L01-Linux (RHEL6.5)集群中部署NTP,l01-linuxrhel6.5
L01-Linux (RHEL6.5)集群中部署NTP,l01-linuxrhel6.5
RHEL6.5集群中部署NTP
NTP全称为Network Time Protocol,即网络时间协议。一般在Linux系统中用来同步集群中不同机器的时间。
本文描述的ntp服务部署框架如下图示
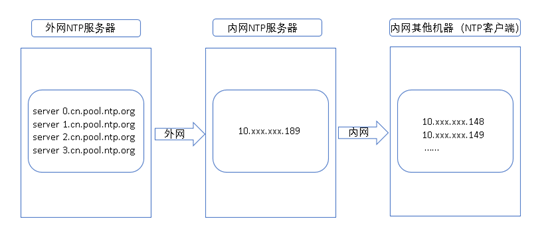
如上图,框架中的有外网ntp服务器、内网ntp服务器和内网中的其他机器。为讲解方便先作如下假设:
外网ntp服务器:xx.cn.pool.ntp.org
内网ntp服务器:10.xxx.xxx.189
内网中的其他机器:10.xxx.xxx.148和10.xxx.xxx.149
(189、148和149等的操作系统都是Red Hat 6.5)
机器之间的关系是这样的:
(1)外网ntp服务器与内网ntp服务器的关系:
内网ntp服务器189首先根据外网ntp服务器的时间,调整自己的时间至同准确时间一致,然后通过ntpd或ntpdate定时向外网ntp服务器同步时间。此时外网服务器为ntp服务器,189为ntp客户端;
(2)内网ntp服务器与内网其他机器的关系:
在189的时间调整准确之后,它便可以作为ntp服务器为内网中的其他机器提供服务了。此时189为ntp服务端,而148和149等其他机器为ntp客户端。
即整个架构中189同时作为ntp服务器和客户端而存在,就像一个三世同堂的家庭中,爸爸既是爸爸也是儿子,同样的道理。
一、内网ntp服务器(10.xxx.xxx.189)的设置
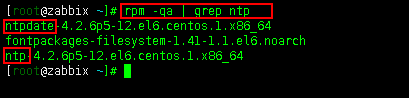
1、检查并安装ntp
使用rpm -qa | grep ntp 命令查看服务器是否安装了ntp,如果出现下面两个说明已安装。
倘若没有安装,可使用yum install -y ntp命令进行安装(前提是服务器的yum可用,若是yum无法使用,也可以到网上找到相应的rpm包进行手动安装)
2、使用ntpdate同步NTP服务器时间
这一步的主要命令有两个:
(1) ntpdate 0.cn.pool.ntp.org #ntpdate修改系统时间
(2) hwclock –systohc #将硬件时间修改到与系统时间相同
由于NTP的限制,如果系统时间与正确的时间相差太大的话,NTP是不会帮你做调整的——网上也有另一种说法,就是当你的时间设置和正确的时间相差很大的时候,NTP不会直接不同步,而是会花上很长一段时间进行同步调整——关于这点我没有实际测试过,反正不管是由于哪种原因,总之我们需要先通过ntpdate做一个时间同步,把189的时间调整到跟实际相同,用到的是第(1)个命令。
2.1
首先我们要先确定好自己的时区(若时区已经正确了可略过这步)。
根据所在地点重新设置时区。以上海为例。
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime #将时区设置成上海

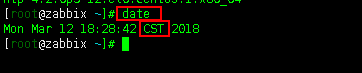
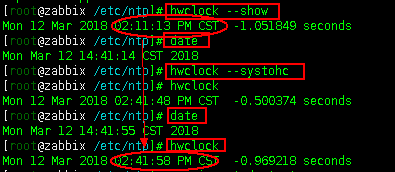
[root@zabbix ~]# date
Mon Mar 12 18:28:42 CST 2018 #可以看到我们的时区已经设置过来了,因为时区显示为CST了,CST即china standard time。
2.2
同步之前需要知道可用的外网NTP服务器是多少,通过NTP官网http://www.pool.ntp.org找到离自己城市最近的NTP服务器,如下图:
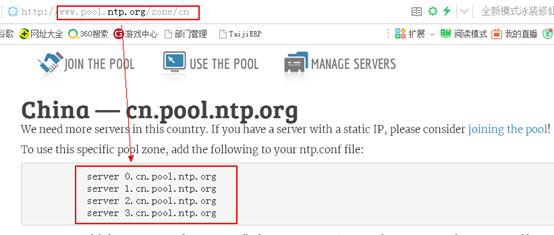
我取到的公网NTP服务器地址如下:
server 0.cn.pool.ntp.org
server 1.cn.pool.ntp.org
server 2.cn.pool.ntp.org
server 3.cn.pool.ntp.org
2.3
找到外网ntp服务器之后,接下来使用ntpdate将时间调准。
[root@zabbix ~]# ntpdate 0.cn.pool.ntp.org
12 Mar 14:03:12 ntpdate[19868]: step time server 85.199.214.100 offset 1114.672613 sec
注:可以执行两三遍以减少时延
执行前系统时间为下午1点42分,是错误的。

执行后系统时间修改为下午2点3分,已修改为正确时间。

注意:
(1)使用ntpdate修改时使用的是跃变的方式,就是说ntpdate命令是简单的将时间从某个点修改为另一个时间点,中间没有平滑的过渡。
(2)执行ntpdate xx.cn.pool.ntp.org命令时可能会报“the NTP socket is in use”的错误,如下图:
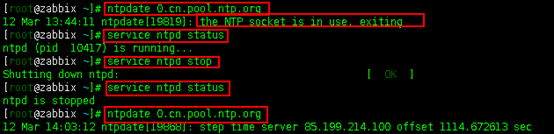
原因:造成该错误一般是因为系统ntpd服务器正在运行中,导致udp的123端口被ntpd占用。这可以通过service ntpd status或者 ps aux | grep ntpd 命令加以验证——大部分情况都是这个原因没跑了。
解决办法:若确实是这个原因,可使用命令 service ntpd stop 终止ntpd服务。实在不行可强行kill掉ntpd对应的pid。关闭ntpd服务之后就可以继续执行命令了。如上图。
(3)还有一种可能的报错是:no server suitable for synchronization found,这种情况可能是防火墙的原因,可直接跳到下面的防火墙部分,按照步骤开启防火墙的123 udp端口即可。“可能”两字使得这句话显得不那么自信,其实我在本地虚拟机上测试时确实报过这个错误,然后我开启123端口之后就解决了,但是当时并没有留下截图。但是不管怎样,123端口是无论如何都要打开的,所以作为排错,你在这一步先设置了也未尝不可。
2.4
上面2.3步骤中同步的是系统时间,接下来使用hwclock –systohc命令(sys(系统时间)to(写到)hc(Hard Clock))将系统时间设置成硬件时间。
3、配置/etc/ntp.conf主配置文件
此时若直接用service ntpd start命令启动189的ntp服务,其实已经可以向客户端提供时间更新服务了——这是因为,只要将NTP服务器的时间设定为正确时间,再将ntp服务启动,189就可以作为ntp服务器对内网中其他机器提供服务了,无需配置它的ntp主配置文件。但是,这样是满足不了企业安全性需求的(需配置ntp.conf中的restrict参数),并且谁也无法保证在189这一次性的时间调整之后,在接下来的时间里就它的时间永远都是对的(189需定时与外网ntp服务器做时间同步)。
因此在服务器接下来的运行期间,189需要定时与外网ntp服务器做时间同步,以保证它自己的时间不会跑偏。有两种方法:
(1) ntpdate + crontab的方法。
由前面我们知道,ntpdate 0.cn.pool.ntp.org命令可以将189的时间跟外网ntp服务器进行同步,因此只需在机器上建立相应的crontab任务定时的执行该命令就可以保证189在其运行期间的时间一致性了。比如,在crontab中添加:
0 12 * * * * ntpdate 0.cn.pool.ntp.org
若是采用这种方法,到这里就可以不用继续往下看了。
(2) ntpd服务的方法。
这种方法要好过第一种方法,因为ntpdate采用跃变的方式直接将时间修改过来,对一些依赖时间的应用程序可能会有影响。理想的做法是,在开机的时候使用ntpdate强制同步时间(因为机器刚开机,机器上的许多服务还没有启动,而且即使有个别应用已经启动并且ntpdate命令对其造成影响,影响也是相对较小的),在其他时候使用ntpd服务来平滑地同步时间。
接下来讲解的主要是采用第二种方法时ntp主配置文件/etc/ntp.conf的设置,该文件中需要注意的几个参数如下:
1)driftfile参数:解决NTP服务器校准时间时的传送延迟
格式: driftfile 文件名
用途:将与上级时间服务器联系时所花费的时间,记录在driftfile参数后面指定的文件内
注意:driftfile后面必须接完整的文件路径,不能是链接文件,并且必须要有ntpd守护进程可以写入的权限。
对应默认配置项:driftfile /var/lib/ntp/drift

注:实际操作中我没改过driftfile参数
2)restrict参数:权限的控制(非常重要的参数,内网ntp服务器需修改,内网ntp客户端可不用修改)
格式:restrict IP mask 掩码 参数
用途:IP规定了允许或不允许访问的地址(此处若为default,即为0.0.0.0所有ip),配合掩码可以对某一网段进行限制。
restrict参数包括:
ignore:关闭所有NTP服务
nomodify:客户端不能修改服务端的时间,但可以作为客户端的校正服务器
noquery:不提供时间查询,即用户端不能使用ntpq,ntpc等命令来查询ntp服务器
nopeer:不与同一层的其他服务器进行时间同步
kod:kod技术可以阻止“kiss of death”包(一种DOS攻击)对服务器的破坏
notrap:不提供trap远端事件登陆的功能
notrust:客户端除非通过认证,否则指定的网段为不信任网段 #ntp4.2之后的版本,已经默认没有这个参数,如果你添加了,会报错的。
对应默认配置项:
restrict default kod nomodify notrap nopeer noquery #默认对所有client拒绝所有的操作
restrict -6 default kod nomodify notrap nopeer noquery
restrict 127.0.0.1 #允许本机地址的一切操作
restrict -6 ::1
3)server参数:设定上级时间服务器(非常重要的参数,内网ntp服务器和客户端都需要配置)
格式: server IP地址或域名 [prefer]
用途:IP地址或域名即为该NTP服务器指定的上级NTP服务器。当指定多个NTP服务器时,使用prefer参数的服务器优先级最高,如果都没有使用prefer参数,那么服务器的优先级则按从上到下的顺序依次由高到低。在指定上层服务器后,至少15min才会与上层NTP服务器进行时间校对。
默认配置项:
server 0.rhel.pool.ntp.org iburst
server 1.rhel.pool.ntp.org iburst
server 2.rhel.pool.ntp.org iburst
server 3.rhel.pool.ntp.org iburst
在实际操作中我的修改只有两点,分别为: restrict和server。如下图
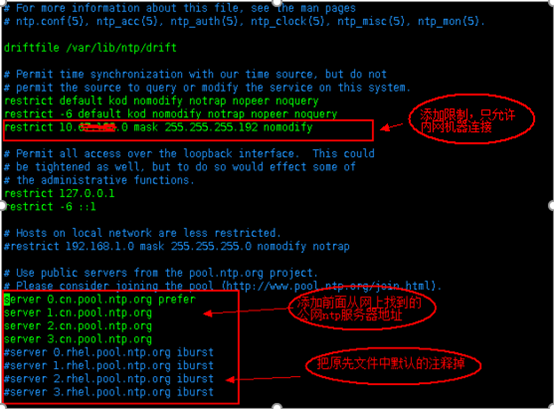
4)ntp服务默认只会同步系统时间。若是希望ntp也同时能修改机器的硬件时间,则需要将硬件时间的修改加入配置文件:在/etc/sysconfig/ntpd文件中,添加SYNC_HWCLOCK=yes

5)除此之外,还有一个文件:/etc/ntp/step-tickers
在我的实际操作中,内网ntp服务器189没有修改这个文件的也没有问题,但是内网的ntp客户端如148和149都配置了,不配置的话148、149无法与189进行时间同步,出现的情况为:148、149等ntp客户端的ntpd服务虽然启动了,但是不会与189的ntp服务器进行同步,查看客户端ntp状态时会一直显示下图所示的状态

网上关于step-tickers文件的解释是:当ntpd服务启动时,会自动与该文件中记录的上层NTP服务进行时间校对。
关于ntp.conf and step-tickers区别:
step-tickers is used by ntpdate where as ntp.conf is the configuration file for the ntpd daemon. ntpdate is initially run to set the clock before ntpd to make sure time is within 1000 sec. ntp will not run if the time difference between the server and client by more then 1000 sec ( or there about). The start up script will read step-tickers for servers to be polled by ntpdate.
默认情况下,我们配置的NTP服务器不会去时间源那里同步时间,所以必须修改/etc/ntp/step-tickers文件,加入我们的时间源,这样每次通过/etc/init.d/ntpd 来启动服务的时候就会自动更新时间了。
4、防火墙设置
配置完成之后,其实就可以启动服务了,但是在启动之前,我们先看一下防火墙设置。
NTP服务需要使用到UDP端口号123,在系统的防火墙(Iptables)启动的情况下,必须开放UDP端口号123。
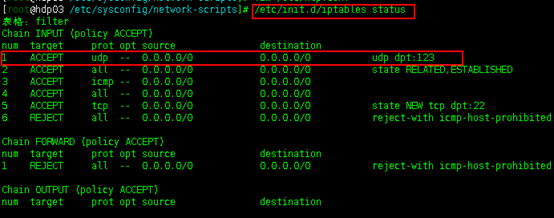
使用/etc/init.d/iptables status命令查看防火墙状态。

上图中我的防火墙在我之前安装其他服务的时候已经关闭了,所以这里不需要再设置了。但是如果你的防火墙没关。则需要按照如下步骤开放防火墙的123端口。
(1) /sbin/iptables -I INPUT -p udp --dport 123 -j ACCEPT #开放udp的123端口
(2) /etc/rc.d/init.d/iptables save #保存配置
(3) /etc/rc.d/init.d/iptables restart #重启防火墙服务
(4) /etc/init.d/iptables status #查看已开放端口
在服务器的防火墙开启,并且开放了123端口的示例:
(5) 也可以使用 lsof 命令来查看某一端口是否开放:lsof -i:123
如果防火墙没有开放UDP端口号123,肯定是会出问题的,到时候出错了可以直接上网查。
5.将ntp服务加入开机自启动
这一步其实挺有必要的,因为你的集群在部署好ntp服务之后,在往后项目的开发过程中都极少去关注它了,若某个时候你的某台服务器由于某些原因重启了(这总会发生的….),而你的ntp服务又不是开机自启动的,那么这台服务器在一段时间后就有可能时间跑偏了。
步骤如下:
(1)使用chkconfig --list | grep ntpd命令查看是否已将ntp服务加入开机自启动

(2)若没有加入,则使用chkconfig ntpd on命令将其加入
6.接下来就可以启动ntpd服务了。
(1)service ntpd start #开启ntp服务
(2)service ntpd status #查看状态
(3)service ntpd stop #停止ntp服务
(4)service ntpd restart #重启ntp服务
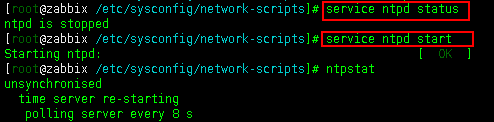
上图可见,在开启ntpd服务之后若是立马查询状态则有可能会出现unsynchronised。
这是由于每次重启NTP服务器之后大约要3-5分钟客户端才能与server建立正常的通讯连接。当此时用客户端连接服务端就会报这样的信息。一般等待几分钟就可以了。因此客户端重启ntpd服务之后执行ntpstat查看的时候有可能会出现这种情况。
NTP服务启动之后,可以使用下面几个命令进行查看其状态。
(1)ntpstat命令:查看ntp服务器有无和上层ntp连通
正常连通的情况如下图所示:

(2)ntpq –p命令:该命令可以列出目前我们的NTP与相关的上层NTP的状态
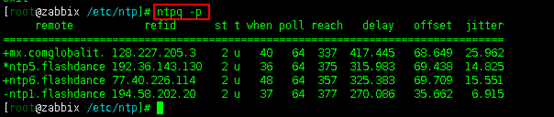
其中:
remote:即NTP主机的IP或主机名称。注意最左边的符号,如果由“+”则代表目前正在作用钟的上层NTP,如果是“*”则表示也有连上线,不过是作为次要联机的NTP主机。
refid:参考的上一层NTP主机的地址
st:即stratum阶层——理论上说,NTP 服务器是分等级(Stratum)的,Stratum = 1 的 NTP 服务器是直接和世界标准时钟同步的,包括 GPS 时间、铯原子钟、某些手机网络等。NIST、中国国家授时中心和中国教育网的第一级时间服务器都是这个级别的。Stratum = 2 的 NTP 服务器是和 Stratum = 1 的服务器同步的,性能稍差,但精确度也在毫秒的量级,所以用起来没什么区别。再往下每同步一级,Stratum 就加一。(这一段从网上摘抄过来)
when:几秒前曾做过时间同步更新的操作
poll:下次更新在几秒之后
reach:已经向上层NTP服务器要求更新的次数
delay:网络传输过程钟延迟的时间
offset:时间补偿的结果
jitter:Linux系统时间与BIOS硬件时间的差异时间
(3)watch “ntpq –p”命令:
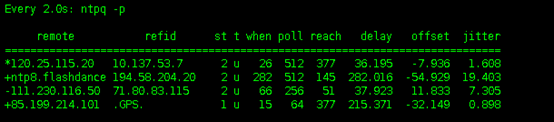
Ctrl + C 退出。
二、内网ntp客户端(10.xxx.xxx.148/149)设置
内网ntp客户端的设置跟内网ntp服务器189的ntp服务器设置其实差别不大:在上一步中,189是客户端,外网的xx.cn.pool.ntp.org是服务器;这一步,148和149是客户端,189变成服务器了。
所以在这一步的配置中,只需要把上一步中的外网服务器地址全部换成189的地址就可以了。
主要的不同有两点:
(1)客户端的/etc/ntp.conf文件中的restrict参数可以不用配置,它的/etc/ntp.conf文件中只需要修改server来设定189为它的上层时间服务器即可,其他保持默认。
(2)上一步配置内网ntp服务器设置时/etc/ntp/step-tickers是不用配置的,但是在这里的客户端设置时需要配置该文件:在该文件中加上189,如下所示:

图中之所以有两行是因为我做了简单的负载均衡和高可用,因此用prefer参数指定189为首选ntp服务器。
我这里更主要的是关注实施的步骤,更多的理论可以关注下面几篇文章,讲的非常好,我刚开始实施的时候就是看的这几篇文章,浅显易懂。
https://www.linuxboy.net/Linux/2013-11/92275.htm
https://www.linuxboy.net/Linux/2013-11/92275p2.htm
http://luijnijei.blog.163.com/blog/static/350245942010913912192/

评论暂时关闭