Linux集群认证
Linux集群认证
当组织添加应用程序和服务时,将认证和密码服务集中化可以增加安全性、减少管理开销及开发人员的负担。但是,将所有服务聚集到单个服务器上会引起可靠性问题。对于企业认证服务,高可用性尤其关键,因为在许多情况中,当认证停止工作时,整个企业都将陷入停顿。
我们使用 LDAP轻量级目录访问协议,Lightweight Directory Access Protocol)服务器来提供认证服务,各种应用程序都可以订阅这些服务。为了提供高度可用的 LDAP 服务器,我们使用来自 Linux-HAwww.linux-ha.org)倡议的 heartbeat 软件包。我们也提供一个示例,设置 Apache Web 服务器以使用 LDAP 认证。
关于 LDAP 的一些背景知识我们使用 OpenLDAP 软件包 www.openldap.org),它是几种 Linux 分发版的组成部分。它随 RedHat 7.1 一起提供,其当前下载版本是 2.0.11。
RFC 的 2251 和 2253 中定义了 LDAP 标准。存在几种 LDAP 的商业实现,其中包括密歇根大学University of Michigan)的实现和 Netscape 的实现。OpenLDAP 基金会是作为“为开发健壮的、商业级别的、功能完善和开放源码的 LDAP 应用程序与开发工具套件而协力完成的工作”创建的请参阅 www.openldap.org)。OpenLDAP V1.0 于 1998 年 8 月发行。其当前主版本是 2.02000 年 8 月 31 日发布),添加了 LDAPv3 支持。
正如所有好的网络服务一样,LDAP 旨在跨多个服务器运行。本文使用了 LDAP 的两个特性 — 复制replication)和 引用referral)。
引用机制使您能跨多服务器分割 LDAP 名称空间,并能以层次结构的形式安排 LDAP 服务器。LDAP 在一个特定目录名称空间中只允许有一个主服务器。
复制由 OpenLDAP 复制守护程序 slurpd驱动。slurpd 定期醒来并检查主服务器上的日志文件,看是否有更新。更新随后被传递到从服务器。读请求可以由任一服务器应答,但更新只能在主服务器上进行。对从服务器的更新请求会生成一个引用消息,该消息会给出主服务器的地址。跟踪引用和重新尝试更新是客户机的职责。OpenLDAP 没有内置方法来跨已复制服务器分发查询,因此必须使用 IP 发射器sprayer)/扇出fanout)程序如 balance)。
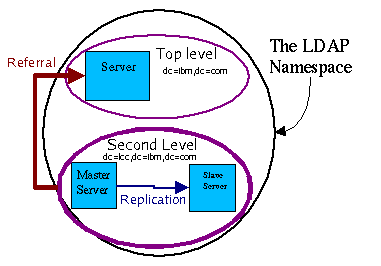
为了实现可靠性目标,我们将一对服务器以群集方式组织在一起。我们可以在服务器间使用共享存储器,维护一个数据副本。但为了简单起见,我们选择进行无共享shared-nothing)的实现。LDAP 数据库通常很小,而且更新频率较低提示:如果您的 LDAP 数据集确实较大,请考虑用引用将名称空间划分成较小的部分)。重新启动故障节点时,对无共享设置的确需要注意:在重新启动之前,必须将所有新的更改添加到故障节点上的数据库。稍后,我们将演示一个示例。
群集软件和配置在开始之前,让我们澄清一个细微的混淆。大多数 HA高可用性,High Availability)群集都有一个名为“heartbeat”的系统持活system-keepalive)功能。HA 软件使用 heartbeat 以监控群集中节点的健康状态。Linux-HA www.linux-ha.org)组提供了开放源码群集软件。他们软件包的名称是 Heartbeat目前是 Heartbeat-0.4.9)。这可能导致一些可以理解的混淆喔,它有时也使我糊涂)。在本文中,我们将把 Linux-HA 软件包称为“Heartbeat”,而把一般性的概念称为“heartbeat”。
Linux-HA 项目作为 Linux-HA HOWTOHarald Milz 撰写)的产物于 1998 年启动。该项目目前由 Alan Robertson 和其他许多志愿开发人员领导。版本 0.4.9 于 2001 年早期发布。
Heartbeat 通过通信媒介监控节点的可用状态,媒介通常是串行线或以太网。最好有多个冗余媒介,因此我们使用了一条串行线和一个以太网链路。每个节点运行一个守护程序进程名为“heartbeat”)。主守护程序派生子进程以对每个 heartbeat 媒介进行读写,并且派生状态进程。当检测到节点终止时,Heartbeat 运行 shell 脚本以在辅助节点上启动或停止)服务。在设计时,规定这些脚本使用与系统 init 脚本通常位于 /etc/init.d)相同的语法。它还提供了用于文件系统、Web 服务器和虚拟 IP 故障转移的缺省脚本。
假设有两个匹配的 LDAP 服务器,我们可以使用几种配置。首先,我们可以实现‘冷备用’。主节点有一个虚拟 IP 和正在运行的服务器。辅助节点处于空闲状态。当主节点出现故障时,服务器实例和 IP 会转移到“冷”节点。这是容易实现的,但主服务器和辅助服务器之间的数据同步却是个问题。要解决这个问题,我们可以这样配置群集,即在两个节点上都配置处于运行状态的服务器。主节点运行主 LDAP 服务器,辅助节点则运行从实例。对主服务器的更新通过 slurpd 被立即传递到从服务器。
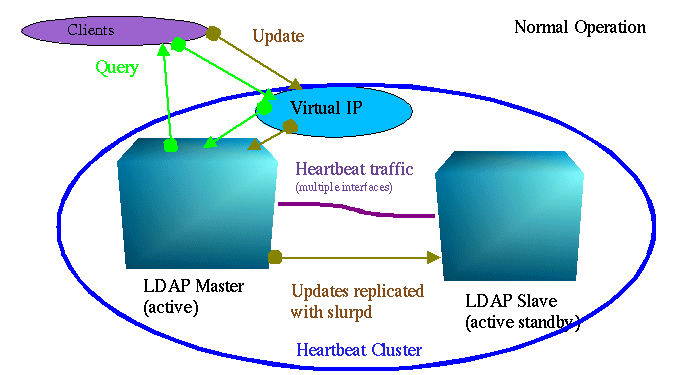
主节点的故障使得辅助节点要响应查询,但现在我们还不能更新。为了提供更新,在故障转移时,我们要重新启动辅助服务器并将它提升为主服务器。
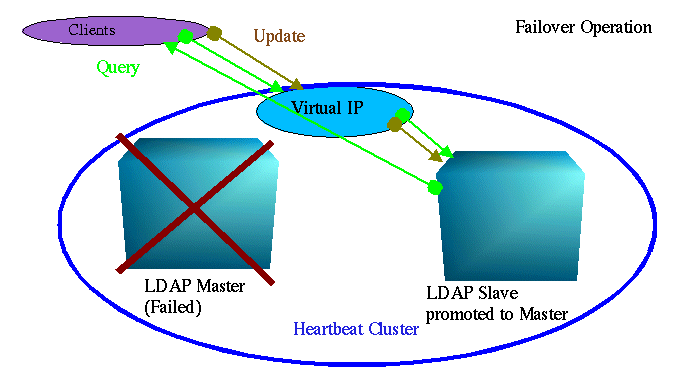
这给予我们完整的 LDAP 服务,但却增加了一个问题 — 如果向辅助服务器作出了更新,那么在允许它重新启动之前必须修复主服务器。Heartbeat 支持‘nice failback’选项,该选项禁止有故障的节点在故障转移后重新获得资源,这会更令人满意。在本文中,我们手工演示重新启动。我们的样本配置将使用 Heartbeat 提供的虚拟 IP 工具。如果需要支持较重的查询负载,则会用同时向主从服务器分发查询的 IP 发射器取代虚拟 IP。在这一情况中,对从服务器作出的更新请求会产生引用。对引用的跟踪不是自动的;必须将该功能构建到客户机应用程序中。除了复制伪指令外,主节点和从节点是以完全相同的方式配置的。 主服务器配置文件指明复制日志文件的位置第 16 行),并且有一份从服务器的清单,这些从服务器是具有凭证信息的复制目标第 34-36 行)。
|
从服务器配置文件不指明主服务器;相反,它列出复制所需的凭证信息第 33 行)。
33 updatedn "cn=Manager,dc=lcc,dc=ibm,dc=com" 常规 Heartbeat 准备
有几个较好的基本 Heartbeat 配置示例可供使用请参阅本文的结尾部分)。以下是我们的配置中相关的内容。我们的配置非常简单,所以没有多少内容。缺省情况下,所有的配置文件都保存在 /etc/ha.d/中。
ha.cf包含群集的全局定义。我们对所有的超时都采用缺省值。
|
haresources该文件是配置故障转移的地方。在文件的底部有些有趣的东西。
slave6 192.168.10.51 slapd
我们在这里指明了三件事。资源的主要所有者是节点‘slave6’该名称必须与您打算设为主节点机器的‘uname -n’输出相匹配)。我们的服务地址虚拟 IP)是‘192.168.10.51’本示例是在专用实验室网络完成的,所以使用 192.168 地址)。服务脚本的名称是‘slapd’。Hearbeat 将在 /etc/ha.d/resource.d 和 /etc/init.d 中寻找脚本。
服务脚本对于简单“冷备用”情况,我们可以不加修改地使用标准 /etc/init.d/slapd 脚本。我们希望做一些特别的事,因此我们创建了自己的 slapd 脚本,该脚本存储在 /etc/ha.d/resource.d/中。 Heartbeat 将该目录放置在其搜索路径中的第一位,因此我们不必担心会运行 /etc/init.d/slapd 脚本。但是,您应该检查以确保引导时不再启动 slapd从 /etc/rc.d 树结构除去所有 S*slapd 文件)。首先,我们在第 17 行和第 18 行指明 slapd 服务器的启动配置文件。
该脚本遵循标准 init.d 语法,因此启动信息包含在从第 21 行开始的 test_start() 函数中。首先,我们停止当前运行的所有 slapd 实例。在第 39 行,我们使用主服务器配置文件启动主服务器。我们的设计将遵循这样的规则:如果主节点和辅助节点都已启动,则在主节点上将 slapd 作为主服务脚本启动,在辅助节点上将 slapd 作为从服务脚本启动,并启动复制守护程序。如果只有一个节点启动,则将 slapd 作为主服务脚本启动。将虚拟 IP 绑定到 slapd 主服务脚本。要完成这一点,我们必须知道哪个节点正在执行该脚本,如果是主节点,那么我们需要知道辅助节点的状态。重要的内容在脚本的‘start’分支中。因为我们已经在 Heartbeat 配置中指明了主节点,所以我们知道当 test_start() 函数运行时,它运行在 Heartbeat 主节点上因为 Heartbeat 使用 /etc/init.d/ 脚本,因此所有的脚本都用参数“start|stop|restart”调用)。当调用脚本时,Heartbeat 会设置许多环境变量。下面是我们感兴趣的一个:
HA_CURHOST=slave6
可以使用‘HA_CURHOST’值来了解何时正在主节点slave6)上执行以及何时处于故障转移中HA_CURHOST 应是‘slave5’)。现在我们需要知道另一个节点的状态。要了解这一点,可以“询问” Heartbeat。我们将使用随 Heartbeat 一同提供的 api_test.c文件,并创建一个简单的客户机来“询问”节点状态api_test.c 文件有许多内容都与客户机有关,我们只需除去不需要的内容,然后添加一条输出语句)。请注意程序中执行查询的第 31 行。
Heartbeat 查询源代码清单
编译后,我们将文件安装在 /etc/ha.d/resource.d/中。程序的名称为‘other_state’。以下是访问完整的故障转移脚本的链接,我们还是从与 Heartbeat 一同提供的示例脚本开始,并增加少许修改:
启动脚本 测试
我们现在可以在两个服务器上都启动 Heartbeat。Heartbeat 文档包含一些有关测试基本设置的信息,所以我们将不在这里重复。在连接了两种 heartbeat 媒介的情况下,您应该看到六个 heartbeat 进程正在运行。为了验证故障转移,我们做了几种测试。为了提供测试用的客户机,我们创建了一个简单的 KDE 应用程序,该应用程序查询服务器并显示连接的状态。真正的客户机在这种情况下只查询虚拟 IP,但我们查询所有的三个 IP,以作为演示之用。为进行该测试,我们每小时发送一万条查询。
S6 是主 LDAP 服务器,S5 是活动的备用服务器。下面的框代表虚拟 IP。在正常状态下,S5 和 S6 都为绿色,表明成功的查询。
首先,我们停止主节点上的 heartbeat 进程。在此情况下,从机器在 10 秒钟的节点超时出现后获得资源,如日志摘录中所示:接管过程包括启动脚本中额外的 2 秒延迟。
|
以下是应用程序的查询流:

主节点当机,现在由辅助节点提供虚拟 IP。S5 和虚拟 IP 显示为绿色,服务器 S6 不可用,指示器为红色。
重新启动群集之后,我们通过对主节点断电来造成一次故障。在 10 秒超时到时间以后,辅助节点再一次获取了资源。最后,我们通过拔掉串行接口和以太网接口来模拟两节点之间互连的完全失败。节点间通信的失败导致两台机器都试图充当主节点。这种情形被称为 “裂脑split-brain)”。Heartbeat 在这种情形下的缺省行为说明了为什么 Heartbeat 需要多个使用不同媒介的互连媒介。在共享存储器设置中,存储器互连也可以作为 heartbeat 媒介使用,这减少了“裂脑”的机会。以下是来自 ha-log 的样本,它显示了关机过程:
|
应在选择超时值时考虑这一问题。如果超时太短,负载繁重的系统会错误地触发接管,从而产生明显的“裂脑”关机。请参阅 Linux-ha FAQ 文档以获得有关这一点的更多信息。
故障转移后的恢复如果当主 LDAP 服务器当机时,对 LDAP 名称空间进行了更新,则必须在重新启动主服务器之前重新同步 LDAP 数据库。有两种方法可做到这一点。如果可以中断服务的话,可以在 LDAP 服务器停止后手工复制数据库缺省情况下,数据文件被放置在 /usr/local/var 中)。也可以使用 OpenLDAP 复制来恢复数据库而无需服务中断。首先,在以前的主节点上将 LDAP 服务器作为从服务器启动。然后在当前主节点上启动 slurpd 守护程序。在前主节点退出服务期间收到的更改将从新主节点“推”到原来的节点上。最后,在以前的主节点上停止从 LDAP 服务器,并启动 Heartbeat。这将导致向原始配置进行故障回复。
针对 Apache 的 LDAP 配置这里是向 LDAP 服务器进行订阅的应用程序示例。该应用程序是 Apache Web 服务器,使用 mod_auth_ldap 软件包。
结束语本文是一个非常简单的示例,使用开放源码软件创建一些高度可用的基本网络服务。网络服务包括 LDAP)很少需要大型服务器。由群集提供的额外可靠性以及服务器和数据文件的复制可以增加服务可用性。系统经历了所有的测试,在所有情况下都在 15 秒内进行了故障转移。假如对系统负载和利用率有较好的理解,可以把故障转移时间减少到这个阈值以下。
评论暂时关闭