StackOverflowError:正则表达式栈溢出错误,
StackOverflowError:正则表达式栈溢出错误,
Some people, when confronted with a problem, think "I know, I'll use regular expressions." Now they have two problems.
“ 如果你有一个问题,用正则表达式解决,那么你现在就有两个问题了。”
问题
最近碰巧遇到了一个使用正则表达式错误!!
我们系统是基于Java语言开发的,其中使用的是JDK8自带的java.util.regex.Pattern类实现正则表达式匹配的。
系统中有一个正则表达式如下。
\{(.|\n)*?\}
其目的是用来区分Json风格字符串与其它字符串的。
但在实际使用中,当传入一个较长的Json字符串时,却发生了如下的错误。
Exception in thread "main" java.lang.StackOverflowError
at java.util.regex.Pattern$LazyLoop.match(Pattern.java:4845)
at java.util.regex.Pattern$GroupTail.match(Pattern.java:4719)
at java.util.regex.Pattern$BranchConn.match(Pattern.java:4570)
at java.util.regex.Pattern$CharProperty.match(Pattern.java:3779)
at java.util.regex.Pattern$Branch.match(Pattern.java:4606)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$LazyLoop.match(Pattern.java:4849)
at java.util.regex.Pattern$GroupTail.match(Pattern.java:4719)
at java.util.regex.Pattern$BranchConn.match(Pattern.java:4570)
at java.util.regex.Pattern$CharProperty.match(Pattern.java:3779)
at java.util.regex.Pattern$Branch.match(Pattern.java:4606)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$LazyLoop.match(Pattern.java:4849)
at java.util.regex.Pattern$GroupTail.match(Pattern.java:4719)
at java.util.regex.Pattern$BranchConn.match(Pattern.java:4570)
at java.util.regex.Pattern$CharProperty.match(Pattern.java:3779)
at java.util.regex.Pattern$Branch.match(Pattern.java:4606)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
...
...(非常多行)
分析
通过观察,我们知道这是一个虚拟机 栈溢出 错误。
Java语言中每个线程(Thread)的栈大小是有限制的,每一次函数调用都会生成一个栈帧(Frame),占用一定的栈空间,当栈空间被消耗完虚拟机就会报出StackOverflowError。
再仔细地观察,发现栈信息中显示调用层次非常多,而且类名与代码行重复出现,这意味着栈帧是由递归调用产生的。
到这里,问题发生的原因己经基本可以确定了。
在Java中正则表达式的产生了递归调用,而传入的长Json字符串导致函数调用层次太多,超过虚拟机预设的栈空间,因此,出现了StackOverflowError。
追根溯源
然而,以上的解释纯粹是现象+经验的推断,显然不能满足我的好奇心。
所以,我略略又研究了一下Java正则表达式部分功能的实现。
Java语言在做正则表达式匹配时,首先要进行编译。
使用java.util.regex.Pattern类的compile方法,编译的过程相当于把正则表达式
\{(.|\n)*?\}
转换类似下图的数据结构。
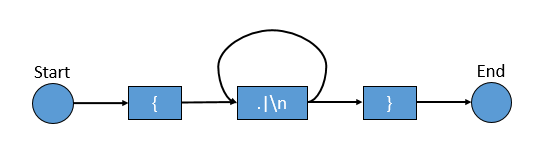
实际编译后的对象结构更复杂些,如下图。
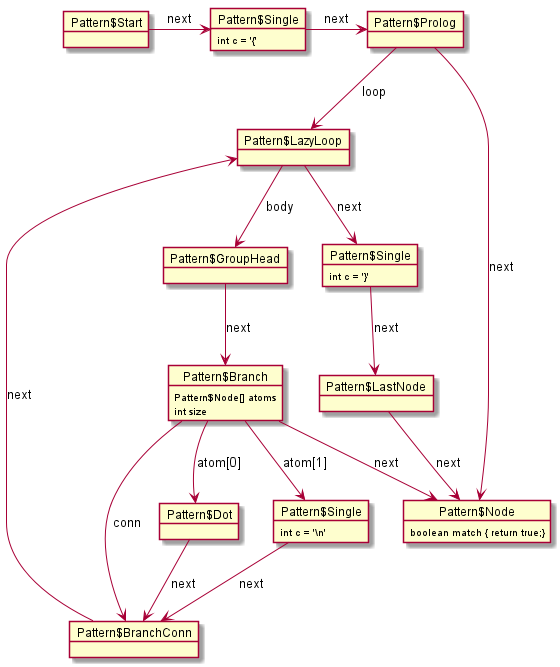
上图每个节点的类型都继承自Pattern$Node类,实现了match方法(即使没有重写方法,也有默认实现)。
当进行字付串匹配时,java.util.regex.Matcher的matches方法会调用第一个节点的match方法,继而形成递归调用链。
正如上面编译后的表达式,有一个以LazyLoop为启始的循环引用,当字符串的每个字符进行匹配时,都产生如下的栈结构。
at java.util.regex.Pattern$GroupTail.match(Pattern.java:4719)
at java.util.regex.Pattern$BranchConn.match(Pattern.java:4570)
at java.util.regex.Pattern$CharProperty.match(Pattern.java:3779)
at java.util.regex.Pattern$Branch.match(Pattern.java:4606)
at java.util.regex.Pattern$GroupHead.match(Pattern.java:4660)
at java.util.regex.Pattern$LazyLoop.match(Pattern.java:4849)
由于传入的字符串很长,因此递归调用的层次太多,很快便耗尽线程的栈空间(可以用-Xss配置),接着虚拟机就报出了StackOverflowError错误。
改进
知道了问题,我们着手进行改进。
修改正则表达式如下。
\{[\w\W]*\}
这样,编译后的表达式结构变成为。
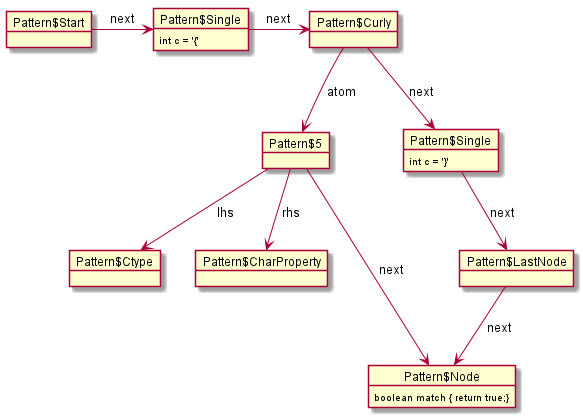
而在Pattern$Curly中的match方法使用的是while循环查找而非递归,因此,不会造成栈溢出。
总结
关于正则表达式及其优化,讲解的比较好的链接如下,这里不再赘述。
Java 正则表达式 StackOverflowError 问题及其优化
其中有一点与我这个场景是有关系的。
留意选择(Beware of alternation)
类似“(X|Y|Z)”的正则表达式有降低速度的坏名声,所以要多留心。首先,考虑选择的顺序,那么要将比较常用的选择项放在前面,因此它们可以较快被匹配。另外,尝试提取共用模式;例如将“(abcd|abef)”替换为“ab(cd|ef)”。后者匹配速度较快,因为NFA会尝试匹配ab,如果没有找到就不再尝试任何选择项。……
这一点其实不难理解,表达式编译后 (X|Y|Z) 其实是一个数组,从前到后依次进行匹配。
因此,在Java中写正则表达式最重要的还是:
减少分组与嵌套
如果你实际并不需要获取一个分组内的文本,那么就使用非捕获分组。例如使用“(?:X)”代替“(X)”。
评论暂时关闭