3.awk数组详解及企业实战案例,3.awk数组实战案例
3.awk数组详解及企业实战案例,3.awk数组实战案例
awk数组详解及企业实战案例
3.打印数组:[root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]="zhuzhu";for(key in array) print key,array[key]}'1 zhurui2 zhuzhu[root@nfs-server test]#
[root@nfs-server test]# awk 'BEGIN{array[1]="zhurui";array[2]="zhuzhu";}END {for(key in array) print key,array[key]}'/etc/hosts1 zhurui2 zhuzhu
把文件内容第一列作为下标,第二列作为值,放入数组然后输出。[root@nfs-server test]# cat t3.log1 zhurui2 zhuzhu[root@nfs-server test]# awk 'BENGIN{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log[root@nfs-server test]# awk '{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log1 zhurui2 zhuzhu
 4、脚本:
4、脚本:
#!/bin/awkBEGIN{array[1]="zhurui"array[2]="zhuzhu"for(key in array)print key,array[key];}
[root@nfs-server test]# awk -f t2.awk1 zhurui2 zhuzhu[root@nfs-server test]#
[root@nfs-server test]# cat t3.log1 zhurui2 zhuzhu[root@nfs-server test]# awk 'BENGIN{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log[root@nfs-server test]# awk '{S[$1]=$2;}END{for(k in S) print k,S[k]}' t3.log1 zhurui2 zhuzhu
http://post.judong.org/index.html http://mp3.judong.org/index.html
http://www.judong.org/3.html http://post.judong.org/2.html
[root@nfs-server test]# awk -F "/"'{S[$3]=S[$3]+1;}END{for(k in S) print k,S[k]}' test.logmp3.judong.org 1post.judong.org 2www.judong.org 3
[root@nfs-server test]# awk -F "/"'{S[$3]++}END{for(k in S) print k,S[k]}' test.log|sort -rn -k2|headwww.judong.org 3post.judong.org 2mp3.judong.org 1[root@nfs-server test]#
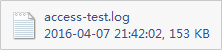
对于统计访问连接IP个数的答案为:
[root@nfs-server test]# awk -F " "'{S[$1]=S[$1]+1;}END{for (k in S) print k,S[k]}' access-test.log|sort -rn|head ##此方法较复杂10.0.0.377510.0.0.132210.0.0.124510.0.0.120210.0.0.108210.0.0.1001[root@nfs-server test]# awk -F " "'{S[$1]++;}END{for (k in S) print k,S[k]}' access-test.log|sort -rn|head ##上一步的简化版10.0.0.377510.0.0.132210.0.0.124510.0.0.120210.0.0.108210.0.0.1001[root@nfs-server test]# awk -F " "'{Z[$1]++;}END{for (k in Z) print k,Z[k]}' access-test.log|sort -rn|head10.0.0.377510.0.0.132210.0.0.124510.0.0.120210.0.0.108210.0.0.1001
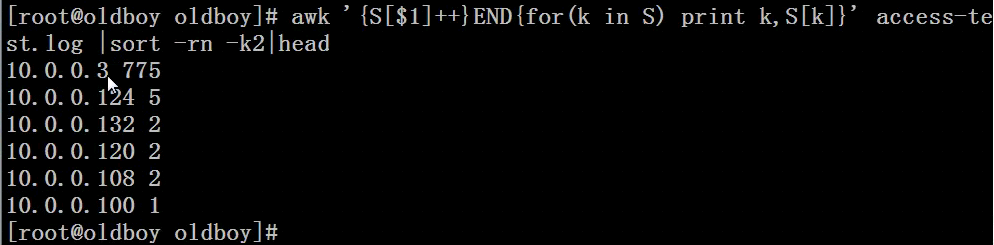 方法2:
方法2:
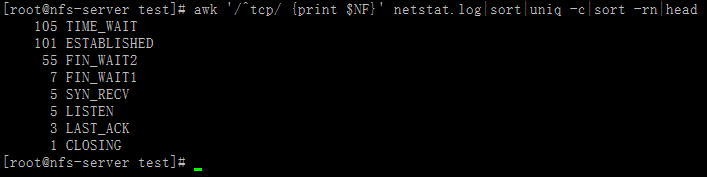
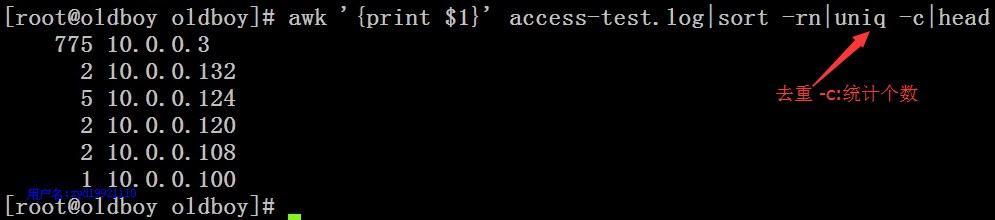 例4:统计企业工作中高并发linux服务器不同网络连接状态对应的数量
例4:统计企业工作中高并发linux服务器不同网络连接状态对应的数量

方法1:
[root@nfs-server test]# awk '/^tcp/ {S[$NF]++}END{for(k in S) print S[k],k}' netstat.log|sort -rn|head105 TIME_WAIT101 ESTABLISHED55 FIN_WAIT27 FIN_WAIT15 SYN_RECV5 LISTEN3 LAST_ACK1 CLOSING[root@nfs-server test]#
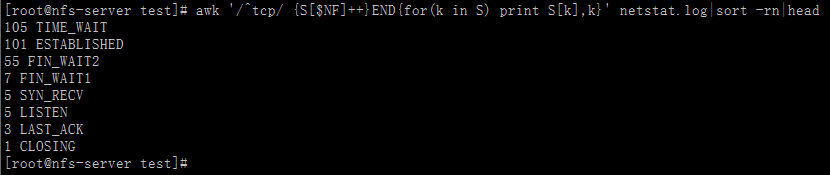 方法2:
方法2:
[root@nfs-server test]# awk '/^tcp/ {print $NF}' netstat.log|sort|uniq -c|sort -rn|head105 TIME_WAIT101 ESTABLISHED55 FIN_WAIT27 FIN_WAIT15 SYN_RECV5 LISTEN3 LAST_ACK1 CLOSING[root@nfs-server test]#
 例5:
分析图片服务日志,把日志(每个图片访问次数*图片大小的总和)排行,取top10,也就是计算每个url的总访问大小
例5:
分析图片服务日志,把日志(每个图片访问次数*图片大小的总和)排行,取top10,也就是计算每个url的总访问大小
说明:范例7的生产环境应用:这个功能可以用于IDC及CDN网站流量带宽很高,然后通过分析服务器日志哪些元素占用流量过大,进而进行优化裁剪该图片(见老男孩发布的《淘宝的双十一超大流量应对文章点评》),压缩js等措施。
本题需要输出三个指标: 【访问次数】 【访问次数*单个文件大小】 【文件名(可以带URL)】
解答:
测试数据
59.33.26.105 - - [08/Dec/2010:15:43:56 +0800] "GET /static/images/photos/2.jpg HTTP/1.1" 200 11299"http://oldboy.blog.51cto.com/static/web/column/17/index.shtml?courseId=43" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
59.33.26.105 - - [08/Dec/2010:15:43:56 +0800] "GET /static/images/photos/2.jpg HTTP/1.1" 200 11299"http://oldboy.blog.51cto.com/static/web/column/17/index.shtml?courseId=43" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
59.33.26.105 - - [08/Dec/2010:15:44:02 +0800] "GET /static/flex/vedioLoading.swf HTTP/1.1" 200 3583"http://oldboy.blog.51cto.com/static/flex/AdobeVideoPlayer.swf?width=590&height=328&url=/[[DYNAMIC]]/2" "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)"
124.115.4.18 - - [08/Dec/2010:15:44:15 +0800] "GET /?= HTTP/1.1" 200 46232 "-" "-"
124.115.4.18 - - [08/Dec/2010:15:44:25 +0800] "GET /static/js/web_js.js HTTP/1.1" 200 4460 "-" "-"
124.115.4.18 - - [08/Dec/2010:15:44:25 +0800] "GET /static/js/jquery.lazyload.js HTTP/1.1" 200 1627 "-" "-"
法一:通过两个数组来计算
因为我们要的最终结果是某个文件的访问次数和消耗的流量,所以考虑建立以文件名为索引的两个数组,一个存储访问次数,一个保存消耗的流量,这样当使用awk按行遍历文件时,对次数数组+1,同时对流量数组进行文件大小的累加,等文件扫描完成,再遍历输出两个数组既可以得到该文件的反问次数和总的流量消耗。
[root@locatest scripts]# awk '{array_num[$7]++;array_size[$7]+=$10}END{for(x in array_num){print array_size[x],array_num[x],x}}' access_2010-12-8.log |sort -rn -k1|head -10 >1.log
法二:
[root@locatest scripts]# awk '{print $7"\t" $10}' access_2010-12-8.log|awk '{S[$1]+=$2;S1[$1]+=1}END{for(i in S) print S[i],S1[i],i}'|sort -rn|head -10 >2.log
[root@locatest scripts]# diff 1.log 2.log
[root@locatest scripts]# cat 1.log
57254 1 /static/js/jquery-jquery-1.3.2.min.js
46232 1 /?=
44286 1 //back/upload/course/2010-10-25-23-48-59-048-18.jpg
33897 3 /static/images/photos/2.jpg
11809 1 /back/upload/teacher/2010-08-30-13-57-43-06210.jpg
10850 1 /back/upload/teacher/2010-08-06-11-39-59-0469.jpg
6417 1 /static/js/addToCart.js
4460 1 /static/js/web_js.js
3583 2 /static/flex/vedioLoading.swf
2686 1 /static/js/default.js
评论暂时关闭