python正则表达式---基于re模块,python正则表达式re
python正则表达式---基于re模块,python正则表达式re
正则表达式是很通用的一套规则,而本文是基于python的re模型的实现,来讲解正则表达式的语法。常见的正则表达式如图:
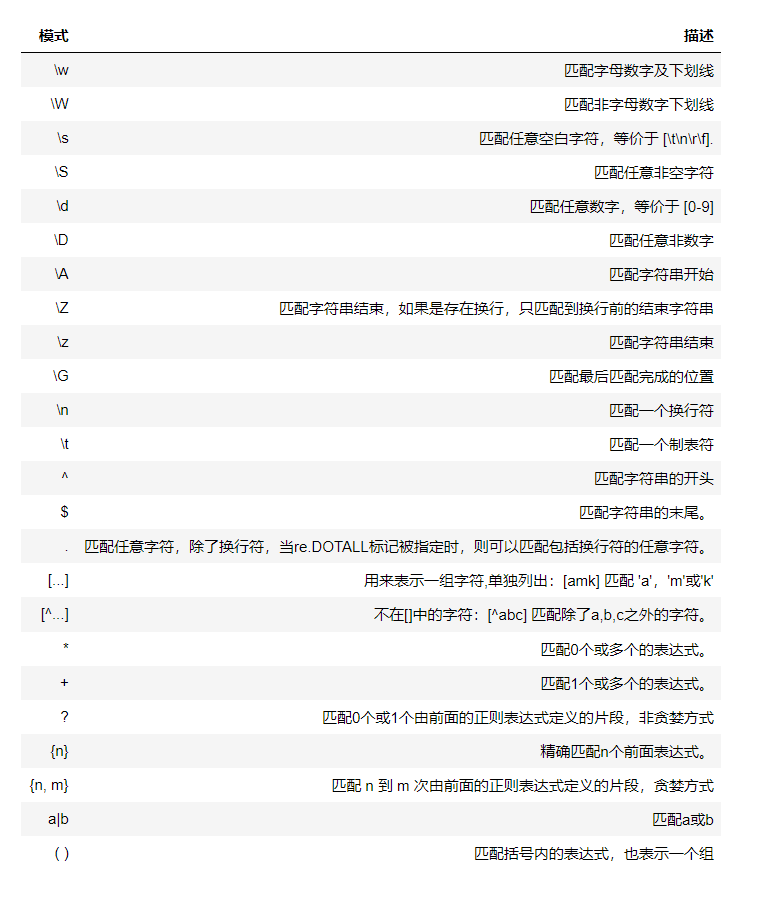
我们讲讲python中re模块常用的方法。
1、re.match()(其实,最好用re.search(),能完全替换re.match())
re.match()方法尝试从第一个起始位置匹配一个模型,如果不是起始位置匹配成功的化,返回none
1.1、常规匹配
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello\s\d\d\d\s\d{4}\s\w{10}.*Demo$', content)
print(result)
print(result.group()) #group()方法返回字符串
1.2、泛匹配
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('^Hello.*Demo$$', content)
print(result.group())
1.3、匹配目标
content = 'Hello 123 4567 World_This is a Regex Demo'
result = re.match('.*(\d{3}\s\d{4}).*', content) #小括号()表示要返回的目标
print(result.group(1))
1.4、贪婪匹配,匹配尽可能多的字符
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*(\d+).*$', content)
print(result.group(1))
1.5、非贪婪匹配,匹配尽可能少的字符,例如看到后面是匹配数字的规则了,就停止前面的匹配
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('^He.*?(\d+).*$', content)
print(result.group(1))
1.6、匹配模式
content = '''Hello 1234567 World_This
is a Regex Demo
'''
#如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重#新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整#体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
result = re.match('^He.*?(\d+).*?Demo$', content, re.S)
print(result.group(1))
'''
####1.7、转义
```python
#尽量使用泛匹配、使用括号得到匹配目标、尽量使用非贪婪模型、有换行符就是要re.S
content = 'price is $5.00'
result = re.match('price is \$5\.00', content)
print(result)
2、re.search()
re.search()扫描整个字符串并返回第一个成功的匹配,能用search不用match。
#尽量使用泛匹配、使用括号得到匹配目标、尽量使用非贪婪模型、有换行符就是要re.S
content = 'Hello 1234567 World_This is a Regex Demo'
result = re.match('Hello.*?(\d+).*', content)
print(result.group(1))
html = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君"><i class="fa fa-user"></i>但愿人长久</a>
</li>
</ul>
</div>'''
result = re.search('<li.*?singer="(.*?)">(.*?)</a>', html, re.S)
if result:
print(result.group(1), result.group(2))
3、re.findall()
re.findall()以列表的形式返回全部能匹配的子串
results = re.findall('<a.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>', html, re.S)
print(results)
4、re.sub()
re.sub()替换字符串中每一个匹配的子串后返回替换后的字符串
content = 'Hello 1234567 World_This is a Regex Demo'
content = re.sub('\d+', 'replacement', content)
print(content)
5、re.compile()
re.compile()将正则字符串编译成正则表达式对象,以便于复用该匹配模式
content = 'Hello 1234567 World_This is a Regex Demo'
pattern = re.compile('Hello.*Demo')
result = re.match(pattern, content)
print(result)
#下面示范一个取整个文本一段文字的例子
content = '''<div id="songs-list">
<h2 class="title">经典老歌</h2>
<p class="introduction">
经典老歌列表
</p>
<ul id="list" class="list-group">
<li data-view="2">一路上有你</li>
<li data-view="7">
<a href="/2.mp3" singer="任贤齐">沧海一声笑</a>
</li>
<li data-view="4" class="active">
<a href="/3.mp3" singer="齐秦">往事随风</a>
</li>
<li data-view="6"><a href="/4.mp3" singer="beyond">光辉岁月</a></li>
<li data-view="5"><a href="/5.mp3" singer="陈慧琳">记事本</a></li>
<li data-view="5">
<a href="/6.mp3" singer="邓丽君"><i class="fa fa-user"></i>但愿人长久</a>
</li>
</ul>
</div>'''
result = re.search('<ul.*?</ul>', content, re.S)
print(result.group())
6、实战演练
import requests
import re
content = requests.get('https://book.douban.com/').text
#为什么要先截出来一部分,因为如果整个用pattern匹配太慢了。。
content = re.search('<ul class="list-col list-col5 list-express slide-item">.*?</ul>', content, re.S).group()
pattern = re.compile('<li.*?cover.*?href="(.*?)".*?title="(.*?)".*?more-meta.*?author">(.*?)</span>.*?year">(.*?)</span>.*?</li>', re.S)
results = re.findall(pattern, content)
for result in results:
url, name, author, date = result
author = re.sub('\s', '', author)
date = re.sub('\s', '', date)
print(url, name, author, date)
结果如下:

评论暂时关闭