高性能计算(HPC)能部署万兆以太网吗?
高性能计算(HPC)能部署万兆以太网吗?
许多人经常会疑惑:"在高性能计算HPC)中部署万兆以太网会怎样?"据我所知,人们对万兆以太网10GigE)抱有很多负面看法,如恐惧、不确定和疑问等。因此我决定提笔撰写这篇博文,为大家介绍一下10GigE,希望可借此打消您的一些疑虑。
10GigE--背景简介
如果您和我一样对10GigE观察已久,那么就请跟我一起回顾一下它的历史背景吧。自10GigE于2002年实现标准化后,人们便一直期待着它能像千兆以太网一样降价。我也怀有同样的期待,因为我希望家里的集群系统享有更高的网络连接速度。
如果您希望更详细地了解10GigE及各种连接选项,请参考这一链接。许多公司,如Chelsio、Neterion、Netxen、英特尔、Myricom、Broadcom、Mellanox等都可以提供10GigE NICS,同时也有许多具有代表性的交换机厂商,如思科、Force10、Foundry以及一些小型的新兴公司提供此类技术产品。
无需深入细节,我们来简单探讨一下以太网网络。是否还记得TCP无法保证准确交付数据包?实际上这正是它开发出来的原因--一旦数据包掉落或遗失或发生任何意外,TCP协议便可以转发"掉队"的数据包。让我们首先将此协议与InfiniBand进行一个比较:与TCP协议不同,InfiniBand可保证按顺序交付数据包,不会掉落数据包。此外,如果您构建多层以太网网络当您使用大量节点和10GigE时),您将需要确保所有交换机都运行生成树协议。它可以确保避免网络环路,以及到达所有节点。但是,这样会造成大量的延迟通常人们会建议简单的以太网网络关闭生成树,以实现更出色的性能)。
最近,数据中心以太网或 CEE现在是指DCBX数据中心桥接能力交换协议))领域出台了一些新举措,旨在帮助解决主要针对FCoE以太网光纤通道)的以太网网络问题,其中 FcoE要求按顺序交付且需确保数据包不丢失,以提供出色的性能。这同样也适用于HPC环境。例如,DCBX倡议提出增设IEEE标准条款,以支持无损失的TCP传输匹配IB)和更理想的路由机制,从而可减少生成树的影响。不过较为遗憾的是DCBX仍然未得到批准且其规范尚需进一步完善,因此它目前还不能算是一项标准。
介绍完这些基本背景情况后,让我们来了解一下10GigE的性能吧,毕竟HPC最突出的优势在于出色的性能总是很出色)。
10GigE--性能
许多人都希望在HPC中采用10GigE实现计算互连。然而,要实现这一点需要合理考虑两点。首要考虑因素是采用10GigE的应用性能必须足够出色才能物有所值。第二个考虑因素是价格必须足够低才能使大多数人都能购买10GigE系统。尽管价格在一年内不会变化多少,但它会随时出现波动,因此在这里多说无益。但性能是我们可以详加探讨的一个方面,毕竟它不太可能产生太大的变化。
由于TCP是10GigE背后的一个重要推力,因此下面我将谈论与TCP相关的信息。只要是管理员都会了解TCP。他们知道它的工作原理,他们可以使用像 tcpdump一样简单的程序对其进行调试,同时TCP也可以被路由一些客户对此非常感兴趣)。因此,我们将主要讨论使用TCP的10GigE。接下来是有趣的部分--微基准测试。
您可以选择采用几项合理的微基准测试来检测互连性能。当然,微基准测试并不总是性能的指示标,但在未对具体应用进行实际的基准测试时,您只能使用微基准测试进行衡量。随着时间的推移,这些微基准测试也已成为某些代码、甚而某些代码集性能的理想指示标。三大微基准测试为带宽、延迟包括多核延迟调整)和N/2测试。
我认为计算这些微基准测试的最佳工具是netpipe。 Netpipe可以接收两个节点之间传输的数据,并能在节点之间发送任意大小的数据包,测量所需时间。因而,您可以计算出延迟在节点之间传输极小数据包所需的时间)、带宽、每次线下传输的最大数据量想像您沿着电线向各个方向传输数据)以及N/2--您在一个方向上实现全线速传输的最小数据包计算此数据的一种简单方法就是找到相当于最大带宽一半的最小规模数据包)。
以下是netpipe结果的样图。
|
|
| 图1--吞吐率MB/秒)与数据包大小数据块大小)的Netpipe样图 |
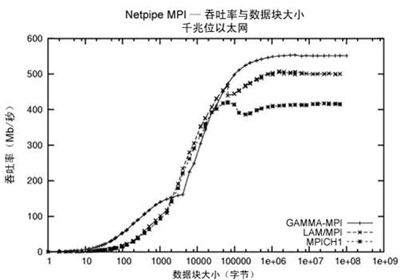
此样图取自使用3个不同MPI库的GigE网络。从此图中,您可以测量带宽图中最高值的一半)和N/2首次实现最高带宽时的数据包大小单位:字节))。
第二个截图如下:
|
|
| 图2--吞吐率与时间的Netpipe样图 |
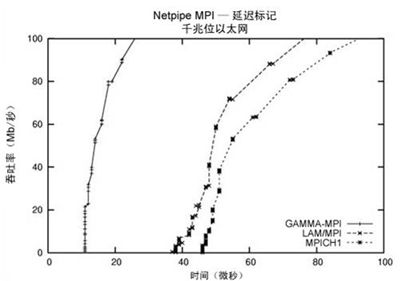
从上图中,您可以确定延迟时间,即处理2字节大小的数据包或极小数据包)的时间。
通常,对于示范配置而言,测量互连的最有效方式是计算延迟、最高带宽和N/2。这意味着在两个节点之间配置一台运行MPI的交换机。之所以称其为最有效是因为其中包含HPCC系统的组成元素--操作系统节点、网卡NIC)、线缆、交换机和软件MPI)。
几名研究人员聚在一起,测试了带有TCP卸载引擎TOE)的Chelsio 10GigE NICT11)。他们不使用交换机)对网卡进行了背靠背测试,同时还使用12端口富士通交换机对网卡进行了测试。他们的测试涉及各个方面,但与HPC最相关的却可能是MPI评估。他们在测试中使用了LAM和1500字节的MTU。他们实现了以下性能:
- 延迟=10.2微秒内置插槽为8.2微秒)
- 带宽= 6.9 Gbps862.5 MB/秒)
- N/2=100,000+字节
不幸的是,本次研究结果是我能找到的关于纯粹TCP 10GigE解决方案的唯一公布的完整结果。这些结果有些过时2005年),但目前没有比这个更完整的结果了。不过,互联网上仍然还有与此相关的其它零散的性能数据。例如,Mellanox拥有一个可以在本地运行TCP的ConnectX HCA版本。您可以在此站点上找到一些性能信息,尤其是下列信息:
- MTU=1500时带宽=9.5 Gbps1187.5 MB/秒)
- MTU=9000时带宽=9.9 Gbps1237.5 MB/秒)
延迟和N/2结果均没有列出。此外,上述测试使用了TCP而不是MPI完成。
10GigE--观察结果
我认为比较10GigE与IB的性能是值得的。与这一站点一样,Mellanox也拥有一些性能数据,从这些数据中我们会发现DDR IB具有以下性能:
- 延迟=低于1微秒
- 带宽=3000 MB/秒使用PCI-e Gen 1的InfiniBand DDR)、3800 MB/秒使用PCI-e Gen2的InfiniBand DDR)和6600MB/秒使用PCIe Gen2的InfiniBand QDR)。这些都是双向BW数据。
- N/2=480字节
如果我们将上述结果与10GigE进行比较,会发现此时DDR和QDR IB比10GigE的性能更出色。最近我们也看到QDR四倍数据速率)IB的出现会提高带宽,但不太可能会对初次部署的延迟或N/2造成重要影响。然而,这些都是微基准测试,虽然能够预测性能,但却不能取代针对应用的正式测试。
我同意不讨论变化不定的价格,但在通常情况下,对于适当大小的集群超过32个节点),10GigE的每端口成本目前远高于IB。
10GigE会融入HPC吗?
本部分的标题有些挑衅意味,因为我认为答案是肯定的。但至于"何时"以及"在多大程度上"融入HPC则仍然是个问题。目前,在普通的微基准测试中,10GigE并不具备与IB相同的性能水平。此外,其性能也不可能大幅度提高,它仍然存在大约8-10微秒的延迟,带宽大约为1,100-1,200 MB/秒。不过,10GigE确实存在改进N/2的空间,而且极有可能实现这一点我只是希望有人能够公布一些更新的数据)。
此外,使用TCP还会带来一些问题,如不能拥有无损失的网络或在引入生成树时带来更多延迟等。DCE在这些方面倒是可以提供一臂之力,但在它成为一项标准之前,它都不会对HPC产生多大效用。
那么,我有什么建议呢?理想的情况是,您应该在各种网络上测量应用,以衡量性能,尤其是观察随着HPC系统越来越大而不是越来越小时应用的扩展情况即人们每年会在更多内核上运行计算机)。但此时面向10GigE的微基准测试结果并不是最佳水平,也不会达到Infiniband的性能水平。目前,10GigE的高昂成本阻碍了其在HPC环境中的广泛应用。
我等待了至少4年希望看到10Gige的价格下降。我仍然在等待,但不幸的是年纪越来越大。与此同时,InfiniBand已经变成了HPC中的主要网络。其性能得到了大幅提升,价格也已经下降至大约一个节点250美元,适用于更小型的系统。在我看来,10GigE如果想成为通用HPC网络,还有很长的路要走。
- 超微X38芯片组服务器主板板亮相日本
- 超微推出全球最密集四核皓龙刀片
评论暂时关闭