史上最强Intel Nehalem架构超详解析(1)(4)
深入分析:高速缓存的层级架构
我们又谈到了Nehalem的高速缓存层次,这次我们来对它整个层级架构做一个详细的介绍。

Nehalem的高速缓存层级架构有点类似于AMD的Phenom,它具备3个级别的高速缓存层次。L1高速缓存具备64KB,其中32KB数据和32KB指令。每一个处理核心具备256KB的L2高速缓存,这些都是处理核心所独占的,处理核心之间的L2高速缓存不会共享。最后L3高速缓存的容量高达8MB,所有处理核心都可以共享L3内的数据。
Nehalem中的L1高速缓存的容量虽然与Penryn核心相同,但是它更慢一些,Penryn仅有3个周期,而Nehalem会有4个周期。Intel声称,降低L1的速度有利于更好地控制处理器的时钟速度,特别是在Nehalem这样极其复杂的芯片中。根据Intel所估计提高Nehalem的L1的潜伏期,会造成处理器整体效能下降2~3%。
同时L2高速缓存的性能也会有所阉割。在Penryn中两个核心之间可以共享6MB容量的L2高速缓存。Nehalem虽然为每个处理核心配备了独立的L2高速缓存,但是其容量骤降为256KB。
从Pentium 4开始起,Intel还没有为处理器制定出容量如此小的L2高速缓存。Intel指出,小容量L2的速度将会更快,数据从L2中装载和输出仅需10个潜伏期就可以达成。
由此L2充当了L3的高速缓冲区,不过也并不是所有的核心都可以自由的访问L3,它们也需要提前发出访问L3的请求。
所有的核心都可以共享L3高速缓存中的数据,并且Core i7处理器具备高达8MB的容量,这对于多核心处理器来说,是非常有必要的。通过共享L3中的数据,支持多线程的应用程序就可以支配所有处理核心协作完成所需的运算。可以说Nehalem的高速缓存层级架构沿用了Intel一贯的包容风格,在过去Intel设计缓存架构的时候一直使用着这种思想。Nehalem中的L3高速缓存包含L1和L2中的所有数据。这样的好处是如果处理器在L3中寻找所需的数据,并且没有找到的话,它就知道数据不在这里,同时也不在任何的L1和L2高速缓存中。这样它就会从更低级的内存中寻找数据。这样的机制不仅会加快处理的效能同时也能减少功耗。
高速缓存也包含了对于核心数据处理流量的侦测机制。随着处理器中处理核心的不断增加,将很难控制他们的处理任务量。介于Nehalem被设计为4核心的处理器,流量侦测机制也被加强了。
从T6到T8:改善缓存功耗管理
在今年秋季的IDF大会上,Intel介绍了在Nehalem中应用的一项新的功耗节能技术——8T8晶体管)SRAM单元设计。所有核心中的L1和L2高速缓存都采用了这项技术,而L3高速缓存并没有使用这项技术。当Intel在Nehalem上应用8T设计时,能减少它的操作电压,进而可以减少Nehalem的功耗。这样的设计与Intel在Atom的L1高速缓存上的设计比较类似。
为了降低Atom上L1的功耗,Intel使用小型信号数组来代替开关寄存器文件单元。这是L1的写入和读取端口。现在高速缓存具备更大尺寸的单元,每个单元有8个晶体管构成。因此也相应的增加了L1的芯片面积和针脚数量。从Intel官方发布的芯片内部结构图来看他具有更大的数据高速缓存,不过为了降低功耗,它从32KB阉割成了24KB。这是Atom缓存架构中最为独特的方面,当Intel第一次公布这条消息的时候,所有人都在惊诧,为什么Atom的L1中数据和指令缓存是非对等的。通过这样的设计,Atom可以进一步降低工作时候的驱动电压。
Atom的小信号数组采用的是6T单元的设计,因此它的操作电压可以降低到最小。换句话说,使用最微弱的电压就能保存L1中的数据。在L2中Intel使用了6T单元的小信号数组,并带有ECC奇偶校验。架构设计师的初衷就是要尽可能的不去使用较大的晶体管单元,从而进一步降低工作电压。
Intel指出,在Nehalem的核心缓存中,从以前的6T SRAM转换到了8T SRAM。这仅仅是Nehalem中的L1和L2高速缓存。这是因为在Nehalem中的每个处理核心,其L2的容量已经非常小了,仅有256KB。Intel声称,从6T到8T的转换过程中,付出了沉重的代价,激增的晶体管数量相当于Nehalem的8MB L3高速缓存的33%。

偷师无愧:整合内存控制器
在Nehalem中还整合了内存控制器。Intel第一次将内存控制器由主板芯片组中转移到了处理器的核心内。同时我们也应该注意到,这个独特的内存控制器是一个货真价实的3通道DDR3内存控制器。这也就意味着你要在主板上同时插上3条DDR3内存,才能实现3通道的带宽。我想这一定把内存厂商给乐坏了。今后内存厂商肯定会为Nehalem平台,推出3通道内存套装产品。桌面级的Nehalem处理器会有2个内存控制器,而更高级的服务器级别会有3个内存控制器。
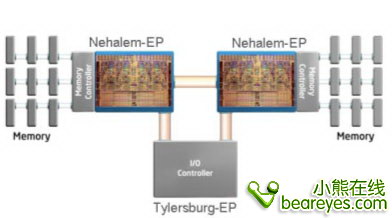
3通道DDR3内存技术的出现,使得Nehalem拥有了足够大的内存带宽。这绝对有助于喂饱饥渴的处理核心。不过内存带宽的增加带来的副作用就是使得Nehalem的预取单元的工作更加忙碌。
下面我们来谈谈服务器级别的Nehalem处理器的详情。事实上由于Core 2处理性能的突飞猛进,使得在许多企业级别的应用中数据的预取机制几乎没有发挥出来。很多企业及的应用软件都会对系统的带宽造成很高的资源占用率。通过预取机制,我们可以更好的平衡带宽负载。
在Nehalem中的预取机制的权限非常大,在系统内没有足够的可用带宽时,它可以劫杀一部分资源占用率较高的进程。
传说中的:QPI总线
当Intel提出了将内存控制器集成在处理器核心内部的时候,它还需要一个与处理核心之间通信的高速链接。因此Quick Path Interconnect (QPI)总线也就由此诞生了。从字面上看去,它比Hyper Transport更有助于提升系统的效能。
QPI每一个链接都是全双工的,每一个链接支持6.4GT/s的带宽。每一个2-byte宽度的链接每个方向可以得到12.8GB的带宽,由此一个单一的QPI链接足以提供25.6GB/s的带宽。
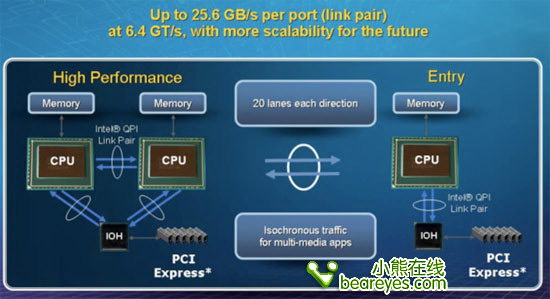
而更高端的Nehalem处理器将会有2个QPI链接,而一般主流阶层的Nehalem处理器将只有1个QPI链接。
可以说QPI总线,与AMD的HT总线相类似。现在开发人员最担心的就是NUMA非一致性平台。在由Nehalem组成的多处理器系统中,每一个处理器都将有自己的本地内存,并且应用程序需要保证处理器能找到与之相对应的内存。
在这个领域中,AMD早期的IMC和HT都对Intel今天的处理器设计有很大的参考价值。在服务器领域针对应用软件,AMD完整了大部分的架构设计工作,这对于Nehalem来说也有着非常多的借鉴价值。
继续扩充:新的SSE指令集
与Penryn相比,Intel扩展了SSE4指令集,在Nehalem设计的初期版本为SSE 4.1,现在Intel又加入了几条更新的指令,目前Intel将它叫做SSE 4.2。
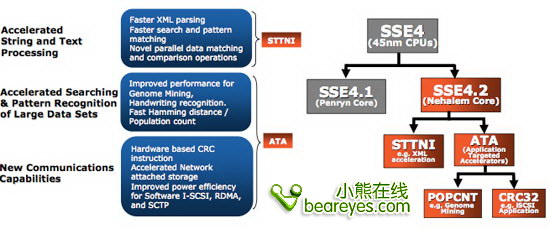
未来Intel的扩展指令集架构中还将加入更为先进的高级矢量扩展指令AVX),由此处理器就可以支持256bit位宽矢量处理。AVX指令可以作为一种中间媒介让SSE指令和未来的Larrabee图形核心进行指令通信。小编我猜想,未来Intel可能有意将Nehalem与Larrabee的指令集合并。

评论暂时关闭