17 个案例带你 5 分钟搞定 Linux 正则表达式,
17 个案例带你 5 分钟搞定 Linux 正则表达式,

正则表达式是一种字符模式,用于在查找过程中匹配制定的字符。
元字符通常在Linux中分为两类:
正则表达式一般以文本行进行处理,在进行下面实例之前,先为grep命令设置—color参数:
- $ alias grep='grep --color=auto'
这样每次过滤出来的字符串都会带色彩了。
在开始之前还需要做一件事情,就是创建一个测试用的re-file文件,内容如下:
- $ cat re-file
- I had a lovely time on our little picnic.
- Lovers were all around us. It is springtime. Oh
- love, how much I adore you. Do you know
- the extent of my love? Oh, by the way, I think
- I lost my gloves somewhere out in that field of
- clover. Did you see them? I can only hope love.
- is forever. I live for you. It's hard to get back in the
- groove.
正则表达式元字符

特殊的元字符
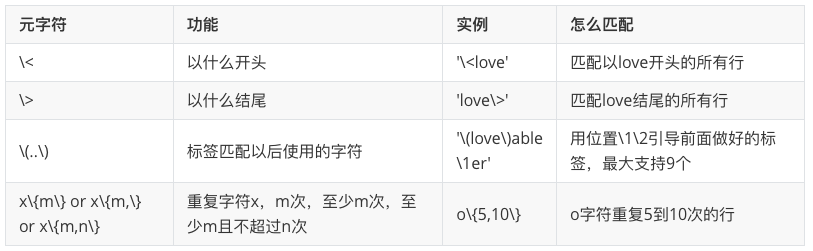
扩展的正则表达式

实操
匹配以love开头的所有行
- $ grep '^love' re-file
- love, how much I adore you. Do you know
匹配love结尾的所有行
- $ grep 'love$' re-file
- clover. Did you see them? I can only hope love.
匹配以l开头,中间包含两个字符,结尾是e的所有行
- $ grep 'l..e' re-file
- I had a lovely time on our little picnic.
- love, how much I adore you. Do you know
- the extent of my love? Oh, by the way, I think
- I lost my gloves somewhere out in that field of
- clover. Did you see them? I can only hope love.
- is forever. I live for you. It's hard to get back in the
匹配0个或多个空行,后面是love的字符
- $ grep ' *love' re-file
- I had a lovely time on our little picnic.
- love, how much I adore you. Do you know
- the extent of my love? Oh, by the way, I think
- I lost my gloves somewhere out in that field of
- clover. Did you see them? I can only hope love.
匹配love或Love
- $ grep '[Ll]ove' re-file # 对l不区分大小写
- I had a lovely time on our little picnic.
- Lovers were all around us. It is springtime. Oh
- love, how much I adore you. Do you know
- the extent of my love? Oh, by the way, I think
- I lost my gloves somewhere out in that field of
- clover. Did you see them? I can only hope love.
匹配A-Z的字母,其次是ove
- $ grep '[A-Z]ove' re-file
- Lovers were all around us. It is springtime. Oh
匹配不在A-Z范围内的任何字符行,所有的小写字符
- $ grep '[^A-Z]' re-file
- I had a lovely time on our little picnic.
- Lovers were all around us. It is springtime. Oh
- love, how much I adore you. Do you know
- the extent of my love? Oh, by the way, I think
- I lost my gloves somewhere out in that field of
- clover. Did you see them? I can only hope love.
- is forever. I live for you. It's hard to get back in the
- groove.
匹配love.
- $ grep 'love.' re-file
- clover. Did you see them? I can only hope love.
匹配空格
- $ grep '^$' re-file
匹配任意字符
- $ grep '.*' re-file
- I had a lovely time on our little picnic.
- Lovers were all around us. It is springtime. Oh
- love, how much I adore you. Do you know
- the extent of my love? Oh, by the way, I think
- I lost my gloves somewhere out in that field of
- clover. Did you see them? I can only hope love.
- is forever. I live for you. It's hard to get back in the
- groove.
前面o字符重复2到4次
- $ grep 'o{2,4}' re-file
- groove.
重复o字符至少2次
- $ grep 'o{2,}' re-file
- groove.
重复0字符最多2次
- $ grep 'o{,2}' re-file
- I had a lovely time on our little picnic.
- Lovers were all around us. It is springtime. Oh
- love, how much I adore you. Do you know
- the extent of my love? Oh, by the way, I think
- I lost my gloves somewhere out in that field of
- clover. Did you see them? I can only hope love.
- is forever. I live for you. It's hard to get back in the
- groove.
重复前一个字符一个或一个以
- $ egrep "go+d" linux.txt
- Linux is a good
- god assdxw bcvnbvbjk
- gooodfs awrerdxxhkl
- good
0个或者一个字符
- ansheng@Ubuntu:/tmp$ egrep "go?d" linux.txt
- god assdxw bcvnbvbjk
- gdsystem awxxxx
或,查找多个字符串
- $ egrep "gd|good" linux.txt
- Linux is a good
- gdsystem awxxxx
- good
分组过滤匹配
- $ egrep "g(la|oo)d" linux.txt
- Linux is a good
- glad
- good
评论暂时关闭