极简介绍Zookeeper,我想跟你聊这些!,
极简介绍Zookeeper,我想跟你聊这些!,

大家好,我是冰河~~
从今天开始,我们正式更新专题内容,首先我们对Zookeeper的基础内容做下简单的回顾和总结。本文的总体内容如下。

什么是Zookeeper?
简单来说,Zookeeper是一个开源的分布式协同服务系统,Zookeeper的设计目标就是把复杂并且容易出错的分布式协同服务进行封装,并抽象出一个高效可靠的原语接口,并对外提供一系列简单的接口为其他服务调用。其他应用只要使用Zookeeper提供的接口,就可以实现各种分布式应用。例如:分布式锁、分布式选举,主从切换等等。这些案例我们在实战内容中会详细说明。
Zookeeper发展史
Zoookeeper最早是雅虎为了解决内部多个系统之间的协同问题而研发的,后来将其开源并捐赠给了Apache组织。后来Zookeeper在开源界被广泛使用。这里,我列举几个使用了Zookeeper的著名的开源项目。
- Hadoop:使用Zookeeper来提供NameNode的高可用机制。
- HBase:使用Zookeeper来保证整个集群中只有一个Master节点,保存集群中的RegionServer列表,保存hbase:meta表的位置。
- Kafka:使用Zookeeper来对进群中的成员进行管理,并使用Zookeeper提供controller节点的选举机制。
- Dubbo:使用Zookeeper来实现分布式治理服务的注册中心。
- SpringCloud:使用Zookeeper来实现微服务注册中心。
还有很多使用Zookeeper作为分布式协同的开源项目,由于数量比较多,这里就不一一列举了,小伙伴们可以自行通过网络查阅。
Zookeeper应用场景
简单点说,Zookeeper可以应用于以下场景当中。
- 配置管理。
- DNS服务。
- 组成员管理。
- 各种分布式锁。
- 分布式选举。
- 数据一致性场景。
但是,需要注意的是:Zookeeper只适合于存储和协同相关的关键数据,不适合用来存储大数据量的数据。
Zookeeper服务的使用
一般情况下,我们在使用Zookeeper时,是通过Zookeeper库来连接并使用Zookeeper的,由Zookeeper客户端负责和Zookeeper集群进行交互。

Zookeeper的数据模型
从本质上讲,Zookeeper的数据模型是层次模型,如下所示。
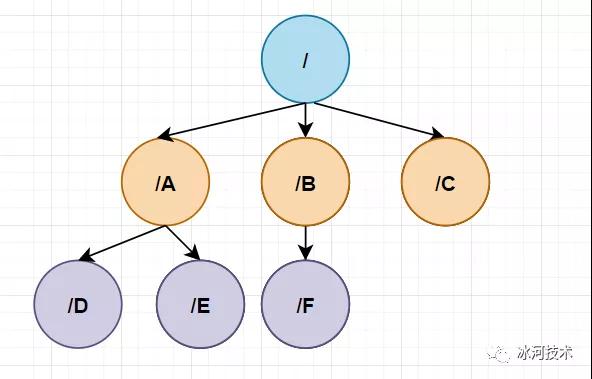
这种层次模型常见于文件系统,而这种层次模型和Key-Value模型是两种主流的数据模型。Zookeeper使用文件系统模型主要的考虑点如下。
- 文件系统的树形结构便于表达数据之间的层次关系。
- 文件系统的树形结构便于为不同的应用分配独立的命名空间。
在Zookeeper中,层次结构的每个节点叫做znode,它不同于文件系统,每个节点都可以保存数据,而且每个节点都有一个版本号,版本号从0开始递增计数。
接下来,我们再来看一个Zookeeper节点的具体示例。
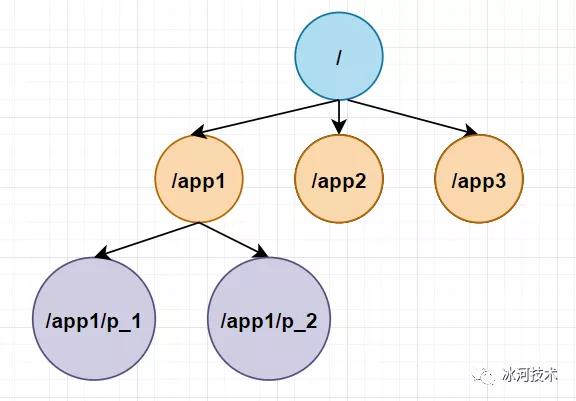
例如,上图中有三个子树,三个子树分别应用于app1、app2和app3三个应用。其中app1的子树实现了一个简单的组成员协议,也就是每个客户端进行p创建一个znode在/app1节点下,而且每个进程创建的znode是以/app1/p_1,/app1/p_2,...,/app1/p_n 这种结构依次存放。只要 /app1/p_n 节点存在,就说明Pn进程在正常的运行。
Zookeeper的节点分类
总体来说,Znode节点可以分为以下四类。

一个Znode节点可以是持久性的,也可以是临时性的。
持久性的Znode:创建节点后即使Zookeeper集群宕机,或者Zookeeper客户端宕机,节点也不会丢失。
临时性的Znode:Zookeeper客户端宕机或者客户端在指定的超时时间内没有给Zookeeper集群发送消息,那么这个节点就会消失。
Znode节点也可以是顺序性的,所谓的顺序性,就是指每个节点会关联一个唯一的单调递增整数,这个单调递增的整数就是Znode节点名称的后缀,比如:/app1/p_1,/app1/p_2等,由此,Znode又有如下两种分类:
持久顺序性的Znode:除了具备持久性的Znode的特性之外,Znode的名称还具备顺序性。
临时顺序性的Znode:除了具备临时性的Znode的特性之外,Znode的名称还具备顺序性。
评论暂时关闭