mahou之朴素贝叶斯算法思想,mahou贝叶斯算法
mahou之朴素贝叶斯算法思想,mahou贝叶斯算法
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类
对于分类问题,其实谁都不会陌生,每个人生活中无时不刻的在进行着分类。例如,走在大马路上看到女孩子,你会下意识的将她分为漂亮和不漂亮(漂亮当然就多看几眼啦)。在比如,在路上遇到一只狗,你会根据这只狗的毛发脏不脏,然后想到这是一只流浪狗还是家养的宠物狗。这些其实都是生活中的分类操作。
而贝叶斯分类是在生活中分类的基础上加以概率数学来规定定义的一种分类方式
其基本概率公式为:
怎么理解这个公式呢,这里假设你没有概率数学的基础,或者说学过概率只是很久没用已经忘得差不多了(比如我。。。重新拿起大二的概率统计课本翻了一遍)
首先解释什么是条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。
求解这个概率的基本求解公式为:。
假设AB两个事件是相互独立的(就是说AB两个事件谁发生都不影响谁,比如,同学A在北京感冒了,我在福建感冒了,两个事件是互不影响的)
事件B发生的前提下 A发生的概率=事件AB同时发生的概率/事件B发生的概率
一般在生活中,P(A|B)发生的概率我们很容易的就可以求得,但是要返回来求P(B|A)怎么办?
这就要用到贝叶斯公式了
根据这个公式我们可以再P(A|B)的基础上对P(B|A)进行计算,贝叶斯公式提供了人们一种可以根据结果来计算某个条件的前提下某个事件发生的概率
以上基础知识交代完毕,下面进入正题
朴素贝叶斯分类是贝叶斯分类中的一种十分简单的分类算法,看到朴素两个字就知道这种贝叶斯分类肯定很乡村~,用通俗的话来讲就是:你在国外旅游,遇见一个说中文的黄种人,那么你肯定会想,老乡啊!中国人!为啥?因为在国外遇到讲中文的大概都是中国人吧,只有一部分人是华侨或者其他国籍的华人,因为是中国人的概率最高,所以我们会认为他就是中国人,这就是朴素贝叶斯的思想。
朴素贝叶斯的思想严格的定义是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。其中在求解某个待分类项出现的条件下,各个类别出现的概率时,一般是根据该待分类项的特征属性来求的。
怎么理解呢,比如在什么艺校或者空乘的招聘现场,那肯定有n多女孩子,这些女孩子就是待分类项,而女孩子在我们眼中一般只是分为漂亮和不漂亮两种,这两种就是类别,现在用朴素贝叶斯算法来对这n个女孩子进行分类。
女孩集合={x1,x2.....xn}----->此为待分类项
类别集合={漂亮,不漂亮}
首先我们要找出女孩子的一些特征属性,比如脸蛋,身材等(假设就根据这两个特征来判断)
对于女孩的特征属性={脸蛋,身材}
对于其中一个女孩子,求此项出现的条件下各个类别出现的概率,一般是根据该待分类项的特征属性来求的,意思就是说,要根据这个女孩子的脸蛋(好看或者不好看)分别求出 在此脸蛋出现的前提下 是漂亮和不漂亮的概率;根据这个女孩子的身材(高矮胖瘦)分别求出 在此身材的前提下 是漂亮和不漂亮的概率。
但是,就比如说,一个在深山野林总生活了几十年从未见过女人的野人来说,如果他出山碰到一个女人,这个女人是他这辈子见到的第一个女人,那他凭什么来说这个女人是漂亮还是不漂亮的呢?根据脸蛋和身材?但是注意前提:这个野人之前从未见过女人,可能发生的情况是就算这个女人很丑,由于野人没有见过女人,他也会觉得很漂亮很性感,有一种莫名的吸引力
如上所说,生活中许许多多的判断都是建立在有经验的基础之上,正是因为我们周围有很多女同志,而且我们能够通过网络来看到更多的漂亮女孩子,所以我们能够在路上判断一个女孩是否漂亮
而之前我们要计算的 :要根据这个女孩子的脸蛋(好看或者不好看)分别求出 在此脸蛋出现的前提下 是漂亮和不漂亮的概率;根据这个女孩子的身材(高矮胖瘦)分别求出 在此身材的前提下 是漂亮和不漂亮的概率。
我们首先要有“经验”才能计算,所以我们需要一个女孩集合,然后分别对其的脸蛋和身材进行判断,得出这个女孩是否漂亮。这个女孩集合称为训练样本,没有训练样本贝叶斯分类将无法工作,因为它不知道如何判断
那么假设:我们处理完训练样本之后得到以下数据(这个过程为人为处理的,也是贝叶斯分类中唯一一个人为处理的步骤)
P(漂亮|脸蛋好看)=0.9
P(漂亮|脸蛋不好看)=0.1
P(漂亮|身材高)=0.6
P(漂亮|身材矮)=0.4
P(漂亮|身材胖)=0.3
P(漂亮|身材瘦)=0.5
P(不漂亮|脸蛋好看)=0.1
P(不漂亮|脸蛋不好看)=0.9
P(不漂亮|身材高)=0.4
P(不漂亮|身材矮)=0.7
P(不漂亮|身材胖)=0.8
P(不漂亮|身材瘦)=0.3
P(漂亮)=0.6
P(不漂亮)=0.4
我们得到的数据为在各个类别的前提下,各个特征属性出现的概率
这时候,如果给出一个女孩x1,脸蛋好看,身材矮,瘦,贝叶斯分类就可以根据训练样本的数据来判断x1是否漂亮
根据贝叶斯定理:
P(漂亮|女孩x1)=P(女孩x1|漂亮)*P(漂亮)/P(女孩x1)
P(不漂亮|女孩x1)=P(女孩x1|不漂亮)*P(不漂亮)/P(女孩x1)
由于P(女孩x1)对于所有类别(漂亮,不漂亮)是个常数,所以将分子最大化即可,变形如下:
P(女孩x1|漂亮)*P(漂亮)=P(漂亮|女孩x1)=P(漂亮|脸蛋好看)*P(漂亮|身材矮)*P(漂亮|身材瘦)*P(漂亮)=0.9*0.4*0.5*0.6=0.018
P(女孩x1|不漂亮)*P(不漂亮)=P(不漂亮|女孩x1)=P(不漂亮|脸蛋好看)*P(不漂亮|身材矮)*P(不漂亮|身材瘦)*P(不漂亮)=0.1*0.7*0.3*0.4=0.084
由于0.084>0.018
所以贝叶斯分类会将女孩x归入不漂亮的类别中
由于所有的数据都是假设的,所以结果不准确那是肯定的(因为我自己觉得脸蛋好看,身材矮,瘦应该是属于漂亮的。。最后计算出来竟然是相反的)
从这里面可以知道,训练样本和特征属性的划分对于贝叶斯分类是十分重要的!这将决定整个贝叶斯分类器计算结果的准确性
总结一下之前的例子中,贝叶斯分类的处理过程
朴素贝叶斯分类的正式定义如下:
1、设为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合。
3、计算。
4、如果,则
。
那么现在的关键就是如何计算第3步中的各个条件概率。
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即。
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
根据上述分析,朴素贝叶斯分类的流程可以由下图表示:
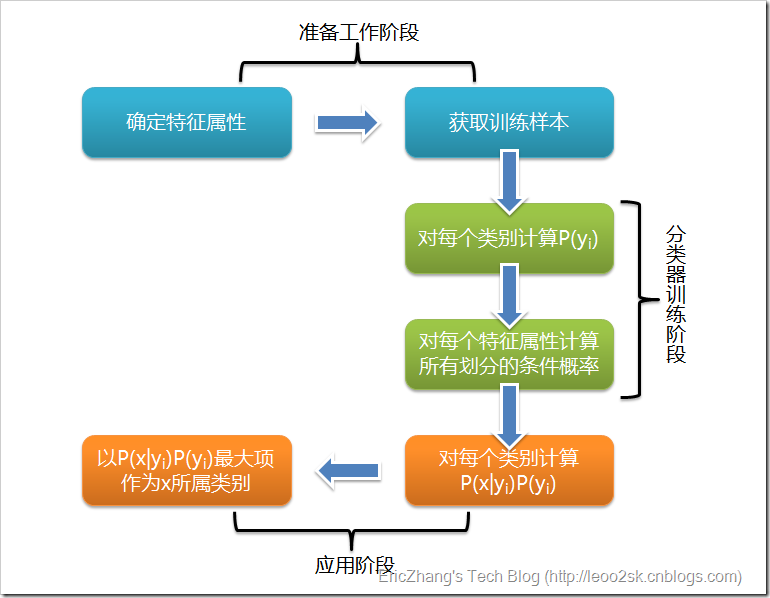
可以看到,整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
训练完毕之后的贝叶斯分类器就可以处理我们交给他的任何数据,并根据训练结果将其分类以上有些段落摘选自算法杂货铺——分类算法之朴素贝叶斯分类(Naive Bayesian classification)
作者写的比较有才华也比较深奥,建议去看看,本文仅作笔记之用
评论暂时关闭