一文搞定 Perf 和 Gpertools,
一文搞定 Perf 和 Gpertools,

本文转载自微信公众号「小姐姐味道」,作者小姐姐养的狗。转载本文请联系小姐姐味道公众号。
在Linux下开发是幸福的,尤其是在发生问题的时候。永远忘不了在Windows下应用发生问题时那种无助的感觉。
Java提供了非常多的工具来应对故障排查、性能分析,比如jstat、jmap、jmc等。但大多数情况下,资源的瓶颈在操作系统上。如果宿主机并不能正常工作,那么在之上进行各种Java的应用分析就会变得没有意义。皮之不存毛将焉附,就是这个道理。
要做性能分析,Linux下有一个非常好用的工具,叫做perf。几乎每个发行版都有它的安装包。perf诞生于2009年,是一个内核级的工具;另外,还有一个工具叫做gperftools,是google的产品,是一个应用级别的产品。
虽然它们都有perf字样,但使用场景和处理的问题也是不一样的。
1. perf:CPU暴涨问题排查
顾名思义,perf是做性能分析用的。perf支持两种模式,计算模式和采样模式。比如,perf stat使用的是计算模式,而perf record采用的是采样模式。拿采样来说,它的原理是这样的:每隔一个固定的时间,产生一个中断,然后统计对应的pid和函数。采样就预示着与实际运行情况并不能保持一致,但如果一个函数运行的时间越长,被时钟中断的机会就越大。鉴于perf最终显示的是统计值,所以它的测量结果是高度可信的。
通过包管理工具可以很容易的获取perf。比如在centos下,直接通过yum install perf进行安装。perf提供了非常多的命令,我们可以直接输入perf输出这些选项。
Perf的功能非常多,常用的有perf list、perf stat、perf top、perf record、perf report等。下面以几个常见的例子,来说明它的应用场景。
使用下面的脚本,使得某一核CPU使用飙升到100%。
- cat /dev/zero > /dev/null
使用下面脚本,耗光CPU资源。(先取得cpu的核数,然后循环生成任务)。这段脚本将数据输出到/dev/null,所以只占用CPU资源,没有占用任何I/O资源。
- for i in `seq 1 $(cat /proc/cpuinfo |grep "physical id" |wc -l)`;
- do dd if=/dev/zero of=/dev/null &
- done
我们就拿下面的这个脚本来说明情况。从top的截图中,可以看到sy和ni的占用,达到了100%,我的脚本起作用了!(温馨提示:执行完脚本后,如果你想要杀死这些进程,除了重启之外,还可以直接通过ps找到相应的进程,然后使用kill命令终止)。

接下来使用record指令来录制CPU的使用情况。从上面的描述可以得知,统计结果是采样结果。
- <># perf record -a -e cycles -o perf.perf -g sleep 10
- [ perf record: Woken up 55 times to write data ]
- [ perf record: Captured and wrote 14.282 MB perf.perf (160302 samples) ]
程序将会运行10秒钟,然后将采样结果输出到perf.perf文件中。通过report命令可以展示统计结果。
- perf report -i perf.perf

可以看到大多数cpu的损耗都是在dd命令上,甚至里面的调用树,也能够清晰的展示。这在调试一些c++语言写的程序,或者调试jvm的一些内部行为时,非常的有用,因为它可以直接跟踪到系统调用层面。但有些细节,如果对Linux内核不是非常了解的话,下手就比较困难。所以通常情况下,我们只能通常粗略的定位到有问题的模块,然后再深入进行调试。

perf还可以通过指定进程号进行性能追踪,来获取性能数据。
- perf top -g -p 2343
2. 示例代码
了解到perf的基本用法,我们拿一个经常实际遇到的例子来说明一下perf的使用。堆外内存是通过JNI等类库进行调用所产生的内存,在实际排查中定位非常困难。传统的工具包括JMC,都不能快速有效的找到问题的元凶。黔驴技穷的时候,一般就到了perf上场的时候了。
为了演示这个过程,我特意做了一段非常精致的JAVA代码。代码片段较长,可以访问下面的gist链接,下面只说明关键代码。这段代码是典型的堆外内存泄露问题。
- https://gist.github.com/lycying/70ff3897d8516011c7ffc702aa0d03c2
使用com.sun.net.httpserver.HttpServer自带的简易server,可以非常容的构造一个服务器,我们可以通过请求去改变一些应用行为。
使用下面的JVM参数启动这段代码。
- java -Xmx1G -Xmn1G \
- -XX:+AlwaysPreTouch \
- -XX:MaxMetaspaceSize=10M \
- -XX:MaxDirectMemorySize=10M \
- -XX:NativeMemoryTracking=detail LeakExample
程序将人为创建一个停顿状态,具体测试步骤如下。
这将会得到下面的一张图。

但我们不能从中得到有用的信息。是方法错了么?是的。采样内存,要使用perf mem record指令,但是这个指令在大多数机器上都不能工作,得到的信息也有限。
perf记录的是CPU的性能数据,这里要特别说明一下。只要是使用率上5%的,我一般都会关注。一般情况下,占用的cpu时间片多,证明使用内存也比较多。但事情总有例外的时候,比如频繁申请1byte的方法块,和一次性申请1MB的方法块,并不能同日而语。
所以perf能不能发现内存问题,要看运气。
3. gperftools:找到堆外内存的元凶
要找到内存问题,要使用google的gperftools,我们主要用到它的 Heap Profiler,功能很强大。https://github.com/gperftools/gperftools
它的启动方式有点特别,安装成功之后,你只需要输出两个环境变量即可。
- mkdir -p /opt/test
- export LD_PRELOAD=/usr/lib64/libtcmalloc.so
- export HEAPPROFILE=/opt/test/heap
在同一个终端,再次启动我们的应用程序,可以看到内存申请动作都被记录到了 opt 目录下的 test 目录。

接下来,我们就可以使用 pprof 命令分析这些文件。
- cd /opt/test
- pprof -text *heap | head -n 200
使用这个工具,能够一眼追踪到申请内存最多的函数。Java_java_util_zip_Inflater_init 这个函数立马就被发现了。
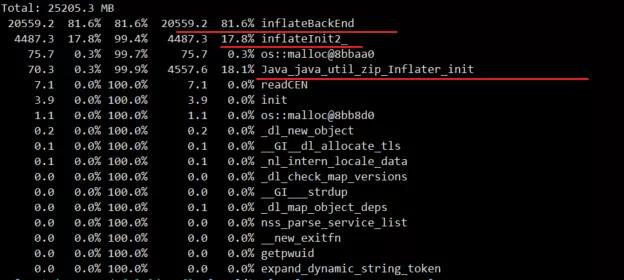
这就是我们模拟内存泄漏的整个过程,到此问题就解决了。
GZIPInputStream 使用 Inflater 申请堆外内存、Deflater 释放内存,调用 close() 方法来主动释放。如果忘记关闭,Inflater 对象的生命会延续到下一次 GC,有一点类似堆内的弱引用。在此过程中,堆外内存会一直增长。
问题发生在我们的decompress函数上。它在使用的时候,忘记关闭流了。我们可以看一下异常和正常情况的区别。
这段是忘了关闭流的函数。这种情况在编码中经常会发生。
- public static String decompress(byte[] input) throws Exception {
- ByteArrayOutputStream out = new ByteArrayOutputStream();
- copy(new GZIPInputStream(new ByteArrayInputStream(input)), out);
- return new String(out.toByteArray());
- }
下面是修改后正常的函数。
- public static String decompress(byte[] input) throws Exception {
- ByteArrayOutputStream out = new ByteArrayOutputStream();
- GZIPInputStream gzip = new GZIPInputStream(new ByteArrayInputStream(input));
- try {
- copy(gzip, out);
- return new String(out.toByteArray());
- }finally {
- try{ gzip.close(); }catch (Exception ex){}
- try{ out.close(); }catch (Exception ex){}
- }
- }
4. 题外话
使用pprof,还可以输出图形化的分析报告,需要安装图形生成工具graphviz,可以说是非常nice了。
另外不得不提的一点是,perf和gperftools对性能的影响,虽然不是特别大,但也尽量不要在线上环境使用它们。据我实际使用的经验判断,这个性能损耗率大概在30%左右。如果你的问题可以复现,通过常规手法又无法解决的情况下,可以使用这些工具去分析。比如你的应用实例有5个,完全可以分20%的流量到专用的机器上,把profile打开,相信你会很快定位到问题。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。
评论暂时关闭