Apache Kafka-0.8.1.1源码编译
作者:过往记忆 | 新浪微博:左手牵右手TEL |
可以转载, 但必须以超链接形式标明文章原始出处和作者信息及版权声明
博客地址:http://www.iteblog.com/
文章标题:《Apache Kafka-0.8.1.1源码编译》
本文链接:http://www.iteblog.com/archives/1044
Hadoop、Hive、Hbase、Flume等QQ交流群:138615359(已满),请加入新群:149892483
本博客的微信公共帐号为:iteblog_hadoop,欢迎大家关注。
如果你觉得本文对你有帮助,不妨分享一次,你的每次支持,都是对我最大的鼓励
| 
欢迎关注微信公共帐号 |
经过近一个月时间,终于差不多将之前在Flume 0.9.4上面编写的source、sink等插件迁移到Flume-ng 1.5.0,包括了将Flume 0.9.4上面的TailSource、TailDirSource等插件的迁移(当然,我们加入了许多新的功能,比如故障恢复、日志的断点续传、按块发送日志以及每个一定的时间轮询发送日志而不是等一个日志发送完才发送另外一个日志)。现在我们需要将Flume-ng 1.5.0和最新的Kafka-0.8.1.1进行整合,今天这篇文章主要是说如何编译Kafka-0.8.1.1源码。
在讲述如何编译Kafka-0.8.1.1源码之前,我们先来了解一下什么是Kafka:
Kafka is a distributed, partitioned, replicated commit log service. It provides the functionality of a messaging system, but with a unique design.(Kafka是一个分布式的、可分区的(partitioned)、基于备份的(replicated)和commit-log存储的服务.。它提供了类似于messaging system的特性,但是在设计实现上完全不同)。kafka是一种高吞吐量的分布式发布订阅消息系统,它有如下特性:
(1)、通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)、高吞吐量:即使是非常普通的硬件kafka也可以支持每秒数十万的消息。
(3)、支持通过kafka服务器和消费机集群来分区消息。
(4)、支持Hadoop并行数据加载。
官方文档中关于kafka分布式订阅架构如下图:
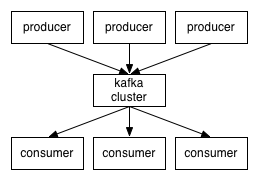
欢迎关注微信公共帐号
好了,更多关于Kafka的介绍可以去http://kafka.apache.org/里面查看。现在我们正入正题,说说如何编译 Kafka-0.8.1.1,我们可以用Kafka里面自带的脚本进行编译;我们也可以用sbt进行编译,sbt编译有点麻烦,我将在文章的后面进行介绍。
一、用Kafka里面自带的脚本进行编译
下载好了Kafka源码,里面自带了一个gradlew的脚本,我们可以利用这个编译Kafka源码:
2 | # tar -zxf kafka-0.8.1.1-src.tgz |
4 | # ./gradlew releaseTarGz |
运行上面的命令进行编译将会出现以下的异常信息:
01 | :core:signArchives FAILED |
03 | FAILURE: Build failed with an exception. |
06 | Execution failed for task ':core:signArchives'. |
07 | > Cannot perform signing task ':core:signArchives' because it |
08 | has no configured signatory |
11 | Run with --stacktrace option to get the stack trace. Run with |
12 | --info or --debug option to get more log output. |
这是一个bug(https://issues.apache.org/jira/browse/KAFKA-1297),可以用下面的命令进行编译
1 | ./gradlew releaseTarGzAll -x signArchives |
这时候将会编译成功(在编译的过程中将会出现很多的)。在编译的过程中,我们也可以指定对应的Scala版本进行编译:
1 | ./gradlew -PscalaVersion=2.10.3 releaseTarGz -x signArchives |
编译完之后将会在core/build/distributions/里面生成kafka_2.10-0.8.1.1.tgz文件,这个和从网上下载的一样,可以直接用。
二、利用sbt进行编译
我们同样可以用sbt来编译Kafka,步骤如下:
03 | # git checkout -b 0.8 remotes/origin/0.8 |
05 | [info] [SUCCESSFUL ] org.eclipse.jdt#core;3.1.1!core.jar (2243ms) |
06 | [info] downloading http: |
07 | [info] [SUCCESSFUL ] ant#ant;1.6.5!ant.jar (1150ms) |
09 | [info] Resolving org.apache.hadoop#hadoop-core;0.20.2 ... |
11 | [info] Resolving com.yammer.metrics#metrics-annotation;2.2.0 ... |
13 | [info] Resolving com.yammer.metrics#metrics-annotation;2.2.0 ... |
15 | [success] Total time: 168 s, completed Jun 18, 2014 6:51:38 PM |
18 | [info] Set current project to Kafka (in build file:/export1/spark/kafka/) |
19 | Getting Scala 2.8.0 ... |
20 | :: retrieving :: org.scala-sbt#boot-scala |
22 | 3 artifacts copied, 0 already retrieved (14544kB/27ms) |
23 | [success] Total time: 1 s, completed Jun 18, 2014 6:52:37 PM |
对于Kafka 0.8及以上版本还需要运行以下的命令:
01 | # ./sbt assembly-package-dependency |
02 | [info] Loading project definition from /export1/spark/kafka/project |
03 | [warn] Multiple resolvers having different access mechanism configured with |
04 | same name 'sbt-plugin-releases'. To avoid conflict, Remove duplicate project |
05 | resolvers (`resolvers`) or rename publishing resolver (`publishTo`). |
06 | [info] Set current project to Kafka (in build file:/export1/spark/kafka/) |
07 | [warn] Credentials file /home/wyp/.m2/.credentials does not exist |
08 | [info] Including slf4j-api-1.7.2.jar |
09 | [info] Including metrics-annotation-2.2.0.jar |
10 | [info] Including scala-compiler.jar |
11 | [info] Including scala-library.jar |
12 | [info] Including slf4j-simple-1.6.4.jar |
13 | [info] Including metrics-core-2.2.0.jar |
14 | [info] Including snappy-java-1.0.4.1.jar |
15 | [info] Including zookeeper-3.3.4.jar |
16 | [info] Including log4j-1.2.15.jar |
17 | [info] Including zkclient-0.3.jar |
18 | [info] Including jopt-simple-3.2.jar |
19 | [warn] Merging 'META-INF/NOTICE' with strategy 'rename' |
20 | [warn] Merging 'org/xerial/snappy/native/README' with strategy 'rename' |
21 | [warn] Merging 'META-INF/maven/org.xerial.snappy/snappy-java/LICENSE' |
23 | [warn] Merging 'LICENSE.txt' with strategy 'rename' |
24 | [warn] Merging 'META-INF/LICENSE' with strategy 'rename' |
25 | [warn] Merging 'META-INF/MANIFEST.MF' with strategy 'discard' |
26 | [warn] Strategy 'discard' was applied to a file |
27 | [warn] Strategy 'rename' was applied to 5 files |
28 | [success] Total time: 3 s, completed Jun 18, 2014 6:53:41 PM |
当然,我们也可以在sbt里面指定scala的版本:
07 | 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货 |
08 | 过往记忆博客微信公共帐号:iteblog_hadoop |
12 | sbt "++2.10.3 assembly-package-dependency" |
本文地址:《Apache Kafka-0.8.1.1源码编译》:http://www.iteblog.com/archives/1044,过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量的干货.过往记忆博客微信公共帐号:iteblog_hadoop本博客文章除特别声明,全部都是原创!
尊重原创,转载请注明: 转载自过往记忆(http://www.iteblog.com/)
本文链接地址: 《Apache Kafka-0.8.1.1源码编译》(http://www.iteblog.com/archives/1044)
E-mail:wyphao.2007@163.com
评论暂时关闭