Linux内核Crash分析(1)
Linux内核Crash分析(1)
在工作中经常会遇到一些内核crash的情况,本文就是根据内核出现crash后的打印信息,对其进行了分析,使用的内核版本为:Linux2.6.32。
每一个进程的生命周期内,其生命周期的范围为几毫秒到几个月。一般都是和内核有交互,例如用户空间程序使用系统调用进入内核空间。这时使用的不再是用户空间的栈空间,使用对应的内核栈空间。对每一个进程来说,Linux内核都会把两个不同的数据结构紧凑的存放在一个单独为进程分配的存储空间中:一个是内核态的进程堆栈,另一个是紧挨进程描述符的数据结构thread_info,叫线程描述符。内核的堆栈大小一般为8KB,也就是8192个字节,占用两个页。在Linux-2.6.32内核中thread_info.h文件中有对内核堆栈的定义:
#define THREAD_SIZE 8192
在Linux内核中使用下面的联合结构体表示一个进程的线程描述符和内核栈,在内核中文件include/linux/sched.h。
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
该结构是一个联合体,我们在C语言书上看到过关于union的解释,在在C Programming Language 一书中对于联合体是这么描述的:
1) 联合体是一个结构;
2) 它的所有成员相对于基地址的偏移量都为0;
3) 此结构空间要大到足够容纳最"宽"的成员;
4) 其对齐方式要适合其中所有的成员;
通过上面的描述可知,thread_union结构体的大小为8192个字节。也就是stack数组的大小,类型是unsigned long类 型。由于联合体中的成员变量都是占用同一块内存区域,所以,在平时写代码时总有一个概念,对一个联合体的实例只能使用其中一个成员变量,否则会把原先变量 给覆盖掉,这句话如果正确的话,必须要有一个前提假设,成员占用的字节数相同,当成员所占的字节数不同时,只会覆盖相应的字节。对于thread_union联合体,我们是可以同时访问这两个成员,只要能够正确获取到两个成员变量的地址。
在内核中的某一个进程使用了过多的栈空间时,内核栈就会溢出到thread_info部分,这将导致严重的问题系统重启),例如,递归调用的层次太深;在函数内定义的数据结构太大。
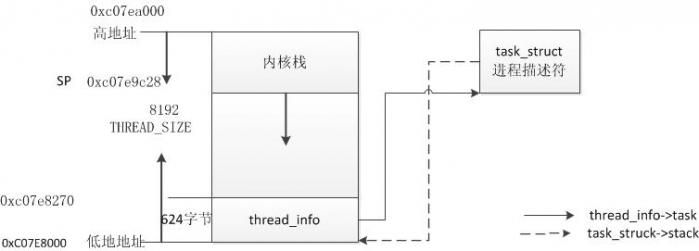
图:进程中thread_infotask_struct和内核栈中的关系
下面我们看一下thread_info的结构体:
struct thread_info {
unsigned long flags;/* 底层标志,*/
int preempt_count;/* 0 =>可抢占, <0 =>bug */
mm_segment_t addr_limit;/* 进程地址空间 */
struct task_struct *task;/*当前进程的task_struct指针 */
struct exec_domain *exec_domain;/*执行区间 */
__u32 cpu;/* 当前cpu */
__u32 cpu_domain;/* cpu domain */
struct cpu_context_save cpu_context;/* cpu context */
__u32 syscall;/* syscall number */
__u8 used_cp[16];/* thread used copro */
unsigned long tp_value;
struct crunch_state crunchstate;
union fp_state fpstate __attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state;/* ThumbEE Handler Base register */
#endif
struct restart_block restart_block;/*用于实现信号机制*/
};
PS:1)flag 用于保存各种特定的进程标志,最重要的两个是:TIF_SIGPENDING,如果进程有待处理的信号就置位,TIF_NEED_RESCHED表示进程应该需要调度器选择另一个进程替换本进程执行。
结合上面的知识,看下当内核打印堆栈信息时,都打印了上面信息。下面的打印信息是工作中遇到的一种情况,打印了内核的堆栈信息,PC指针在dev_get_by_flags中,不能访问的内核虚地址为45685516,内核中一般可访问的地址都是以0xCXXXXXXX开头的地址。
Unable to handle kernel paging request at virtual address 45685516 pgd = c65a4000 [45685516] *pgd=00000000 Internal error: Oops: 1 [#1] last sysfs file: /sys/devices/form/tpm/cfg_l3/l3_rule_add Modules linked in: splic mmp(P) CPU: 0 Tainted: P (2.6.32.11 #42) PC is at dev_get_by_flags+0xfc/0x140 LR is at dev_get_by_flags+0xe8/0x140 pc : [<c06bee24>] lr : [<c06bee10>] psr: 20000013 sp : c07e9c28 ip : 00000000 fp : c07e9c64 r10: c6bcc560 r9 : c646a220 r8 : c66a0000 r7 : c6a00000 r6 : c0204e56 r5 : 30687461 r4 : 45685516 r3 : 00000000 r2 : 00000010 r1 : c0204e56 r0 : ffffffff Flags: nzCv IRQs on FIQs on Mode SVC_32 ISA ARM Segment kernel Control: 0005397f Table: 065a4000 DAC: 00000017 Process swapper (pid: 0, stack limit = 0xc07e8270) Stack: (0xc07e9c28 to 0xc07ea000) 9c20: c0204e56 c6a00000 45685516 c69ffff0 c69ffff0 c69ffff0 9c40: c6a00000 30687461 c66a0000 c6a00000 00000007 c64b210c c07e9d24 c07e9c68 9c60: c071f764 c06bed38 c66a0000 c66a0000 c6a00000 c6a00000 c66a0000 c6a00000 9c80: c07e9cfc c07e9c90 c03350d4 c0334b2c 00000034 00000006 00000100 c64b2104 9ca0: 0000c4fb c0243ece c66a0000 c0beed04 c033436c c646a220 c07e9cf4 00000000 9cc0: c66a0000 00000003 c0bee8e8 c0beed04 c07e9d24 c07e9ce0 c06e4f5c 00004c68 9ce0: 00000000 faa9fea9 faa9fea9 00000000 00000000 c6bcc560 c0335138 c646a220 9d00: c66a0000 c64b2104 c085ffbc c66a0000 c0bee8e8 00000000 c07e9d54 c07e9d28 9d20: c071f9a0 c071ebc0 00000000 c071ebb0 80000000 00000007 c67fb460 c646a220 9d40: c0bee8c8 00000608 c07e9d94 c07e9d58 c002a100 c071f84c c0029bb8 80000000 9d60: c07e9d84 c0beee0c c0335138 c66a0000 c646a220 00000000 c4959800 c4959800 9d80: c67fb460 00000000 c07e9dc4 c07e9d98 c078f0f4 c0029bc8 00000000 c0029bb8 9da0: 80000000 c07e9dbc c6b8d340 c66a0520 00000000 c646a220 c07e9dec c07e9dc8 9dc0: c078f450 c078effc 00000000 c67fb460 c6b8d340 00000000 c67fb460 c64b20f2 9de0: c07e9e24 c07e9df0 c078fb60 c078f130 00000000 c078f120 80000000 c0029a94 9e00: 00000806 c6b8d340 c0bee818 00000001 00000000 c4959800 c07e9e64 c07e9e28 9e20: c002a030 c078f804 c64b2070 00000000 c64b2078 ffc45000 c64b20c2 c085c2dc 9e40: 00000000 c085c2c0 00000000 c0817398 00086c2e c085c2c4 c07e9e9c c07e9e68 9e60: c06c2684 c0029bc8 00000001 00000040 00000000 c085c2dc c085c2c0 00000001 9e80: 0000012c 00000040 c085c2d0 c0bee818 c07e9ed4 c07e9ea0 c00284e0 c06c2608 9ea0: bf00da5c 00086c30 00000000 00000001 c097e7d4 c07e8000 00000100 c08162d8 9ec0: 00000002 c097e7a0 c07e9f14 c07e9ed8 c00283d0 c0028478 56251311 00023c88 9ee0: c07e9f0c 00000003 c08187ac 00000018 00000000 01000000 c07ebc70 00023cbc 9f00: 56251311 00023c88 c07e9f24 c07e9f18 c03391e8 c0028348 c07e9f3c c07e9f28 9f20: c0028070 c03391b0 ffffffff 0000001f c07e9f94 c07e9f40 c002d4d0 c0028010 9f40: 00000000 00000001 c07e9f88 60000013 c07e8000 c07ebc78 c0868784 c07ebc70 9f60: 00023cbc 56251311 00023c88 c07e9f94 c07e9f98 c07e9f88 c025c3e4 c025c3f4 9f80: 60000013 ffffffff c07e9fb4 c07e9f98 c025c578 c025c3cc 00000000 c0981204 9fa0: c0025ca0 c0d01140 c07e9fc4 c07e9fb8 c0032094 c025c528 c07e9ff4 c07e9fc8 9fc0: c0008918 c0032048 c0008388 00000000 00000000 c0025ca0 00000000 00053975 9fe0: c0868834 c00260a4 00000000 c07e9ff8 00008034 c0008708 00000000 00000000 Backtrace: [<c06bed28>] (dev_get_by_flags+0x0/0x140) from [<c071f764>] (arp_process+0xbb4/0xc74) r7:c64b210c r6:00000007 r5:c6a00000 r4:c66a0000
1)首先,看看这段堆栈信息是在内核中那个文件中打印出来的,在fault.c文件中,__do_kernel_fault函数,在上面的打印中Unable to handle kernel paging request at virtual address 45685516,该地址是内核空间不可访问的地址。
static void __do_kernel_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
/*
* Are we prepared to handle this kernel fault?
*/
if (fixup_exception(regs))
return;
/*
* No handler, we'll have to terminate things with extreme prejudice.
*/
bust_spinlocks(1);
printk(KERN_ALERT
"Unable to handle kernel %s at virtual address %08lx
",
(addr <PAGE_SIZE) ? "NULL pointer dereference" :"paging request", addr);
show_pte(mm, addr);
die("Oops", regs, fsr);
bust_spinlocks(0);
do_exit(SIGKILL);
}
2) 对于下面的两个信息,在函数show_pte中进行了打印,下面的打印涉及到了页全局目录,页表的知识,暂时先不分析,后续补上。
pgd = c65a4000
[45685516] *pgd=00000000
void show_pte(struct mm_struct *mm, unsigned long addr)
{
pgd_t *pgd;
if (!mm)
mm = &init_mm;
printk(KERN_ALERT "pgd = %p
", mm->pgd);
pgd = pgd_offset(mm, addr);
printk(KERN_ALERT "[%08lx] *pgd=%08lx", addr, pgd_val(*pgd));
……………………
}
评论暂时关闭