史上最强Intel Nehalem架构超详解析(1)(3)
数量加大:执行引擎的改善
Nehalem中的执行引擎与Penryn相比并没有较大的变化,处理管线的前端已经足够宽广,可以吞下足够多的数据。因此下面我们就来谈谈处理管线架构后端的执行部分。
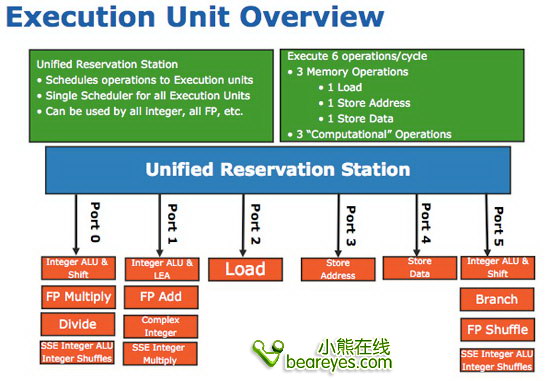
在芯片内部,Intel显然没有增加数据结构的尺寸,但是对于处理单元的个数有所增加。在Conroe/Merom/Penryn中仅有96个uop,而在Nehalem中增加到128个。
而预留执行单元也从以前的32个uop增加到36个。并且它的装载和存储缓冲区也分别从以前的32/20增加到现在的48/32个登录入口。
虽然Nehalem相对于Conroe/Penryn来说在这方面不会有较大的改进,但是各项参数的配置设计都要算是最为匹配的。小
更加完善:TLB单元和独立高速缓存链接
在计算机的发展史上,可以说应用软件促进了硬件的发展。而在微处理器发展史上,服务器应用软件推动了处理器中TLB单元尺寸和性能的发展。在Nehalem中不仅仅增加TLB单元的尺寸,同时也增加了第二级统一的TLB单元,他们可以处理代码和数据。
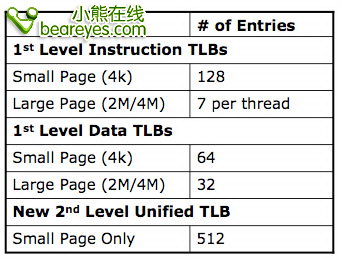
另一个潜在的重大修正是Nehalem具备更快的独立高速缓存链接。在应用程序中,可能有许多大型尺寸的SSE内存操作,他们的长度能达到16-bytes (128-bits)。对于这些数据的装载/存储操作都会有2个步骤,第一步操作是划分出16-byte的界限,第二步操作将数据拆解。
当编译器在执行拆解操作的时候,如果内存的存取没有16-byte个字长,那么它将不能被正常操作。在所有的Core 2处理器中,拆解操作都将会花费很多时钟周期,拖累整个处理流水线的运作。
问题是许多编译器不能保证数据在拆解的时候长度恰好符合要求,并且默认的操作通常都会出现这些问题。
在Nehalem中,Intel大幅减少了拆解操作的出现几率,同时如果在使用拆解操作的时候,不会对处理流水线的性能产生重大的影响。编译器现在可以自由的使用拆解操作了。
早先的Core 2架构中在拆解操作方面可是吃尽了苦头。程序员需要额外编写代码来指定拆解目标解决执行效能的问题。在Nehalem中有一个区域可以实现重新再优化/再编译功能,这样会在拆解操作的时候加快速度。
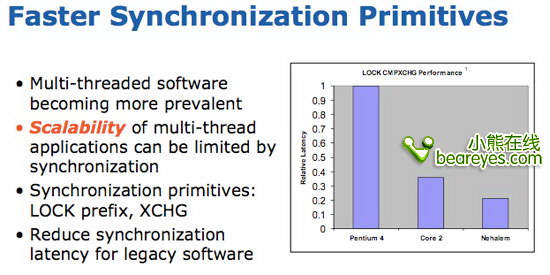
在Nehalem中,也重点改进了线程并行处理的性能表现,我们会在下一页详细说明这个技术点。
又见又见:Hyper Threading超线程
小编我曾经问过Intel的一位高级工程师,在微处理器行业中什么是最让你感到兴奋的技术?他就回答出一个字:线程!不过在Pentium 4处理器上,我们并没有体验到Hyper Threading超线程的强大,总被DIY发烧友抨击为骗人的玩意。
Hyper Threading是Intel在市场营销时所使用的名称,从技术层面上讲它应该叫做SMT同时多线程技术。在同一个时刻处理器可以同时取回2条指令。而操作系统就会将基于HT技术的处理器识别为多个处理器,一般单核心的处理器会被识别为2个处理器,因为处理器可以同时发送2条线程指令。
我们回到Nehalem处理器,看看它的Hyper Threading有哪些新花招。总的来说,它将比Pentium 4具备更高的执行效能,具体有以下几个原因:
1、Nehalem拥有更大的内存带宽和更大的高速缓存,这要比传统的Pentium 4强上许多。因此,它将会为处理核心提供更充足的数据,具备更好的分支预测性能。
2、Nehalem比Pentium 4具备更为优秀的体系架构,每个核心都具备使用多线程的能力。
正如史上第一颗Pentium 4不具备超线程技术一样,Nehalem架构的处理器,也没有特指继承了以前的超线程技术。Intel这样做的主要原因是要让Nehalem的核心架构看起来更加简单,而且现在很多简单的应用程序也都开始支持一般的超线程技术。
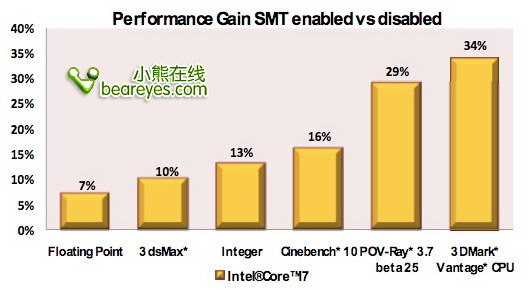
你可以从下面的图表中看到开启和关闭超线程特性时,Nehalem处理器的性能表现。
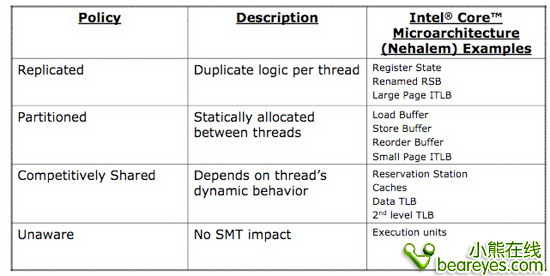
Nehalem中的超线程设计,与Atom相类似。植入超线程功能仅仅占用了很小一部分芯片面积。要实现超线程技术,仅仅需要加入一些寄存器,重命名返回缓冲器,更长的TLB指令载入页。只要简单的加入这些组件,就可以实现该功能了。当开启超线程时,其余的数据结构会被拆分,从新分配。或者会被资源管理器动态的决定他们要被分配到哪个处理器核心去。
开启超线程特性后,Nehalem处理器的性能会大幅加强。在许多应用程序中,性能的提升都非常明显。它的性能提升幅度要远远高于Pentium 4处理器。
现在各位读者也许能够猜到,为什么Intel会大幅增加Nehalem处理器的各种缓冲区的容量了吧。为的就是让缓冲区能够存储更多的指令,这些指令将会被拆分为2个线程,同时执行。同时,处理流水线的前端,也被设计的非常宽广,他们可以一次吞入更多的指令,为更多的指令进行解码,这样就能喂饱后面的超线程与多核心单元。在处理流水线中,可以传输更多的内部微指令,执行更多的微指令操作,同时也可以给分支预测更多的历史记录,让乱序执行的效率大幅增加。
评论暂时关闭