有关性能的案例分享:5分钟内定位线上问题
有关性能的案例分享:5分钟内定位线上问题
51CTO精选译文】今天要与各位读者分享另一则颇有意思的故事。我确信,只要读者是应用所有者,或者负责运行Web应用程序,那么大多数人都会有兴趣。
我们最近为我们的大多数实际运行的网站改变了验证服务。本人负责的这个网站是Compuware APM Community。验证服务发生变化是一件大事,我们先在测试环境上上测试了这个变化,之后才部署到线上的生产环境。测试环境下一切看起来很好。结果部署到线上环境之后发现,有一个方面我们遗漏了,导致特定的用户组当中有几个用户受到了影响,他们现在访问不了网站上的某些内容。
我前前后后花了5分钟时间来查找这个问题、确认带来的影响,并且为我们的操作部门提供了足够多的信息,以便解决问题。
编者注:本文来自Compuware dynaTrace的团队博客,以下的操作步骤主要是试用dynaTrace网站监测工具来完成,有产品宣传的意思在里面。不过重要的是发现线上环境问题的一个思路,这个思路仍然有一定参考意义。
第一个问题:有没有问题是我们在测试环境中没有发现的?
打开应用程序概况图后显示,我们的Community门户网站上某个事务出现的失败率非常高:
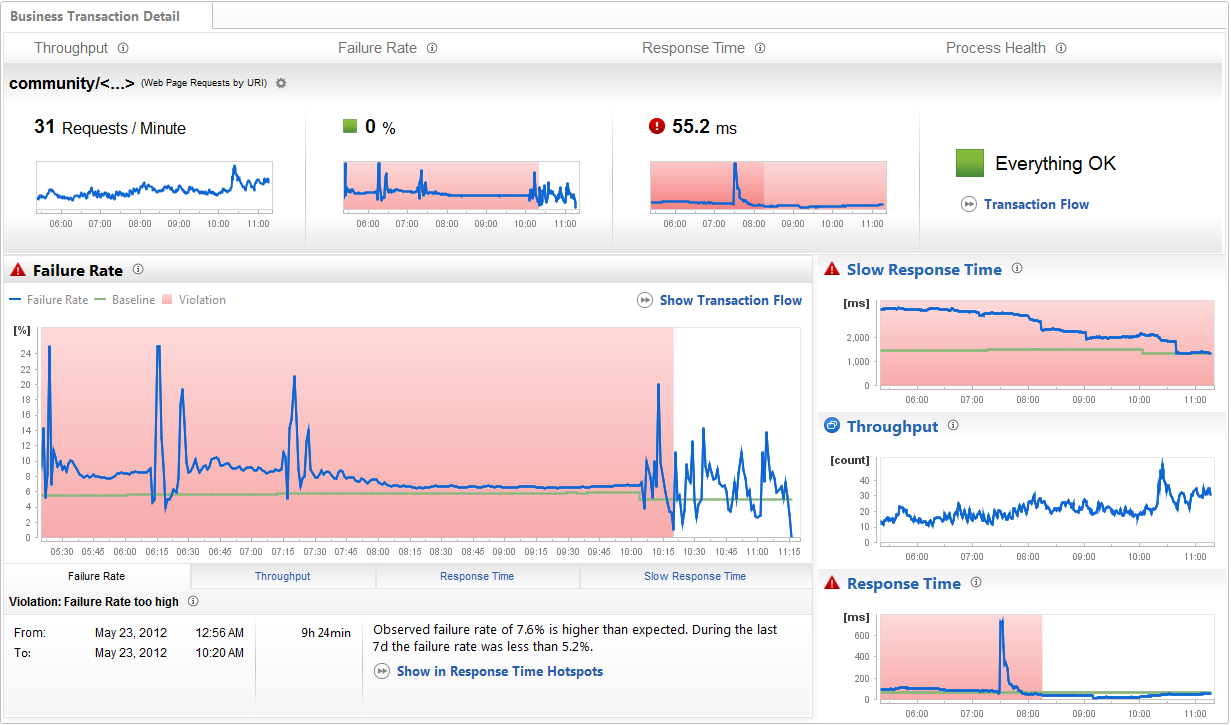
应用程序概况图表明了我们的其中一个事务出现的失败率很高。
先来回答第一个问题:没错,我们确实遇到了问题!
第二个问题:究竟是什么问题?
下一步是查看自动检测到的错误,这些错误表明这种问题与HTTP 4xx请求有关——这意味着,许多用户访问几个页面的请求被拒绝:
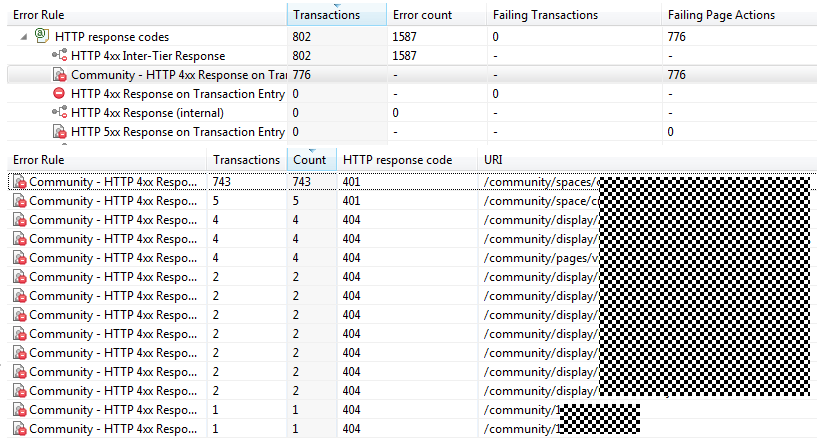
访问拒绝问题是导致失败率很高的根源。
现在,我们完全知道了访问这些页面出现了限制问题。至于这是个实际的问题还是只是用户试图访问受限制的内容,还没有搞清楚。
第三个步骤:这是个实际的问题吗?如果是,我能为操作部门提供什么样的信息以解决问题?
正如前面所说的那样,这可能是由于许多用户只是试图访问受限制的内容——这种情况下,我们觉得这些错误没什么大不了,因为本来就会是这样。查看了底层的错误信息比如异常)后,我们发现,问题实际上与我们的验证服务有关。看来我们在改用新的验证系统之后没有把所有的安全组迁移过去:
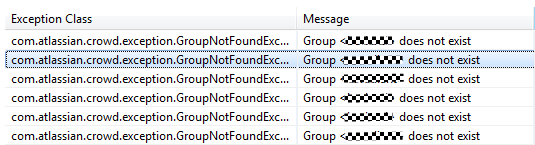
异常详细信息表明,我们的安全组遇到了一个问题。
这些信息足以让操作部门搞清楚为什么这些安全组没有被迁移过去。
第四个问题:哪些用户受到了影响?我们能够积极主动地联系这些用户、表示歉意吗?
由于我们现在知道这个问题出在我们身上,我们想知道哪些用户受到了影响。作为应用程序所有者,我想积极主动地联系这些用户,解释他们看来遇到了问题尽管他们还没有报告这些问题),并且让他们知道我们正在积极寻求解决办法。借助我们的用户体验解决方案,我们完全搞清楚了遇到这些异常的每一个访客的具体情况:
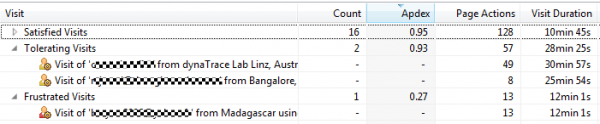
受到验证问题影响的访客
结束语
幸好,我们在测试环境测试了这套系统,因而我们得以解决了这方面的问题。但要是能真正看清生产环境下出现的问题,那就更好了,因为并不总是可能测试每一种场景。
原文:Field Report: 5 Minutes to Identify a Production Problem and its Impact about:performance
评论暂时关闭