Linux流量控制的实现方法
Linux流量控制的实现方法
目前很多企业的内部局域网已经建立,很多还在局域网基础上建立了企业内部的MIS系统和邮件服务器等,甚至在系统中开展了视频点播等数据流量较大的业务。 Linux流量控制给企业服务带来便利和高效。
企业内部网络有足够的带宽可以使用。但是,一般在企业接入Internet的部分都是一个有限的流量。为了提高网络的使用质量,保证用户按照网络中业务设计的要求来使用整个网络的带宽,可以从流量控制服务器的角度分析、优化Linux系统,给企业服务带来便利和高效。
Linux流量控制的基本实现
Linux操作系统中的流量控制器TC)主要是通过在输出端口处建立一个队列来实现流量控制。Linux从2.1.105版内核开始支持流量控制,使用时需要重新编译内核。Linux流量控制的基本实现可简单地由图1来描述。从图1可以看出,内核是如何处理接收包、如何产生发送包,并送往网络的。
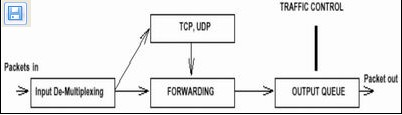
图1 Linux流量控制的基本实现
接收包进来后,由输入多路分配器Input De-Multiplexing)进行判断选择:如果接收包的目的是本主机,那么将该包送给上层处理;否则需要进行转发,将接收包交到转发块Forwarding Block)处理。转发块同时也接收本主机上层TCP、UDP等)产生的包。转发块通过查看路由表,决定所处理包的下一跳。然后,对包进排列以便将它们传送到输出接口Output Interface)。Linux流量控制正是在排列时进行处理和实现的。
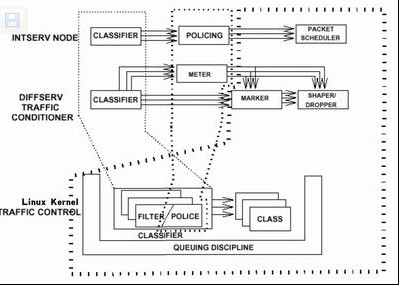
图2 流量控制基本框架
如图2所示,Linux流量控制主要由三大部分来实现:
◆ 队列规则Queue Discipline)
◆ 分类Classes)
◆ 过滤器Filters)
因此,Linux流量控制主要分为建立队列、建立分类和建立过滤器三个方面。其基本实现步骤为:
1)针对网络物理设备如以太网卡eth0)绑定一个队列;
2)在该队列上建立分类;
3)为每一分类建立一个基于路由的过滤器。
评论暂时关闭