分析演示:RIP动态路由协议引发的HSRP收敛问题(1)(7)
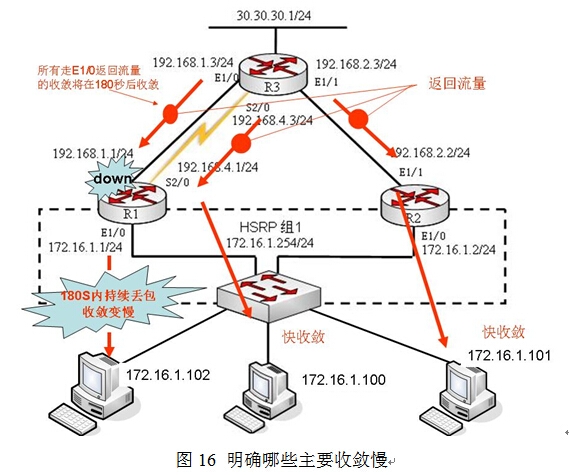
这将进一步引出一个问题:172.16.1.0主机在故障切换的这个过程中,一些主机故障收敛较快,丢包很少,一些主机收敛很慢,会有长达3分钟左右的丢包,关键是哪些主机收敛快,哪些主机收敛慢,这是为什么原因?
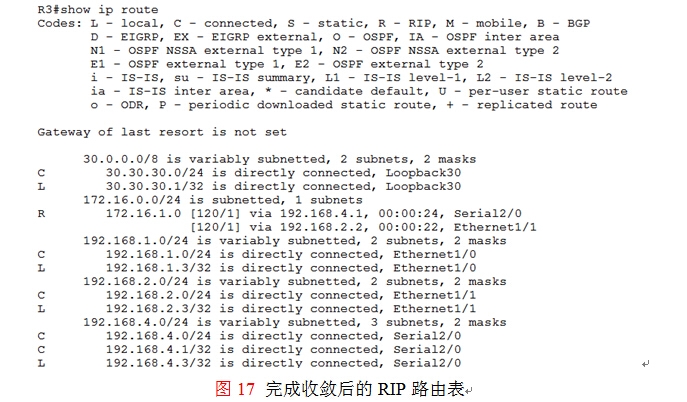
这被R3的ip cef的负载均衡模式所决定,在R3上RIP没有收敛的180秒内, 路由表还维系在如图15所示的状态下,30.30.30.1将仍然使用“172.16.1.0 255.255.255.0192.168.1.1”这条路由来返回流量给172.16.1.0,默认情况下R3的ip cef的负载均衡方式是:如果存在多条路径(本环境中有三条),那么30.30.30.1将根据不同的目标主机来完成负载均衡,为了方便理解,举一实例来说明:如图16所示,当流量从30.30.30.1返回给172.16.1.0网络时,172.16.1.0网络的主机就是目标,那么R3的ip cef决定根据不同的目标主机使用三条路径来完成负载均衡,此时的172.16.1.101、172.16.1.100、172.16.1.102三台主机就是三个不同的目标,如果到目标172.16.1.101使有E1/1返回流量,那么收敛快;如果到目标172.16.1.100使有S2/0返回流量,收敛也快,因为这两条链路都是稳定的不需要RIP作收敛,但是到目标172.16.1.102在180S内就会出现持续的丢包,收敛慢,直到故障路由从R3的路由表中消失,如图17所示,才能顺利完成收敛。当然管理员可以在R3上通过clear iproute *来强制初始化R3的路由表,可以提高收敛的速度,但是这个解决方案过于极端,特别是在工业生产环境中,是不建议这样做的。
通过上述的分析与实验取证,大家应该能够体会到一个事实:往往一个网络现象或者故障并不是某一个技能知识点所引发,它可能是藏于一个知识点的背后,也可能是多个知识点进行集成应用时发生的,建议大家在网络工程领域始终不要以“一个点”的方式来看待发生的问题,应该进行联动分析,综合取证。
以该环境为例,大家看到了矢量路由协议在实战应用环境中的确如各个设备生产商所述的收敛是一个很大的问题,那么在该环境中,来使用静态路由去替代RIP并接合HSRP来完成冗余部署是否会有更好的效果,就本人看来问题更严重,如果不建立预设分析,那么用户将永远不知道将生什么,发生的原因,及如何解决?

评论暂时关闭