【Spark1.3官方翻译】Spark集群模式概览,spark1.3spark
【Spark1.3官方翻译】Spark集群模式概览,spark1.3spark
英文标题:Cluster Mode Overview
英文原址:http://spark.apache.org/docs/latest/cluster-overview.html
Spark Version:1.3.1(2015-04-17)
1, Spark核心组件
Spark应用程序作为一个独立的任务集运行在集群上,由主程序(driver program)中的SparkContext来协调控制。当运行在集群上时,SparkContext可以连接到不同的集群管理器(Spark自带的Standalone或Mesos/YARN),由它们为应用程序分配资源。一旦连接上集群管理器,Spark就开始请求Worker节点上的Executors(Executors是用来执行计算任务、存储数据的进程),然后将你的应用程序代码(传给SparkContext的Jar包或Python文件)发送给Executors,最后SparkContext将任务发送给Executors去执行。
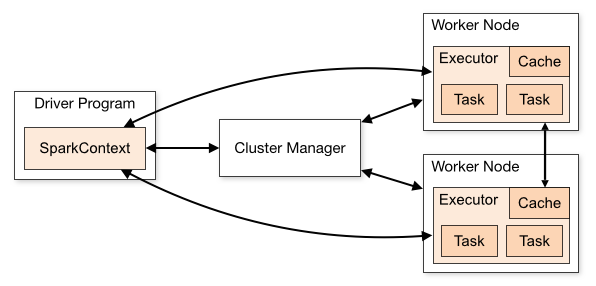
对于以上这个框架有一些值得一提的点:
2, 集群管理器类型
系统目前支持3个集群管理器:
- Standalone,Spark自带的集群管理器,用这种方式很容易安装集群;
- Apache Mesos,一个既可以运行Hadoop MapReduce也可以运行服务应用-程序的通用集群管理器;
- Hadoop Yarn,Hadoop 2中的资源管理器。
此外,Spark的“EC2启动脚本”可以很轻松的在Amazon EC2上启动一个Standalone集群。
3, 提交应用程序
应用程序可以用spark-submit脚本提交给任何一类集群,《【Spark1.3官方翻译】 Spark Submit提交应用程序》描述了如何提交应用程序。
4, 监控
每个主程序都有一个web UI,端口是4040。它显示了正在运行的任务、Executors、存储情况的信息。简单地在浏览器的地址栏中输入http://:4040就可以访问。《【Spark1.3.1官方翻译】 Monitoring Guide监控》描述了这些监控选项。
5, 作业调度
Spark对跨应用程序(在集群管理器级别)和应用程序内(同一个SparkContext中产生的多个计算)的资源分配进行了控制。《【Spark1.3.1官方翻译】 Job Scheduling Overview作业调度概述》进行详细描述。
6, 组件表
下面汇总了涉及到集群概念中的一些术语:
- Application,在Spark上构建的用户程序,由Driver Program和集群中的Executors构成。
- Application Jar,Jar包含了用户的Spark应用程序,某些情况下,用户想创建uber jar来包含应用程序的依赖。用户的Jar决不应该包括Hadoop或Spark的库,因为这些库在运行时会自动添加。
- Driver Program,运行应用程序的main()函数的进程,并由它创建SparkContext。
- Cluster Manager,集群中用于请求资源的外部服务。
-Deploy Mode,用来区分Driver进程运行在哪,“Cluster”模式中,在集群内启动Driver,“Client”模式中,由集群外的作业提交者启动Driver。 - Worker Node,集群中任意可运行应用程序代码的节点。
- Executor,在Worker节点为应用程序启动的工作进程,由它来执行任务,将数据跨节点保存在内存中或硬盘上。每个应用程序都有自己的Executors。
- Task,发送给一个Executor的工作单元。
- Job,由Spark的action操作触发的多任务组成的并行计算,可以在Driver日志中看到这个术语。
- Stage,每个Job被分成小的任务集就叫做Stage,它们之间相互依赖(类似于MapReduce中的map和reduce阶段),也可以在Driver日志中看到这个术语。
评论暂时关闭