Hadoop中的Bloom Filter布隆过滤器介绍
Hadoop中的Bloom Filter布隆过滤器介绍
布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制矢量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
链表树散列表
优点

缺点
散列函数
散列函数(或散列算法,又称哈希函数,Hash Function)是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值的指纹。散列值通常用来代表一个短的随机字母和数字组成的字符串。好的散列函数在输入域中很少出现散列冲突。在散列表和数据处理中,不抑制冲突来区别数据,会使得数据库记录更难找到。
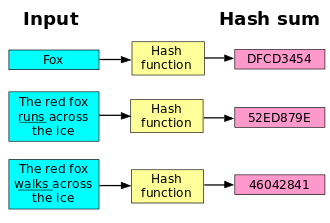
散列函数的性质
确定性
散列函数的应用
加密散列函数MD5
加密散列函数
确保传递真实的信息
散列表
关键字查找数据记录。(注意:关键字不是像在加密中所使用的那样是秘密的,但它们都是用来“解锁”或者访问数据的。)例如,在英语字典中的关键字是英文单词,和它们相关的记录包含这些单词的定义。在这种情况下,散列函数必须把按照字母顺序排列的字符串映射到为散列表的内部数组所创建的索引上。
, , ,等等这样的文件名映射到表的连续指针上,也就是说这样的串行不会发生冲突。相比之下,对于一组好的关键字性能出色的随机散列函数,对于一组坏的关键字经常性能很差,这种坏的关键字会自然产生而不仅仅在攻击中才出现。性能不佳的散列函数表意味着查找操作会退化为费时的线性搜索。
错误校正与检测
语音识别
Rabin-Karp字符串搜索算法
Rabin-Karp字符串搜索算法字符串搜索算法O(n)
评论暂时关闭