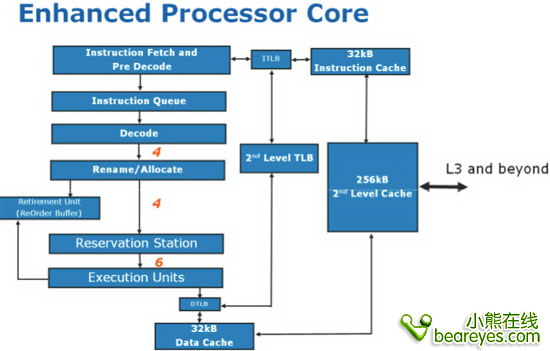
史上最强Intel Nehalem架构超详解析(1)(2)
全新架构:不是另一个Conroe
如果拿Pentium 4和Conroe来做比较那么他们之间的差别就像是黑夜与白天之间那么明显。P4所采用的NetBurst架构纯粹就是为了追求时钟速度的极限。而Conroe则刚好相反,只追求时钟周期执行效率。他们在架构设计思想方面,有本质的不同。Pentium 4需要做极大的软件方面优化,才能更进一步提高硬件的物理效能,此后Intel从中吸取了这个教训,不在期望通过编译器和代码优化来提高硬件的性能。他们在重新设计新一代处理器架构的时候,采用了模块化的设计思想。

Conroe是Intel第一颗包含了4路前端的处理器。这颗处理器可以进行解码、重命名,并且在同一个时钟周期可以执行4个内部微指令。不过事实上Conroe的实际处理效能可能达不到这个程度。
在Conroe中,Intel推出了宏指令的概念,它可以将2个x86指令“融合”在一起进行解码、执行和退出操作。这2个指令融合之后,就会被视为是一条指令。这项技术在某些情况下会极大的加速指令的处理效能。
Nehalem中近一步添加了更多的指令融合机制,同时也支持目前所有Core2中的宏指令技术。

另外在Nehalem中还加入了64bit指令的融合机制。在过去仅仅可以融合32bit的指令,现在64bit的指令融合也可以得以实现。在处理64bit代码的时候,我们可以看到明显的性能改善。
杀死分支:改善循环监测机制
在Core 2中特有一种叫做LSD流循环检测机制。它通过一个逻辑点检测处理器执行效能,查看在软件中各种循环语句的结构。它可以停止分支预测,可以停止那些潜在的不正确的预测分支,同时也能简单而有效的停止指令流中的指令。
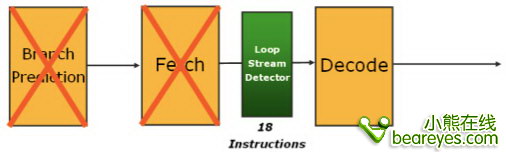
分支预测和指令取回的硬件都可以被停止。在LSD单元中可以停止Core2处理器正在运行的18条指令。并且简单的从指令流中踢出他们。此后他们会再次被送到解码单元,提前完成一次循环。或者就将这些指令废弃。
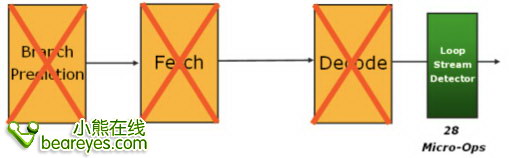
在Nehalem中LSD被迁移到解码单元中,并且被放置在解码单元中的微指令高速缓存中。在一个循环中,分支预测,指令取回和解码硬件都可以通过访问高速缓存来找到LSD,那么LSD能发挥作用的同时也能进一步降低功耗。并且LSD能在重订缓冲区中直接对指令流进行操作。在Nehalem处理器中,LSD能够缓冲28个微指令,在实际的工作中,会比Core 2处理更多的分支指令。
两级预测:Nehalem中的分支预测改进
上文已经谈到了许多Nehalem中的改善,在Nehalem中分支预测单元方面的改善显得比较温和,不过这对于Intel本已经十分强大的分支预测来说,这些改进可算是相当难得了。
现在的Nehalem已经有了第二级分支预测单元,虽然它的速度相对较慢一些,不过它能检索到更大的程序分支历史记录,无论他们是否已经被踢出。在L2高速缓存中的分支预测单元具备非常大的代码容积。Intel采用数据库应用软件做了一些实际的演示范例。得益于分支预测的精确性,应用程序的处理效能有显著的增加。
在Nehalem中,重命名堆栈返回缓冲器也是一项非常重大的改进。在上一代Penryn处理器中,处理管线中无法预测的部分会导致数据迁移结果在返回堆栈中的错误。由于要保持数据结构的完整性,处理器在处理内存数据的时候都将交由一个函数来完成工作。返回堆栈会通过重命名的方式来防止堆栈错误。因此这种调用和返回的操作都会一对一对的匹配进行。在Nehalem中你会看到如果发生分支预测的时候,数据总能被正确的输出。

对于应用程序来说,这是非常重要的改进。Nehalem的设计在服务器领域内修复了这些缺点。早在这次秋季IDF之前,关于Nehalem在服务器领域的性能表现就已经成为了业界的焦点。当Nehalem被应用在桌面台式机市场的时候,同时也激发了服务器领域的设计。
而这些改进已经成为了Nehalem整个架构设计的一部分。Nehalem的体系架构要追溯到Pentium-M处理器和Centrino平台。而这次在服务器领域的技术进步,也激发了台式机和移动领域芯片的革命。
如果说对Nehalem最大的期望是什么,那么小编我说就是不要重蹈Pentium 4的覆辙,不要为了再追求时钟频率而牺牲了性能,增大了处理器的发热量。
Nehalem和Atom的设计都是Intel有史以来重大的突破,将功耗/性能之比提高到了一个前所未有的地步。如果Nehalem和Atom的功耗增加了1%,那么相应的他们的性能要增加到2%。否则如果功耗的提升与性能的提升曲线保持平行,那么Intel还会走上速度至上的死路。
评论暂时关闭