Maven构件Hadoop1.x以及Hadoop2.x项目,mavenhadoop1.x
Maven构件Hadoop1.x以及Hadoop2.x项目,mavenhadoop1.x
参看文档
http://blog.csdn.net/tryhl/article/details/43967441
也可以关注我的另外一篇文章http://www.aboutyun.com/blog-12709-1768.html
也可以加入群 316297243一起学习讨论
此文章用于学习和交流,转载请注明
1 Hadoop1.x的Maven项目构建
怎么用Maven构建项目,以及怎么构建hadoop项目,这里就不详细介绍,详情请参考
http://blog.csdn.net/tryhl/article/details/43967441
这里只讲述在用maven构建hadoop1.x项目以及导入Eclipse运行需要注意的问题以及产生的问题。
1)修改pom.xml文件
我依赖的是hadoop-1.2.1版本的
加入如下依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>加入依赖之后等待下载相关的jar包
2)从hadoop集群中下载配置文件
这里不加也行
下载配置文件:
core-site.sh
hdfs-site.sh
mapred-site.sh
把配置文件加入/main/java/resources/hadoop文件夹下
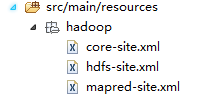
3) 加入WordCount源码
public class WordCount {
public static class WordCountMapper extends MapReduceBase implements
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class WordCountReducer extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
// TODO Auto-generated method stub
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
String input = null;
String output = null;
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("WordCount");
// 测试环境
if (args == null || args.length < 2) {
input = "hdfs://10.2.1.35:9000/usr/hdfs/input_test1";
output = "hdfs://10.2.1.35:9000/usr/hdfs/test1_result";
/ 加载配置文件,可以注释掉
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
} else {
// 正式环境
input = args[0];
output = args[1];
}
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(WordCountMapper.class);
conf.setCombinerClass(WordCountReducer.class);
conf.setReducerClass(WordCountReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
System.exit(0);
}
}注:
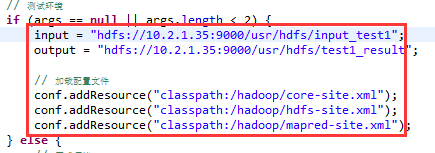
上述代码根据自己的实际情况编写
4)运行
出现异常
严重: PriviledgedActionException as:liuhuan cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-liuhuan\mapred\staging\liuhuan1095504605\.staging to 0700
Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-liuhuan\mapred\staging\liuhuan1095504605\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:691)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:664)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:514)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:349)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:193)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:126)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:942)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:910)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1353)
at com.lvmama.vst.mr.kpi.WordCount.main(WordCount.java:96)
这个错误是win中开发特有的错误,文件权限问题,在Linux下可以正常运行。
解决方法是,修改/hadoop-1.2.1/src/core/org/apache/hadoop/fs/FileUtil.java文件
690-694行注释,然后重新编译源代码,重新打一个hadoop.jar的包
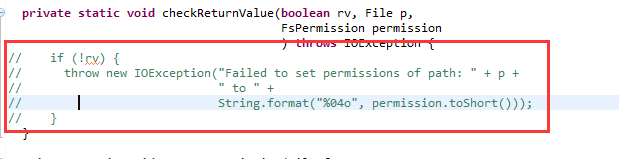
再次运行
: PriviledgedActionException as:liuhuan cause:org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security.AccessControlException: Permission denied: user=liuhuan, access=READ, inode="input_test1":root:supergroup:rw-r-----
Exception in thread "main" org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security.AccessControlException: Permission denied: user=liuhuan, access=READ, inode="input_test1":root:supergroup:rw-r-----
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:39)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:27)
at java.lang.reflect.Constructor.newInstance(Constructor.java:513)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:95)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:57)
at org.apache.hadoop.hdfs.DFSClient.callGetBlockLocations(DFSClient.java:697)
at org.apache.hadoop.hdfs.DFSClient.getBlockLocations(DFSClient.java:716)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileBlockLocations(DistributedFileSystem.java:156)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:231)
at org.apache.hadoop.mapred.JobClient.writeOldSplits(JobClient.java:1081)
at org.apache.hadoop.mapred.JobClient.writeSplits(JobClient.java:1073)
at org.apache.hadoop.mapred.JobClient.access$700(JobClient.java:179)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:983)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:396)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:910)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1353)
at com.lvmama.vst.mr.kpi.WordCount.main(WordCount.java:96)
文件没有访问权限,由于我们访问是用window的用户名访问,和集群的用户名并不一样,所以没有访问权限。有三种解决方案,常用的是在hdfs-site.sh中加入
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>不知道你们行不行,试了几次都不行。
没必要在这花费时间,使用hadoop fs -chmod -R 777 /修改权限(这里只能在测试环境这么干)
也可以修改Window的用户名
运行输出即可。
2 hadoop2.x.x的Maven项目构建
本文以2.6.0为例
Maven构建项目上面已经有了,在这不赘述了。
1)直接修改pom.xml文件
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
<exclusions>
<exclusion>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.6</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency> 上述的jdk.tools如果不这样写会报错。
2)加入上述的代码,运行
但是2.6.0不会出现这么多错误,只会出现一个错误。
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:557)
at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977)
at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:187)
at org.apache.hadoop.util.DiskChecker.checkDirAccess(DiskChecker.java:174)
at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:108)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:285)
at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:344)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:150)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:131)
at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:115)
at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:131)
at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:163)
at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:731)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:536)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1296)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1293)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1293)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:833)
at com.lvmama.vst.kpi.mr.WordCount.main(WordCount.java:96)
然后把NativeIO的557行注释掉,修改如下
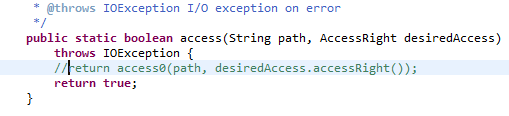
再次运行就可以了。
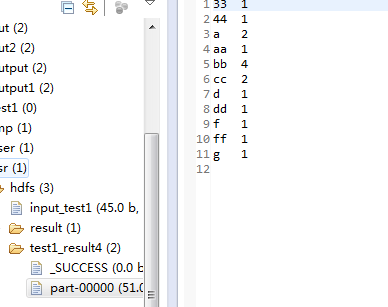
注:在Eclipse运行中,如果不出现运行日志,则把hadoop配置文件夹下的log.properties放在项目的/src/main/resources,即可
评论暂时关闭