【中文摘要】用Redshift驱动交互式数据分析 Powering Interactive Data Analysis by Redshift
【中文摘要】用Redshift驱动交互式数据分析 Powering Interactive Data Analysis by Redshift
|
来源 |
Pinterest blog |
|
时间 |
2014-01-31 |
|
作者 |
Jie Li |
|
URL |
http://engineering.pinterest.com/post/75186894499/powering-interactive-data-analysis-by-redshift |
|
Ppt |
http://www.slideshare.net/JieLi4/amazon-redshift-at-pinterest |
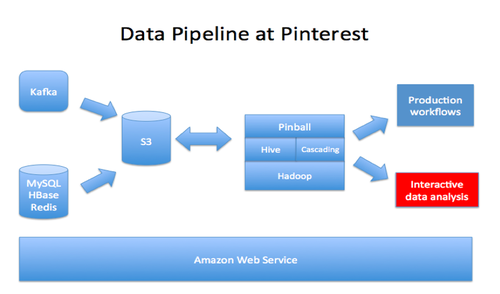
Hadoop每天处理10T的数据量,Redshift每天处理百亿条记录。Redshift提供了很好的交互性,而hive同样的hive查询通常需要几分钟或几小时。
(译注:hadoop直接输出到redshift,还是通过s3转存,图上没有画出)
(译注:pinball是作业调度系统,详见http://engineering.pinterest.com/post/74429563460/pinball-building-workflow-management)
挑战1:数据从hive到redshift的载入
1. python脚本生成hive语句,用于根据schema映射,输出到redshift。
2. 两种载入方式的比较:
a)分天载入到一张表,每天vacuum。
b)每天建立一张表,建立视图帮助查询。(redshift对视图查询的优化不够,比如limit的下推)
所以应该采用的是a方案
3. hive中大表(20Billion,10TB)的快照十分耗时,于是在hive中对大表进行分区,分块载入到redshift。(译注:这个的意思是分块载入到多个集群中?因为快照的单位都是集群)
4. 过期数据的删除采用将保留数据插入新表的方式,比删除后vacuum或重新导入的效率都要高。
5. 由于s3是最终一致性(Eventual Consistency),导入数据可能不一致。我们合并了小文件,并在载入数据时加入了检查,现在数据不一致的情况小于0.0001%。
(译注:s3不一致的情况应该在写后马上读的情况,从图上看发生在hive读取s3数据的过程中,或hive输出redshift的转存过程中)
6. 需要对非ascii码数据进行过滤
(译注:redshift官方开发手册中提到可以用varchar存储utf-8格式数据)
7. sort key数据的导入,需要先在hive中进行排序,乱序数据可能增加vacuum负担
挑战2:加速
1.通常redshift可以有50倍以上的加速,但有时也会发生一个小时的长查询,对性能瓶颈的调试可以通过query plan和query 统计。
2.得到的教训是多更新statistic(analyze命令),对查询优化非常重要。选用合适的sort key和distribute key,不合适的distribute key会导致数据倾斜问题(比如空值)。
3. 对超过20分钟的查询进行监控,并发邮件给工程师。
4. 对查询语句有如下的最佳实践准则:
a)只选择有用的行,避免select *(最重要)
b)多用sort key,过滤不必要数据
c)避免客户端传大量数据,写到一个表里用命令行下载
d)做join前仅可能多过滤无效数据
e)避免并行查询
f)慢查询用explain分析性能瓶颈
5. 曾经把一个3小时的查询变成7秒。就是通过query plan查到把一张大表做了broadcast join。
挑战3:面对更多用户和查询的压力
1. 避免在查询高峰期做copy操作,可以暂停过了高峰期再继续
2. 给查询加上超时功能
3. 定期备份记录用户行为的系统表(默认每周清一次)
最后:现状和展望
1. 16-nodehs1.8xlarge,256T容量,大约100T数据,每天数据量1TB(过期数据会删除),100用户,300-500次查询,75%的查询在35秒内完成。
2. 以后用redshift换掉mysql,并和tableau dashboard联动
存在的风险:
1. 没有抢占,重要任务可能被拖延。
(译注:redshift支持多个查询队列,如果是kill query这种操作肯定是可以在super user队列中完成的,可能作者指的是还是需要一定时间的查询)
2. 从快照恢复需要时间,未来可能热备一个集群。
来自ppt的补充:
1. 公司从2013年6月开始使用redshift。
2. 费用:0.85刀每小时,3年合约机1000刀每TB每年,免费s3备份空间(和集群相等的)
评论暂时关闭