HTTP/2 头部压缩技术介绍(1)(2)
技术原理
下面这张截图,取自 Google 的性能专家 Ilya Grigorik 在 Velocity 2015 • SC 会议中分享的「HTTP/2 is here, let's optimize!」,非常直观地描述了 HTTP/2 中头部压缩的原理:

我再用通俗的语言解释下,头部压缩需要在支持 HTTP/2 的浏览器和服务端之间:
维护一份相同的静态字典(Static Table),包含常见的头部名称,以及特别常见的头部名称与值的组合;
维护一份相同的动态字典(Dynamic Table),可以动态的添加内容;
支持基于静态哈夫曼码表的哈夫曼编码(Huffman Coding);
静态字典的作用有两个:1)对于完全匹配的头部键值对,例如 :method :GET,可以直接使用一个字符表示;2)对于头部名称可以匹配的键值对,例如 cookie :xxxxxxx,可以将名称使用一个字符表示。HTTP/2 中的静态字典如下(以下只截取了部分):
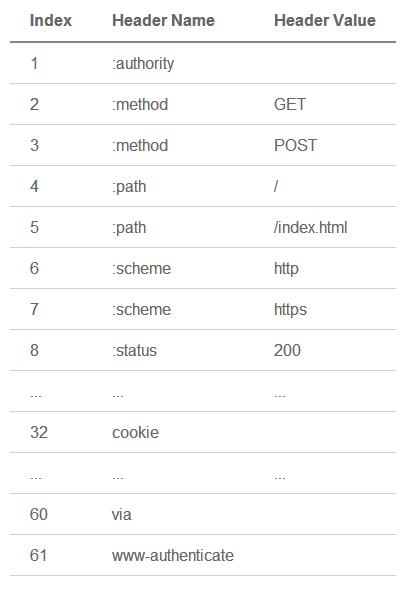
同时,浏览器可以告知服务端,将 cookie :xxxxxxx 添加到动态字典中,这样后续整个键值对就可以使用一个字符表示了。类似的,服务端也可以更新对方的动态字典。需要注意的是,动态字典上下文有关,需要为每个 HTTP/2 连接维护不同的字典。
使用字典可以极大地提升压缩效果,其中静态字典在首次请求中就可以使用。对于静态、动态字典中不存在的内容,还可以使用哈夫曼编码来减小体积。HTTP/2 使用了一份静态哈夫曼码表(详见),也需要内置在客户端和服务端之中。
这里顺便说一下,HTTP/1 的状态行信息(Method、Path、Status 等),在 HTTP/2 中被拆成键值对放入头部(冒号开头的那些),同样可以享受到字典和哈夫曼压缩。另外,HTTP/2 中所有头部名称必须小写。
实现细节
了解了 HTTP/2 头部压缩的基本原理,最后我们来看一下具体的实现细节。HTTP/2 的头部键值对有以下这些情况:
1)整个头部键值对都在字典中
- 0 1 2 3 4 5 6 7
- +---+---+---+---+---+---+---+---+
- | 1 | Index (7+) |
- +---+---------------------------+
这是最简单的情况,使用一个字节就可以表示这个头部了,最左一位固定为 1,之后七位存放键值对在静态或动态字典中的索引。例如下图中,头部索引值为 2(0000010),在静态字典中查询可得 :method :GET。


评论暂时关闭