小米运维—互联网企业级监控系统实践(1)(2)
Data collection
transfer,接收客户端发送的数据,做一些数据规整,检查之后,转发到多个后端系统去处理。在转发到每个后端业务系统的时候,transfer会根据一致性hash算法,进行数据分片,来达到后端业务系统的水平扩展。
transfer 提供jsonRpc接口和telnet接口两种方式,transfer自身是无状态的,挂掉一台或者多台不会有任何影响,同时transfer性能很高,每分钟可以转发超过500万条数据。
transfer目前支持的业务后端,有三种,judge、graph、opentsdb。judge是我们开发的高性能告警判定组件,graph是我们开发的高性能数据存储、归档、查询组件,opentsdb是开源的时间序列数据存储服务。可以通过transfer的配置文件来开启。
transfer的数据来源,一般有三种:
● falcon-agent采集的基础监控数据
● falcon-agent执行用户自定义的插件返回的数据
● client library:线上的业务系统,都嵌入使用了统一的perfcounter.jar,对于业务系统中每个RPC接口的qps、latency都会主动采集并上报
说明:上面这三种数据,都会先发送给本机的proxy-gateway,再由gateway转发给transfer。
Alerting
报警判定,是由judge组件来完成。用户在web portal来配置相关的报警策略,存储在MySQL中。heartbeat server 会定期加载MySQL中的内容。judge也会定期和heartbeat server保持沟通,来获取相关的报警策略。
heartbeat sever不仅仅是单纯的加载MySQL中的内容,根据模板继承、模板项覆盖、报警动作覆盖、模板和hostGroup绑定,计算出最终关联到每个endpoint的告警策略,提供给judge组件来使用。
transfer转发到judge的每条数据,都会触发相关策略的判定,来决定是否满足报警条件,如果满足条件,则会发送给alarm,alarm再以邮件、短信、米聊等形式通知相关用户,也可以执行用户预先配置好的callback地址。
用户可以很灵活的来配置告警判定策略,比如连续n次都满足条件、连续n次的最大值满足条件、不同的时间段不同的阈值、如果处于维护周期内则忽略 等等。
Query
到这里,数据已经成功的存储在了graph里。如何快速的读出来呢,读过去1小时的,过去1天的,过去一月的,过去一年的,都需要在1秒之内返回。
这些都是靠graph和query组件来实现的,transfer会将数据往graph组件转发一份,graph收到数据以后,会以rrdtool的数据归档方式来存储,同时提供查询RPC接口。
query面向终端用户,收到查询请求后,会去多个graph里面,查询不同metric的数据,汇总后统一返回给用户。
Dashboard
dashboard首页,用户可以以多个维度来搜索endpoint列表,即可以根据上报的tags来搜索关联的endpoint。
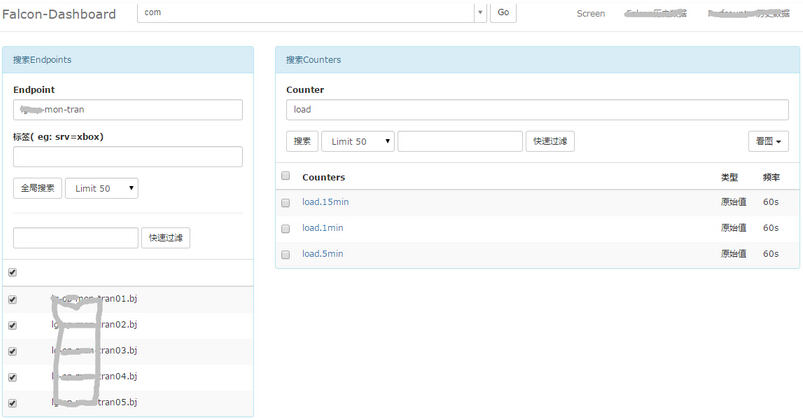
open-falcon dashboard homepage
用户可以自定义多个metric,添加到某个screen中,这样每天早上只需要打开screen看一眼,服务的运行情况便尽在掌握了。
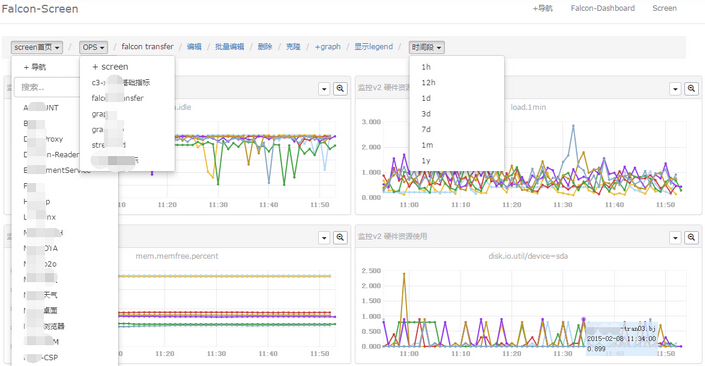
open-falcon dashboard screen
当然,也可以查看清晰大图,横坐标上zoom in/out,快速筛选反选。总之用户的“使用效率”是第一要务。
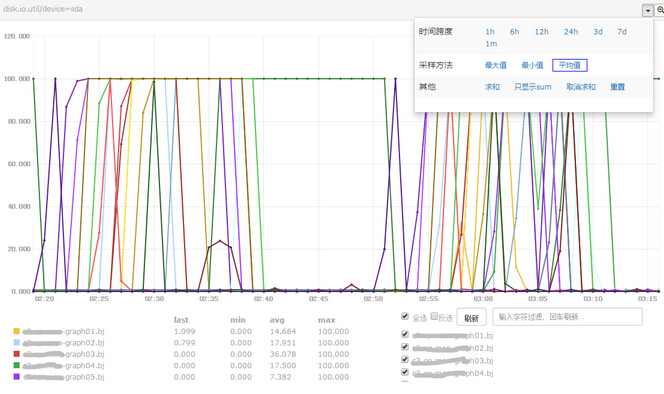
open-falcon big graph

评论暂时关闭