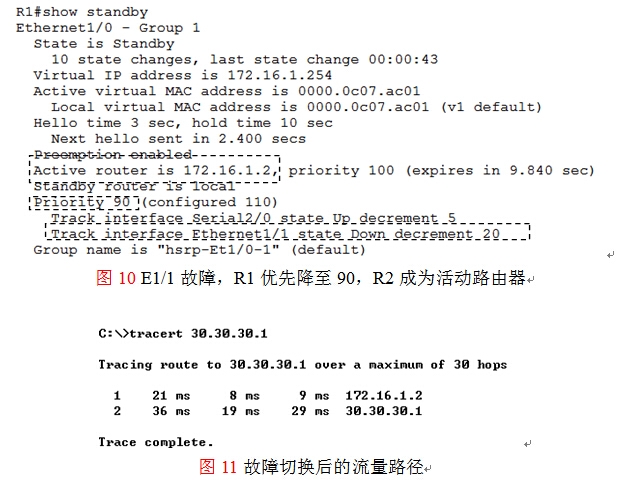
然后在路由器R1上执行show standby查看当前HSRP冗余组的状态,如图10所示,可看到E1/1的状态为down,优先级减少20,当前优先级为90,活动路由器为R2。然后在主机上执行路由跟踪,如图11所示,可看到流量通过R2(172.16.1.2)转发。
动态路由协议RIP引发HSRP的慢收敛问题:
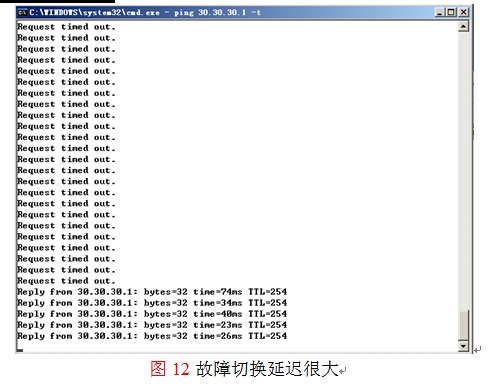
注意在本实验环境的第五步中,当路由器R1的E1/1发生故障,172.16.1.0/24子网的主机在做故障切换时,有部分主机可能会很可能会收敛很慢如图12所示,而另一部则收敛很快,现在需要来理解清楚目标是:
1 哪些主机收敛慢,哪些主机收敛快,这是为什么?
2 是什么原因导致收敛慢?
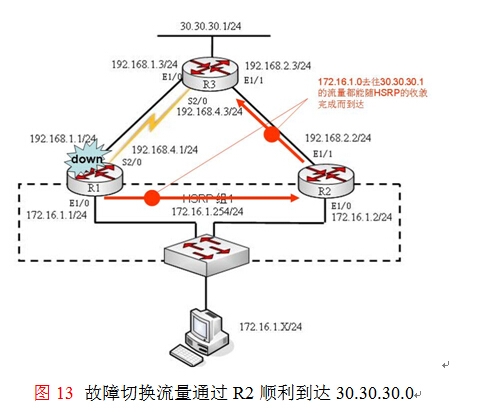
首先来分析当路由器R1的E1/0故障后,由于HSRP的冗余跟踪了该接口所以会立即触发HSRP的故障切换,此时R2会成为HSRP组中的活动路由器,172.16.1.0到30.30.30.0的流量将如图13所示通过R2到达,这是不可质疑的,所以去往30.30.30.0的通信流量很顺利。造成长时间(至少180秒)的收敛的原因主要出现在30.30.30.0返回给172.16.1.0网络的通信过程中。
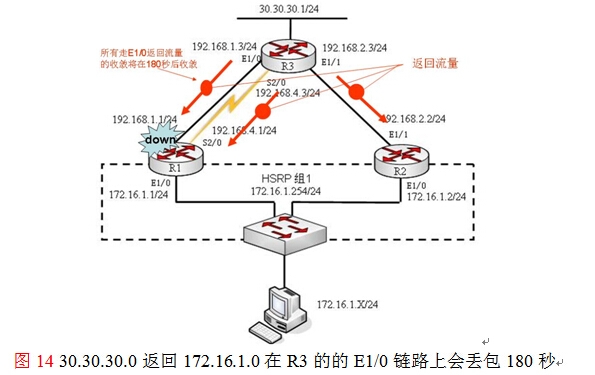
众所周知的一个事实,RIP的收敛一直都是一件非常令人头痛的问题,特别是非本地直连接口故障后,路由表中的相关记录要守侯invalid(无效定时器)超时,默认情况下180S,这条故障的路由才会从路由表中消失,以该本环境为例,当路由器R1的E1/1接口故障,路由器R3的路由表中“172.16.1.0 255.255.255.0 192.168.1.1”这条路由要等待180秒左右,也就是3分钟才会从表中消失,如图15所示,那么在这3分钟左右整个网络将发生什么样的事件呢?
如图14所示,30.30.30.0的返回目标172.16.1.0网络的通信流量时,在180秒内将在三条路径上进行负载均衡,已经故障的链路R3的E1/0,因为“172.16.1.0 255.255.255.0192.168.1.1”这条路由没到180秒,还存在于路由表中,所有只要是通过“172.16.1.0255.255.255.0 192.168.1.1”这条路由返回给目标172.16.1.0的数据都会出现丢包,而且时间在三分钟左右,收敛慢。


评论暂时关闭