服务器为什么这么慢?耗尽了CPU、RAM和磁盘I/O资源,耗尽ram
服务器为什么这么慢?耗尽了CPU、RAM和磁盘I/O资源,耗尽ram
机器运行缓慢通常是由于消耗了太多系统特定的资源。系统的主要资源包括CPU、RAM、磁盘I/O以及网络。过度使用这些资源的任何一种都会让系统陷入困境。不过,如果能登录到系统之中,可以借助大量工具确定问题的起因。
1.系统负载
解决引起系统运行缓慢的问题时,平均系统负载可能是最先用到的基本度量标准。
最常用的命令是uptime:

load average 后面的3个数字2.03、30.17 和 15.09分别代表了1分钟、5分钟和15分钟内机器的平均负载。一个系统的平均负载等于处于运行或者不可打扰状态进程的平均数。
平均负载为1的单CPU系统意味着这个CPU处于恒定负载。如果单CPU系统的平均负载是4,那么这个系统处于它可承受负载能力的4倍,所以3/4的进程都在等待资源。负载状态为1的单CPU系统与负载状态为4的四CPU系统使用资源的量一样。

这个例子中,5分钟内和15分钟内的平均负载都很低,但是1分钟内的平均负载却很高,所以知道负载的飙升相对而言发生在最近。通常我们会连续运行多次uptime命令(或者使用top命令)来观察负载是持续上升还是正在下降。
什么是高平均负载:
这取决于产生高负载的原因。因为负载描述了正在使用资源的活动进程的平均数量,所以负载的飙升透露了很多信息。明确负载是CPU密集型(等待CPU资源的进程)、RAM密集型(尤其是,频繁使用的RAM被移入了交换区)还是I/O密集型(争夺磁盘或网络I/O资源的进程)非常重要。
通常CPU密集型的系统会比I/O密集型的系统响应度更高。我见过数以白计CPU密集型的系统,仍然可以在这些系统上运行故障排除工具而且具有良好的响应时间。I/O负载相对较低的I/O密集型系统,只是登录系统就需要花费一段时间,因为它们的磁盘I/O完全饱和了。用尽RAM资源的系统通常与I/O密集型的系统表现相同,因为一旦系统开始使用磁盘上的交换存储,它就会消耗磁盘资源,导致进程逐渐变慢直至停止。
2.使用top命令解决负载问题
当需要解决高负载问题的时候,第一个想到的工具是top命令。你能看到系统的实时信息,包括系统启动了多久、负载平均值、系统中总共有多少进程在运行、总共有多少内存、使用了多少内存、还剩多少内存,最后还包含系统的进程列表以及它们占用的资源数量。top命令默认排序方式是按照进程的CPU使用情况从上到下排序,可以一眼就看到那些进程正在消耗CPU资源。
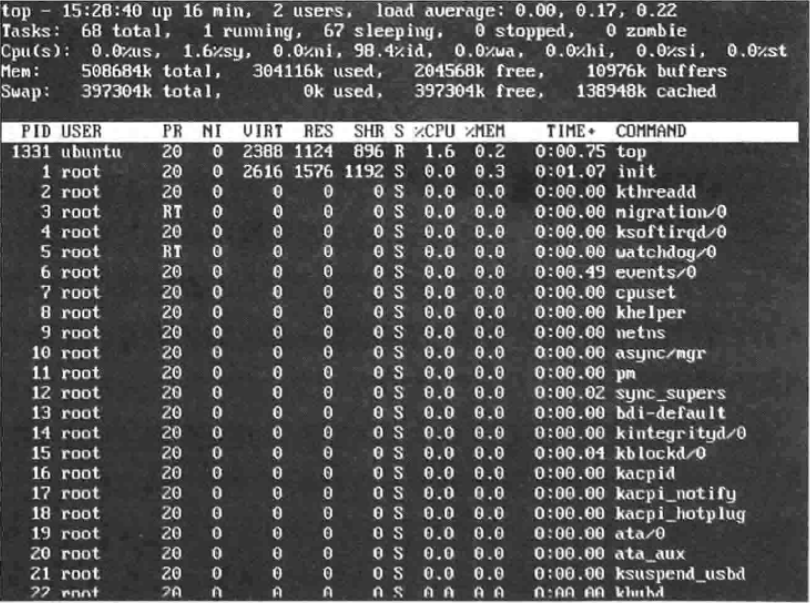
终止进程:
top命令输出的第一列是PID,想要终止某个进程,只需按下K键,然后输入想要终止的PID,最后系统提示该进程将会终止与signal 15时,按下Enter键即可。
完整输出:
默认情况top命令是在非交互模式下,如果想看到top命令的完整输出,或将信息重定向到文件中,-b选项可以开启批处理模式,-n选项可以控制在退出top命令之前,刷新信息多少次。
查看完整的输出,仅需运行一次top命令:
top -b -n 1
将信息存储到名为top_output文件中:
top -b -n 1 > top_output
如果想看top命令的输出,同时将该输出写入文件,那么可以使用tee工具:
top -b -n 1 | tee top_output
2.1了解top命令的输出
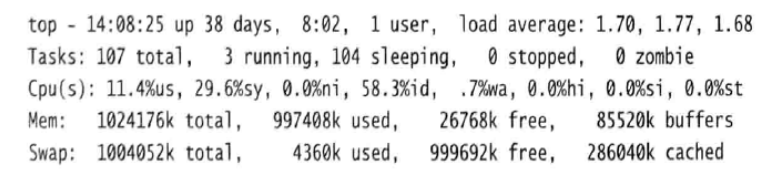
top命令输出的第一行与之前见到的uptime命令输出一致。

top命令提供了额外的度量标准。例如,Cpu(s)这一行提供了当前CPU运行情况的信息。
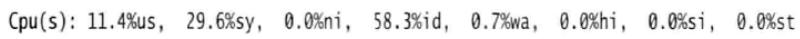
缩写代表的意义:
us:用户CPU时间
运行非优雅的用户进程所占CPU时间的百分比(优雅,英文“nicing”,是指一个进程允许你根据其他进程更改优先级)。
sy:系统CPU时间
运行内核和内核进程所占CPU时间的百分比。
ni:优雅CPU时间
如果更改过一些进程的优先级,这个指标能够告诉你它们所占CPU时间的百分比。
id:CPU空闲时间
这是你希望具备很高数值的度量指标中的一个。它代表了CPU的空闲时间比。如果系统运行缓慢,但是这个指标特别高,那么你就可以确定问题的原因不是高CPU负载。
wa:I/O等待
这个数字代表了CPU时间用在等待执行I/O操作所占的百分比。当你解决运行缓慢的系统问题的时候,这是一个非常有价值的度量指标,如果这个数值很低,那么就能轻松排除磁盘或者网络I/O的问题。
hi:硬件中断
CPU用于处理硬件中断所占时间的百分比。
si:软件中断
CPU用于处理软件中断所占时间的百分比。
st:流逝的时间
如果你正在运行虚拟机,这个度量指标会告诉你虚拟机中执行的其他任务所占CPU时间的百分比。
从以上例子中,可以看出系统有超过50%的空闲时间,这与机器具备4个CPU、系统负载为1.70的指标项匹配。当处理一个运行缓慢的系统的时候,首先要观察的度量指标之一就是I/O等待时间,它可以用来排除磁盘I/O的问题,如果I/O等待时间很低,那么可以看看CPU空闲时间百分比;如果I/O等待时间很高,那么下一步就是确定是什么因素导致I/O等待时间所占的比重这么高。如果I/O等待和CPU空闲时间百分比都很低,那么狠可能会看到一个非常高的用户时间百分比,所以必须确定是什么原因导致了这么高的用户时间百分比。如果I/O等待时间所占百分比很低,而空闲时间百分比很高,就知道系统运行缓慢不是CPU资源的原因,而应该从别的地方找原因。这可能意味着应该查看网络问题或web服务器的问题,或查看MySQL查询缓慢的问题等。
2.2 解决高用户时间的问题
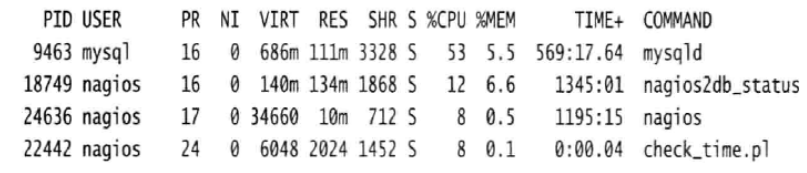
解决故障的过程中一个常见而又相对简单的问题是,由用户CPU时间百分比高引起的高负载问题。如果发现用户时间百分比高但I/O等待时间百分比却很低,很显然你需要确定系统中哪一个进程占用了大量的CPU资源。默认情况,top会按照各个进程CPU使用率由高到低排序。
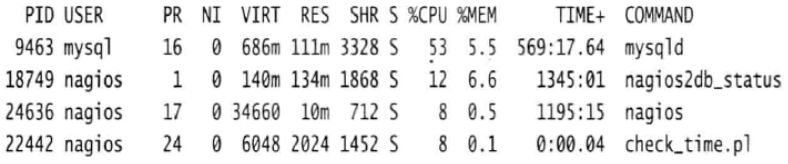
这个例子中,mysqld进程消耗了53%的CPU时间,nagios2db_status进程消耗了12%的CPU时间。这个数字代表的是锁占单个CPU的百分比,如果拥有一台具备4个CPU的机器,可能会看到多个进程都消耗了99%的CPU时间。
通常情况下很容易确定,top命令输出中前一两个进程都是非常高的CPU百分比,而其余进程所占CPU百分比相对很低,此时解决方法就是终止大量使用CPU资源的进程(按K键,然后输入对应进程的PID)。
在多进程的情况下,如果让系统做了太多事。比如,在Web服务器中可能有大量Apache进程,还有cron中运行的部分日志解析脚本。这些进程会消耗差不多等量的CPU资源。这种问题的解决方案从长期来看相当复杂。以Web服务器为例,你的确需要运行全部Apache进程,同时你可能还需要日志解析工具。在短期内,你可以终止(或推迟)一些进程直到负载降低,但从长期来看,你可能需要考虑增加系统资源或将这些功能分拆到多台服务器上。
2.3解决内存不足的问题
top输出中以下两行提供了非常有价值的RAM使用情况的信息。在处理特定的系统问题之前,排除内存问题非常重要。
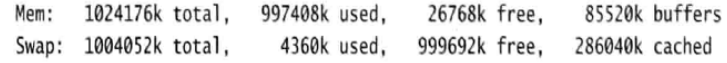
第1行告诉我们有多少物理内存可用、占用了多少内存、空闲内存以及缓存了多少内存。第2行为我们提供了相似的信息,交换存储以及Linux文件缓存使用了多少RAM。需要注意得是系统仅显示26768KB空闲内存。
想找出进程到底使用了多少RAM,必须刨除RAM中的文件缓存。在已用的997408KB的RAM中,有286040KB的RAM被文件缓存占用,所以说实际上仅使用了711368KB的RAM。在这个例子中,系统仍然有大量可用的内存资源,几乎没有使用任何交换存储。即便看到使用了一些交换存储,这也不足以作为问题的征兆。如果一个进程转为空闲状态,Linux通常会将它占用的RAM释放,供其他进程使用。辨别是否耗尽了RAM的一个好方法是查看文件缓存。如果实际用的内存减去文件缓存的值很大,同时交换存储的值也很高,很可能的确有内存问题。
如果发现了内存问题,下一步就是确定哪些进程消耗了RAM。top默认按照CPU的使用率排序,所以你需要将其改为按照RAM使用率来排序,保持top的打开状态,然后按下M键。这就会让所有进程按照RAM的使用率排序。


注意%MEM这一列,会看到前几个进程占用了大量RAM。如果找到大量使用RAM的进程,可以终止它们,或者根据程序,通过专门的故障排除方法来寻找是什么原因导致这些进程占用了大量RAM。
注意:
实际上top命令的输出可以根据任何列排序。想要更改top输出的排序方式,按F键进入选择排序列的界面。在按下对应特定列的按键之后(比如,K对应CPU列),再按Enter键就能回到top的输出界面。
Linux内核也有一个内存耗尽(OOM)终结者,如果低内存导致系统运行危险,它就会介入。当系统内存快要耗尽的时候,OOM终结者就会开始终结进程。有些情况下,终止的可能是占用大量RAM的进程,但它并不能保证不会终止未占用大量RAM的进程。有的时候它也会终止像sshd这样的程序或者其他进程,而不是真正的罪魁祸首。很多时候,OOM终止了一些进程之后,系统就会变得不大稳定,所以你不得不重启机器以确保所有的系统进程都在正常运行。如果OOM终结者介入了,在/var/log/syslog中你会看到如下行:

2.4 解决高I/O等待时间问题
当看到I/O等待时间所占CPU时间的比重很高的时候,首先检查机器是否正大量使用交换空间。因为磁盘操作的速度远远低于RAM,所以当系统内存耗尽,开始使用交换空间的时候,系统的性能会受到严重影响。任何想要访问硬盘的操作都要完成与硬盘的I/O交换。所以,故障排除的第一步是看内存是否耗尽,如果是,先解决这个问题。如果还有大量可用的RAM,你需要明确哪个进程占用了大部分I/O操作。
有的时候很难弄明白到底是哪个进程占用了大量I/O资源,但是如果系统中存在多个分区,可以缩小范围,找到哪个分区正在执行大量I/O操作。想要做到这一点,需要使用iostat程序,基于Red Hat和基于Debian的系统的sysstat包中都提供了这个程序。如果机器没安装,可以通过包管理工具来安装。
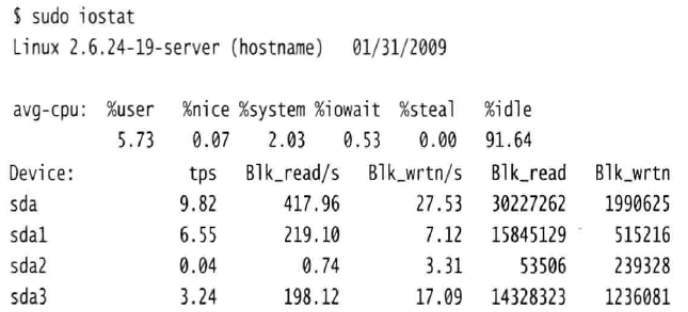
首先看到的是与top命令相似的CPU信息,下面紧跟着系统上所有硬盘设备以及分区的I/O状态信息。各列代表的意义:
tps
这个值列出了设备每秒的传输量。“传输”(Transfer)是向设备发送I/O请求的另一种表达方式。
Blk_read/s
表示每秒从设备读取的数据量。
Blk_wrtn/s
表示每秒从设备写入的数据量。
Blk_read
这一列表示从设备读取的数据总量。
Blk_wrtn
这一列表示写入设备的数据总量。
当系统处于高I/O负载状态的时候,首先就是观察每个分区,看看哪个分区的I/O负载最高。比如,有一台数据库服务器,数据库本身存储在/dev/sda3分区。如果看到大量的I/O操作来自这里,这就是一个很高的线索:数据库很可能占用了大量I/O资源。
弄明白这一点后,下一步就是确定I/O操作大部分来自读取还是写入。假设怀疑备份工作导致了I/O操作的增长。因为备份工作的操作主要集中于从文件系统中读取文件,然后通过网络传输到备用服务器,如果大量的I/O操作都来自于写入而不是读取操作,那么大概就可以排除这个问题。
注意:
你可能需要运行iostat命令多次,以此得到系统当前的精确I/O状况。如果在命令行指定一个数字参数,iostat就会持续运行并根据指定的秒数刷新输出信息。比如说,如果你想要每2秒看到一次iostat的输出,就可以输入iostat 2。如果你有任何NFS共享,iostat另一个非常有用的参数是-n,当你指定了-n参数,iostat就会给出所有NFS共享的I/O统计信息。
除了iostat,还有一个很简单的工具,它是top和iostat程序的混合体,能够显示系统中所有运行进程并将进程根据I/O统计信息排序。在默认情况下没有安装这个程序,可以再iotop包中找到它。
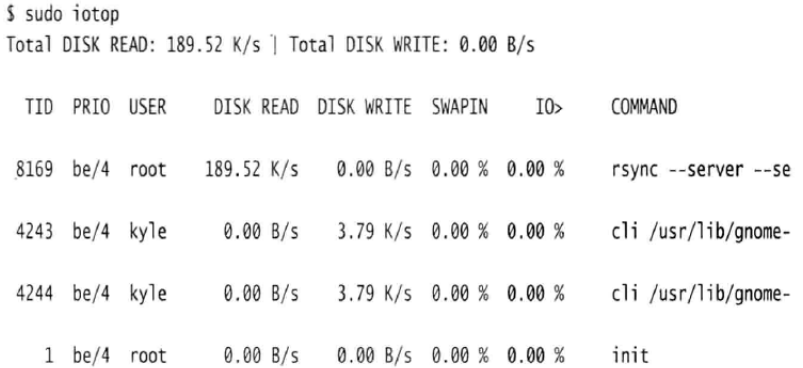
在这个例子中,会看到rsync进程执行了大量I/O读取操作。
2.3问题发生后的高负载处理
问题发生后的排查原因,只需要稍微多做一点工作,就能在服务器上安装相应的工具,记录全天的性能数据。
sysstat包中iostat工具能来解决高I/O的问题,sysstat也包含一些能报告CPU和RAM使用情况的工具。虽然可以使用top命令达到这个目的,但是sysstat更加强大,它能够用一种简单的机制来记录系统的统计信息,如CPU负载、RAM以及I/O状态。借助这些统计信息,当有人抱怨昨天中午系统很慢时,就可以查看日志,看看是什么原因引起的这个问题。
注意:
现在可以很方便得通过zabbix监控做到。
3.1配置sysstat
在基于Red Hat的系统上,需要修改/etc/sysconfig/sysstat文件,更改HISTORY选项,让它可以记录7天以上的统计信息。统计信息可以每10分钟抓取一次并记录每日总结。默认是记录28天。
一旦启用了sysstat,它就会每10分钟收集一次系统状态并将它存储到/var/log/sysstat或/var/log/sa文件中。除此之外,每天晚上再午夜之前,它还会分割统计文件。这些操作都是由/etc/cron.d/sysstat脚本执行的,所以如果想要更改sysstat收集信息的频率,可以修改这个脚本文件。
3.2查看CPU统计信息
sysstat统计信息的时候,它将这些信息存储在以sa开头、以本月当前日期结尾的文件名的文件中(如sa03)。这就意味着你可以查看从当前日期起,一个月以内的统计数据。使用sar工具可以查看这些统计信息。默认情况下sar会输出当天的CPU统计信息:
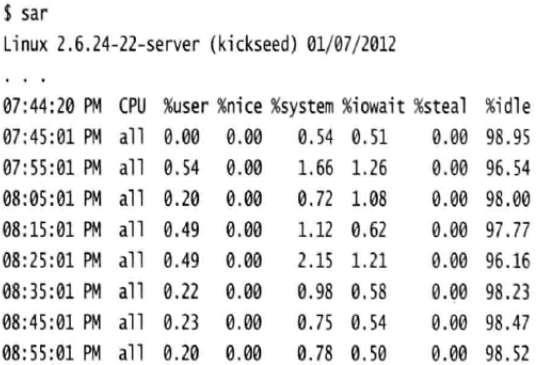

从输出可以发现,CPU很多统计信息和top命令的输出相同,在最后一行,sar还为每个值提供了平均值。
3.3查看RAM统计信息
sysstat计划任务不仅可以收集CPU负载信息,还能收集很多别的信息。使用-r选项就可以收集RAM的统计信息:
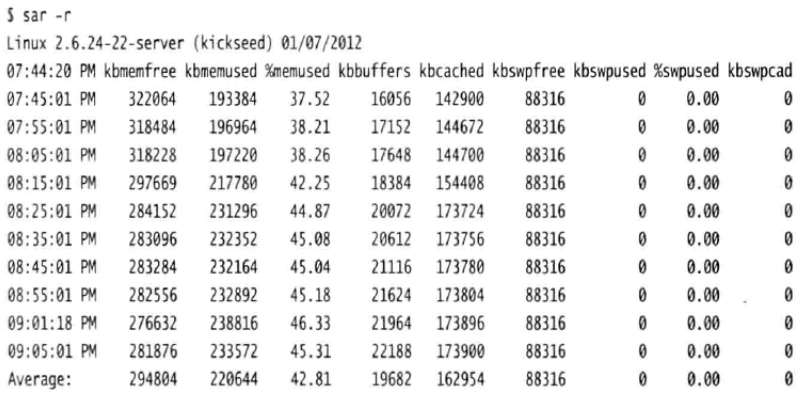
在这里可以看到使用了多少内存,空闲多少内存,同时还能查看交换空间的信息以及文件缓存的信息,这些信息与用top或free命令输出的信息类似。与之不同的是,你可以及时查看之前的信息。
3.4查看磁盘统计信息
磁盘统计信息,使用-b选项能给出一些列磁盘I/O的基本信息。

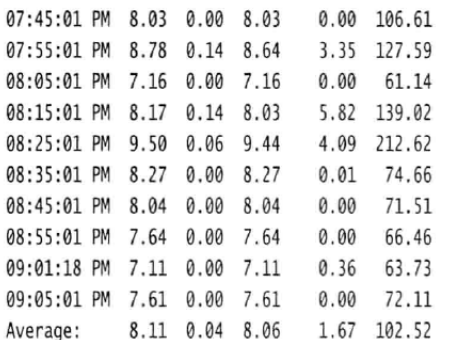
从这里可以看到每秒总共输出的数据量(tps),它由总共读取的数据量和写入的数据量(分别是rtps和wtps)相加获得。bread/s列并非用来衡量块I/O,而是告诉你平均每秒读取的数据量。bwrtn/s能告诉你平均每秒写入的数据量。
ar程序可以传入很多参数,输出特定的数据集,如果想看到所有数据。使用-A选项可以做到这点。它会显示包括负载平均值、CPU负载、RAM、磁盘I/O、网络I/O和其他一些有趣值在内的统计信息。通过阅读sar的用户手册(输入man sar)可以了解到想要看特定的统计信息应该传入什么标志位。
3.5查看之前的统计信息
有时需要查看一天中部分时间段内的信息。想要获得指定时间范围内的信息,可以使用-s和-e参数分别指定你感兴趣的开始时间和结束时间。例如,想查8:00pm—8:30pm这个时间段内的CPU数据,需要输入:

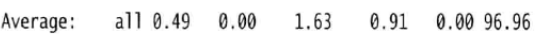
如果想要获取非当天的数据,使用-f选项,后面输入存储在/var/log/sysstat或/var/log/sa文件夹内统计信息文件的完整路径。例如,想要获取本月第6天的统计信息,输入:
sar -f /var/log/sysstat/sa06
也可以混合使用任意其他sar选项,从而获得特定类型的统计信息。
评论暂时关闭