Logtail 文件日志采集之完整正则模式,logtail日志
Logtail 文件日志采集之完整正则模式,logtail日志
前言
为了简化文件日志的采集过程,Logtail 提供了按行采集的极简模式:通过换行符来切分日志,每行作为一条日志。极简模式具有高效、配置简单等优势,但它将整条日志的内容作为整体,而不会对单条日志的内容进行额外解析,在有些场景下无法满足需求。为此,我们还提供了其他解析方式,例如:分隔符模式、完整正则模式、JSON 模式等。
本文将介绍如何使用完整正则模式来实现对日志的解析,并且介绍一些使用此模式时的最佳实践。
完整正则模式
简介
完整正则模式是通过正则表达式实现的日志解析。正则表达式是用于匹配字符串中字符组合的模式,通俗来讲,我们可以通过它来表达我们要什么样的日志。正则表达式具有多个规范,包括 Posix、Perl 等,Logtail 的完整正则模式所支持的语法符合 Perl 正则(PCRE)规范(本文后续内容中所涉及的正则表达式都会采用该规范编写)。

如上图所示,相比极简模式,完整正则模式增加了以下几个功能:
-
采集多行日志
- 极简模式仅通过换行符来切分日志,所以它无法采集多行日志(比如 Java 程序的异常堆栈)。
- 完整正则模式引入了行首正则,补足了采集多行日志的需求。
-
提取字段
- 极简模式不对日志内容进行任何解析,每条日志都作为一个整体被发送到服务端。
- 完整正则模式通过为日志设置用于匹配的正则表达式,利用括号语法来提取日志的局部内容作为字段值。
-
指定日志时间
- 极简模式只能使用采集时的系统时间作为每条日志所关联的时间。
- 完整正则模式可以通过指定提取得到的某个字段以及一个关联的时间格式,从字段值中解析得到时间戳,作为该条日志的时间。
接下来,我们将通过实际的操作去帮助您更好地理解如何使用完整正则模式的这三个功能。
准备工作
建议您可以先行到页面开通日志服务,创建必要的 project 和 logstore,这样您可以跟着本文的后续内容一起操作,加深您对完整正则模式的各个选项的理解。
我们为每个用户都提供了每月的免费额度,简单的试用不会给您带来花费,不必担心~
在您首次完成新的 project 和 logstore 的创建后,您将会进入到数据向导页面,如下图所示:

如果您不小心退出了这个页面(或者非首次创建),也可以通过如下的步骤进入:
- 登录日志服务控制台,点击您所创建的 project;
- 在进入的 logstore 列表,找到您所创建的 logstore,点击对应的数据接入向导图标,进入数据向导页面。
进入数据向导页面后,请滑动到页面的最下端,在自定义数据中选择文本文件,如下图所示:

在点击进入的页面中,选择完整正则模式,您会看到如下的界面:
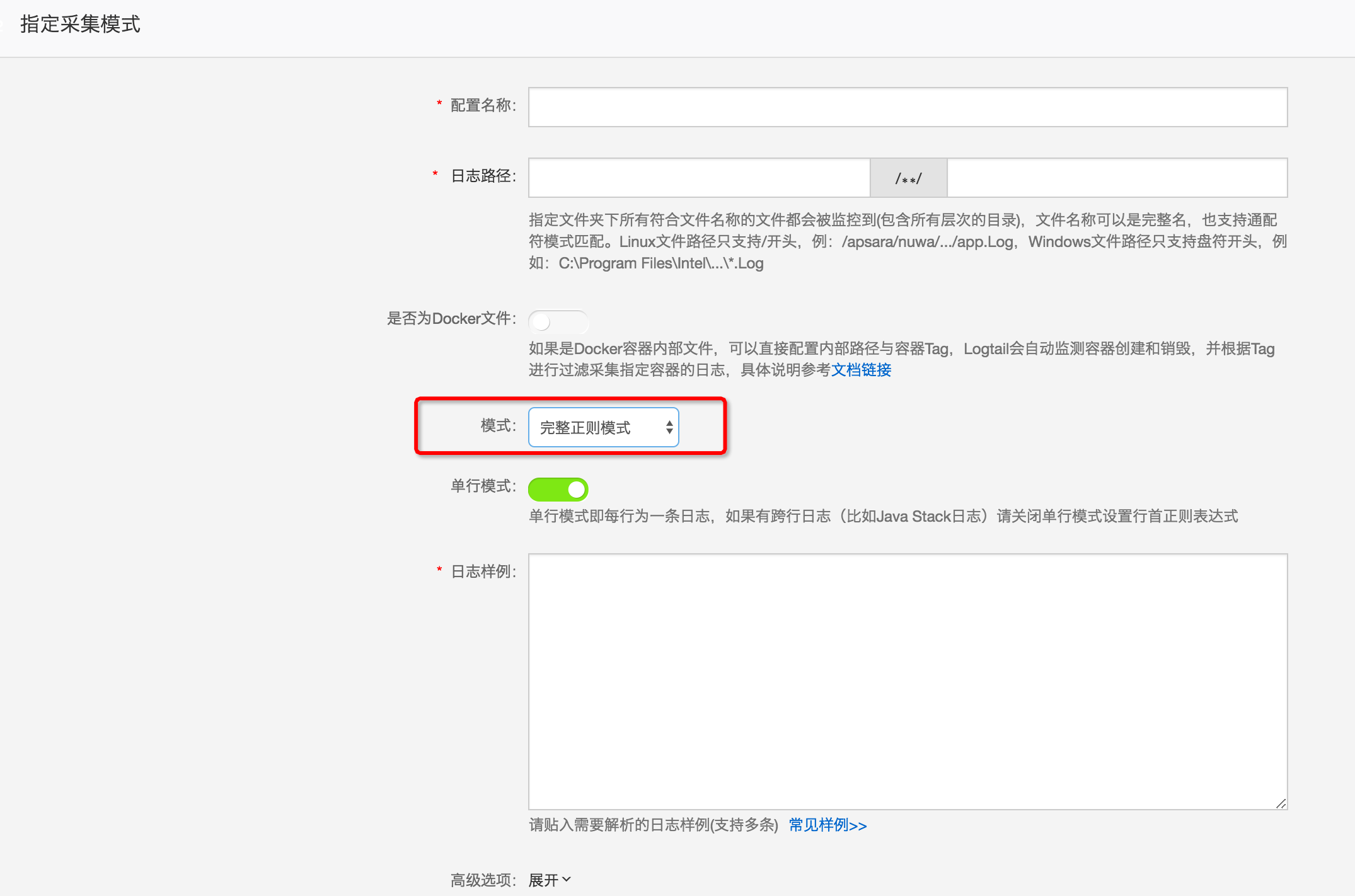
至此,我们的准备工作已经完成,接下来我们将依次为您介绍完整正则模式的三个功能。
单行/多行日志
一般来说,日志文件都是单行日志,比如 Nginx 日志、Apache 日志等,示例如下:
127.0.0.1 - - [10/Sep/2018:12:36:49 +0800] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
127.0.0.1 - - [10/Sep/2018:12:36:50 +0800] "GET /favicon.ico HTTP/1.1" 404 571 "http://127.0.0.1:8080/index.html" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"但同样也存在着多行日志的情况,比如使用日志库所打印的 Java 的异常堆栈日志等,示例如下:
[2018-10-01T10:30:01,000] [INFO] java.lang.Exception: exception happened
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:7)
at TestPrintStackTrace.main(TestPrintStackTrace.java:16)
[2018-10-01T10:30:31,000] [INFO] java.lang.Exception: another exception happened
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:7)
at TestPrintStackTrace.main(TestPrintStackTrace.java:16)完整正则模式同时支持对以上两种日志的解析,接下来我们来看看如何进行配置。
单行配置
当切换到完整正则模式时,默认使用的是单行配置,您只需要将您的实际日志粘贴到日志样例文本框中即可,如下图所示:

多行配置
对于多行日志的配置,首先您要关闭单行模式,然后设置行首正则表达式。Logtail 引入行首正则表达式来区分两条多行日志之间该如何被切分,所以正确地设置行首正则表达式是切分您的多行日志的关键。
以先前提及的 Java 异常堆栈日志为例,每条日志的开头都会有时间和日志等级,而日志的后续内容中一般没有类似的内容,因此,我们可以根据这一点来设置我们的行首正则表达式(同样地,您需要在日志样例中粘贴您的实际日志,最好两条以上)。
自动生成行首正则表达式
为了简化您的操作,我们为您提供了自动生成正则表达式的功能,您可以在粘贴日志后,点击自动生成,如下图所示:

上图示例中有几点值得我们注意:
- 我们关闭了单行模式的选项,这样界面上才会出现行首正则表达式的输入框。
-
自动生成的行首正则表达式
(\[\d+-\d+-\w+:\d+:\d+,\d+]\s\[\w+]\s.*)正确包含了时间和日志等级两部分:-
\[\d+-\d+-\w+:\d+:\d+,\d+]表示时间部分。 -
[\w+]\s表示日志等级部分以及其之后的空白符。 - 两者中间的
\s表示它们之间的空白符。 - 末尾的
.*是固定内容,一定要填写。
-
- 注意: 自动生成的行首正则并不一定完全可用,建议您进行一定的调整和优化。
手动调整行首正则表达式
自动生成行首正则表达式的功能很方便,但有时候它所生成的内容并不一定能够满足您的需求,您可以点击手动输入正则表达式,在自动生成的基础上,进行修改。当您进入手动输入正则表达式的状态时,页面上将出现一个验证按钮,通过它您可以验证当前输入的行首正则表达式能够从日志样例中匹配出多少行日志,方便您就地进行调试。
如下图所示,我们对自动生成的行首正则的第二部分(日志等级)进行了错误修改(去掉了 + 号),然后再点击验证就会发现日志的匹配数目变为了 0。

提取字段
在设置了单行或者多行及其行首正则表达式后,我们能够将原始文件中的内容切分为一条条的日志。如果每条日志都符合某个模式且能够使用相同的正则表达式来进行匹配时,我们就可以将每条日志中的局部内容提取出来,将日志转换为由键值对组成。
上述的这个过程我们称之为提取字段,在默认情况下,完整正则模式也只会将每条日志作为一个整体发送到服务端。为了开启此功能,您需要在页面上打开提取字段选项,如下图所示:

同样地,为了方便您的使用,您也可以使用自动生成的方式来为各个字段生成对应的正则表达式。在您打开了提取字段的选项后,日志样例文本框将变成一个可选择的区域,您可以在上面选中要提取的内容,随后点击弹出的正则按钮为选中的部分生成正则表达式。动图示例如下:
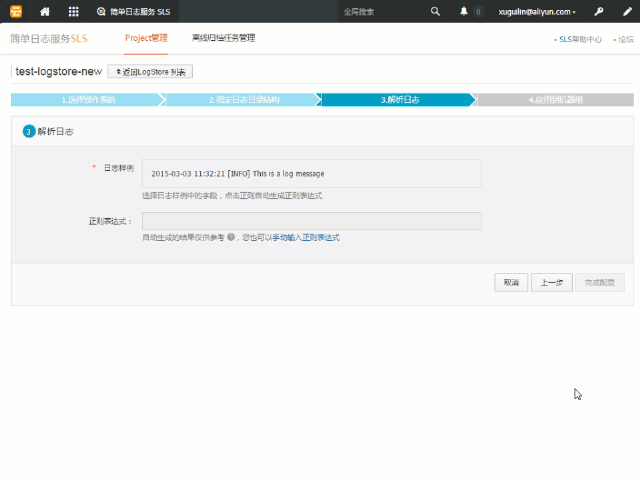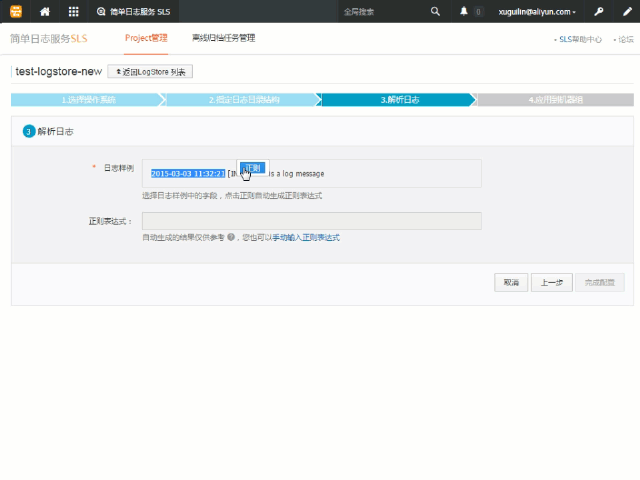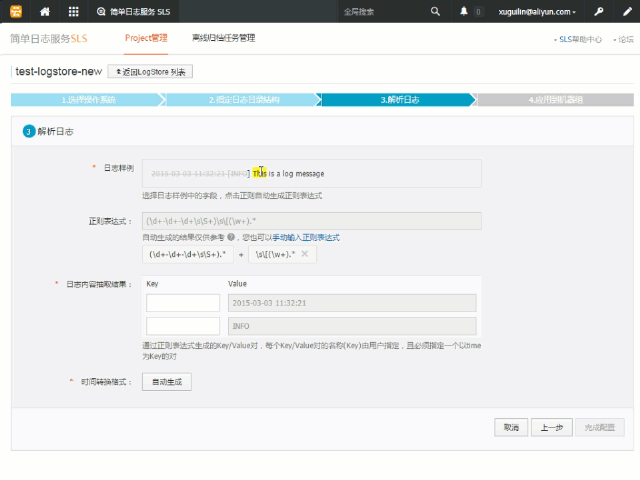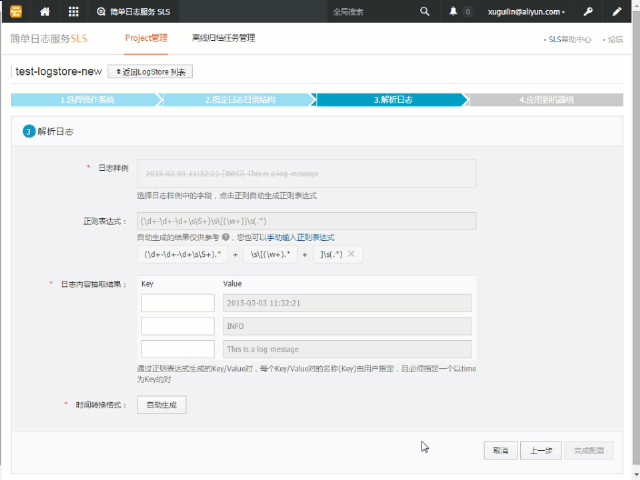
接下来我们使用自动生成来为先前的单行和多行示例提取字段。
单行配置

如上图所示:
- 我们从日志样例文本框中提取了 6 个字段,分别将它们的 key 命名为 ip、time、query、status_code、length、user_agent,这样该日志在采集到日志服务时,就会是一个具有 6 个字段(除特殊字段外)的日志。
- 在正则表达式的输入框下,我们能看到 6 个使用 + 号连接的区域,它们分别包含了提取这 6 个字段所使用的正则表达式,其中使用
()包裹的部分就是匹配对应字段的值时所使用的子模式。回想一下,我们之前也提到了提取字段是利用了正则表达式的括号语法实现的。
多行配置

如上图所示,整个生成的过程基本类似,但需要注意一下最后一个字段(message)。在生成时,因为我们希望最后一个字段包含剩余的所有内容,我们跨越了多行去选择日志内容。该字段对应的正则(仅括号内)为 ([^:]+:\s\w+\s\w+\s[^:]+:\S+\s[^:]+:\S+\s\S+)。事实上,这个正则是错误的(下文中我们会对此进行验证):
- 它无法完整地包含日志的剩余部分,最后一个 at 后的内容都没有被包含,这个从截图中可以看到。
- 另外,该正则表达式中有三个冒号(:),因此,如果某个异常日志只有两个冒号时,就无法匹配了。
这也体现了自动生成正则表达式的局限性,对此,您可以通过手动输入正则表达式来进行一些修改,比如将最后一项直接修改为 ([\S\s]+) 这样一个正则表达式即可将剩余的内容都包括到该字段中(包括换行)。
指定日志时间(可选项)
在日志服务中,每条日志都必须包括该日志发生的时间戳信息。默认情况下,Logtail 会使用该日志的采集时间作为它的日志时间(即启用使用系统时间选项),但经过字段提取后,如果您的字段中有表示日志时间信息的字段,您可以将该字段的名字指定为 time,然后为其配置时间格式,进而 Logtail 会将该字段的值解析为时间戳,然后关联给对应的日志。
Logtail 的时间格式解析使用的是 UNIX strptime,具体可参考文档配置时间格式。
此功能于单行/多行日志没有区别,这里我们就统一介绍下操作过程:
- 将带有日志时间信息的字段名字指定为 time,这个我们在先前的配置中都已操作。
- 关闭使用系统时间选项,在出现的时间转换格式文本框中填写时间格式。
类似地,我们也提供了自动生成的功能来简化您的使用,当然,您还是可以通过手动输入来进行自定义的修改。我们示例中的单行和多行日志所生成的时间格式分别如下:
- 单行日志

- 多行日志

至此,我们已经对完整正则模式的三个功能(单行/多行日志采集、提取字段、指定日志时间)进行了依此的介绍,并给出了在控制台操作它们的示例。
最佳实践
1. 如何调试正则表达式?
如果您希望对您所在日志服务控制台所设置的正则表达式进行调试,您可以直接在界面上使用验证按钮所提供的功能来进行检查:
- 对于行首正则表达式,检查一下当前设置能否正确匹配出您期望的日志数量。
- 对于提取字段,检查一下各个字段中的值是否是您所希望的。
进一步地,如果您希望进行更多的验证乃至调试正则表达式,您可以利用诸如 Regex101、RegexTester 之类的在线工具,将控制台为您自动生成的正则表达式拷贝粘贴到这些工具上,然后填充您的实际日志来进行检查、调试。
在之前的提取字段的示例中,我们有提到过自动生成功能为多行日志的 message 字段生成了不合适的正则。在此,我们以 Regex101 为例,对该正则进行一下检查:
- 首先,我们拷贝自动生成的完整正则至 Regex101:
\[([^]]+)]\s\[(\w+)]\s([^:]+:\s\w+\s\w+\s[^:]+:\S+\s[^:]+:\S+\s\S+).*。在界面的右侧,您还可以看到该正则的含义。
- 然后,我们向其中贴入我们在日志样例中的日志。

匹配,但是 at 之后的内容并没有被包含到 message 字段中(注意颜色,橘色和蓝色),这也就是我们之前所说的这个正则表达式是错误的原因之一。
- 接着我们来验证一下另一个错误:如果日志中只有两个冒号的情况。

匹配失败。
- 最后,我们看看按照之前所说的,将最后一个正则表达式替换为 [Ss]+ 再看看。
at 后面的内容:
只有两个冒号的日志:
类似地,您也可以按照如上的方法来对您的正则表达式进行调试、修改,最终应用于控制台。
2. 日志里包含多种格式怎么办?
完整正则模式要求日志必须采用统一的格式,但有些时候日志中可能会包含多种格式的日志,如何来处理这种情况呢?
[2018-10-01T10:30:31,000] [WARNING] java.lang.Exception: another exception happened
at TestPrintStackTrace.f(TestPrintStackTrace.java:3)
at TestPrintStackTrace.g(TestPrintStackTrace.java:7)
at TestPrintStackTrace.main(TestPrintStackTrace.java:16)
[2018-10-01T10:30:32,000] [INFO] info something
[2018-10-01T10:30:33,000] [DEBUG] key:value key2:value2以上面的 Java 日志为例,作为一个程序日志,它一般既包含正常信息,也会包含一些错误信息(比如异常栈等):
- WARNING 类型的多行日志
- INFO 类型的简单文本日志
- DEBUG 类型的键值日志
对此,有两种方案可以考虑:
- Schema-On-Write:为同样的一份日志应用多个采集配置,每个采集配置具有不同的正则配置,从而能够正确地实现字段提取。注:Logtail 不支持对同一个文件同时应用多个采集配置,您需要为该文件所在的目录建立多个软链接,每个配置作用于不同的软链接目录来间接实现多个配置同时采集一个文件。
- Schema-On-Read:使用它们共同的正则表达式来采集。比如说采用多行日志采集,将时间和日志等级作为行首正则,剩余的部分都作为 message。如果希望进一步分析 message 的话,您可以为该字段建立索引,然后利用日志服务的查询分析功能,比如使用正则提取来从 message 字段提取需要的内容,基于该内容进行分析。此方案比较受限,仅推荐作用在同时分析的日志数量较小的场景下(比如千万级)。
3. 正则表达式的性能优化
如果您非常地关注采集的性能,那您可以多花一些功夫在提高正则表达式的性能上。这里有一些建议可供您参考:
- 使用更为精确地字符,不要盲目地使用
.*来匹配字段,这个表达式包含了很大的搜索空间,很容易就发生了误匹配或者导致匹配性能下降。比如您要提取的字段只由字母组成,那么使用[A-Za-z]即可。 - 使用正确的量词,而不是盲目地使用
+,*。比如您使用\d来匹配 IP 地址,那么相比\d+,\d{1,3}可能会具有更高的性价比。 - 调试。类似于排查错误,您同样可以在 Regex101 上对您的正则表达式所花费的时间进行调试,一旦发现大量的回溯,及时地优化它。
4. 时间格式配置技巧
日志服务的时间戳只支持到秒,所以时间格式只需配置到秒,无需配置毫秒、微秒等信息。
只需time字段中前面能解析出时间的部分即可,后面无需配置
常见日志格式配置示例如下:
自定义1 2017-12-11 15:05:07
%Y-%m-%d %H:%M:%S
自定义2 [2017-12-11 15:05:07.012]
[%Y-%m-%d %H:%M:%S
RFC822 02 Jan 06 15:04 MST
%d %b %y %H:%M
RFC822Z 02 Jan 06 15:04 -0700
%d %b %y %H:%M
RFC850 Monday, 02-Jan-06 15:04:05 MST
%A, %d-%b-%y %H:%M:%S
RFC1123 Mon, 02 Jan 2006 15:04:05 MST
%A, %d-%b-%y %H:%M:%S
RFC3339 2006-01-02T15:04:05Z07:00
%Y-%m-%dT%H:%M:%S
RFC3339Nano 2006-01-02T15:04:05.999999999Z07:00
%Y-%m-%dT%H:%M:%S更多阅读
- Logtail从入门到精通(四):正则表达式Java日志采集实战
- Python 日志收集
- 在线正则表达式分析
- 加入分析交流群

评论暂时关闭