Hadoop单节点故障改进方案对比
Hadoop单节点故障改进方案对比
HDFS 单点改造方案对比
1背景
目前,HDFS集群的架构包括了单个Name Node和若干个DataNode。Name Node负责两方面的事情:一方面是存储和管理整个命名空间,包括创建、修改、删除和列举文件目录等文件系统级别的操作;另一方面是管理Data Node和文件块。Data Node主要负责文件块的持久化存储和远程访问。
1.1命名空间管理
HDFS的命名空间包含目录、文件和块。命名空间管理:是指命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作
1.2 块管理
A) 处理Data Node向NameNode注册的请求,处理datanode的成员关系,处理来自DataNode周期性的心跳。
B) 处理来自块的报告信息,维护块的位置信息。
C) 处理与块相关的操作:块的创建、删除、修改及获取块信息。
D) 管理副本放置(replica placement)和块的复制及多余块的删除。
目前HDFS为单NameNode模式,Namenode运行时将元数据及其块映射关系加载到内存中,随着集群数据量的增大,Namenode的内存空间也会遇到瓶颈。据实际生产经验统计如下:
|
文件数 |
数据块数 |
内存空间占用 |
|
3千万 |
3千万 |
约12GB 块管理 ≈ 7.8G,包括全部块副本信息 目录树 ≈ 4.3G,目录层次结构,包含文件块列表信息 |
|
10亿 |
10亿 |
约380GB 块管理 ≈ 240GB 目录树 ≈ 140GB |
注:淘宝与百度等均以支撑10亿的文件数为设计目标,京东文件系统的业务对象主要为图片,电子书等,10亿文件量可能只是时间问题。
2方案对比
2.1 Federation HDFS
HDFS Federation使用了多个独立的Namenode/namespace来使得HDFS的命名服务能够水平扩展。在HDFS Federation中的Namenode之间是联盟关系,他们之间相互独立且不需要相互协调。HDFS Federation中的Namenode提供了提供了命名空间和块管理功能。Federation中引入了block pool的概念,负责对该命名空间的数据块进行管理。命名空间和它所拥有的BlockPool统称为一个Namespace Volume。datanode被所有的Namenode用作公共存储块的地方。每一个datanode都会向所在集群中所有的Namenode注册,并且会周期性的发送心跳和块信息报告,同时处理来自Namenode的指令。
优点:namenode增加了集群存储数据容量与访问的并发处理,namenode中分为了2个部分:命名空间管理及其数据块管理;单个namenode down掉重启需要的时间比集中到一个namenode需要的时间变短;降低集群整体不可用的风险。
缺点:集群失去了统一的命名空间管理,单个namenode down掉对应该namenode的数据不可访问;多命名空间独立而不支持统一命名空间;
2.2 HDFS2

百度从2007年开始使用hadoop,我们相信从那时候开始,HDFS逐渐开始被改造。从百度HDFS2的架构图可以看出大致分为2层,上面一层为命名空间管理,类似Federation的多命名空间设计思路,提供了几种命名空间管理方式:层级命名空间管理;S3扁平化命名空间管理;用户定制化命名空间。3者是平级的。文件管理与块管理不再包括在namenode。在对象管理层,整合了文件管理与块管理功能,同时也负责了数据块存储。
优点:
1、大部分耗时操作都属于文件对象管理层,不用经过Namespace
2、最耗CPU资源的若干操作中,仍需经过Namespace的只占13.7%
3、命名空间管理不再维护块信息,大部分操作都不需要加全局锁,可以更充分利用CPU资源;
4、文件对象管理服务直接就是水平可扩展的;
5、文件对象管理做为单独服务存在,可挂载不同类型命名空间,如S3;
6、改造后,10亿文件量,文件 ≈66GB,目录 ≈ 1GB,单节点命名空间就可以管理;
缺点:
HDFS2现阶段版本没有实现高可用性;
HDFS2借鉴了Lustre,Ceph,S3等的设计思想,调研结果如下:
|
|
Lustre |
Ceph |
GFS2 |
|
分布式元数据组织策略 |
随机,轮询等;各节点平坦存放INODE信息 |
动态子树分割,元数据服务维护INODE到根目录的路径;子树修改可以同步到每一个节点上的子树副本; |
|
|
独立块,对象管理层 |
是 |
是,独立的对象管理层RADOS,通过P2PW维护内部的数据一致性和副本安全 |
推测是 |
|
元数据存储策略 |
共享对象存储 |
共享对象存储 |
共享存储bigtable |
|
元数据定位 |
路径查询和权限控制需要根据目录层级遍历多个元数据服务。解决性能问题采用了客户端缓存和分布式锁机制 |
无需跨多台 |
|
|
特色 |
|
RADOS,CRUSH |
支持小文件存储;支持低延迟的交互式请求 |
由于这些资料都不是官方发布,我们通过公布的一些架构图大致可以推断一些设计:
1、 在命名空间部分,用到了静态子树,动态子树分割,及其hash算法,猜测其树状命名空间是跨越节点的;
2、 对象层有文件管理及其块管理,猜测可能先通过树状命名空间获得文件的inode,及其位置,然后客户端直接到相应节点读取文件元数据,通过文件对象找到其块映射,及其块与datenode的映射关系,然后客户端再直接与datenode通信,进行相关块的读写操作,在树状命名空间,后面的对象层均可以实现冗余及其修复机制。
3、 像亚马逊的S3,文件系统最大的问题就是扩展性,完全取决于他的树状结构,扩展起来相当困难。亚马逊解决存储服务的时候,抛弃了树状,采取了很平坦的结构,对象存储的概念。S3对象存储概念,使得亚马逊支撑对象数可以支撑上千亿,是现在最大的存储集群。实现了S3的平坦两层命名空间,可用于存储百度的图片,MP3,PPT。当然如网盘类的应用可采用树状结构的命名空间。
2.3 ADFS(TBFS)
ADFS的现有架构从上到下分为三层,如图表 1所示: 最上层(StateManager, Zookeeper和MetaChecker)负责元数据持久化和校验,无状态的中间层(Stateless Namenode)负责事务逻辑和最底层(Datanode)负责文件块的物理存储和访问。将命名空间(Namespace)、块对应关系(BlocksMap)和Datanode信息存储到innode数据库中,避免了重启时需要通过Datanode的blockReport来构建BlocksMap和Datanode信息,提供了快速重启的必要条件。通过缓存,SSD和RAID卡来提高IO性能等来提高性能。通过MetaChecker 异步地检查元数据的正确性。Zookeeper在ADFS的架构中也承担比较重要的角色,它不仅负责记录租约,正在写入的文件,以及多块、少块和坏块等结构,而且还负责State Manager的主备选举。以后会将Zookeeper负责的namenode部分的功能放到数据库中,Zookeeper仅负责主备选举。通过配置文件,和Zookeeper替换namenode。
优点:单个namenode down掉可以快速切换,提供正常服务;元数据等持久化,namenode重启等不需要很长的时间;
缺点:元数据持久化,数据库应该有瓶颈;同时服务的仅一个namenode,因此仍然存在性能瓶颈
2.4 XFS
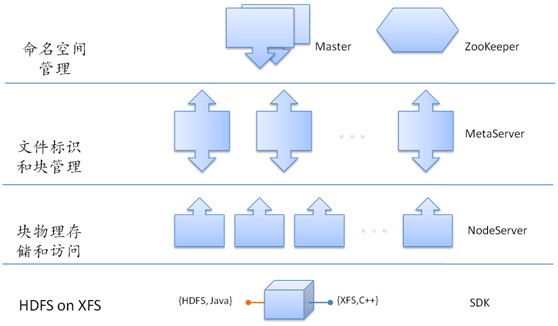
命名空间由Master进行管理,XFS的Master通过主从热备实现了高可用解决方案,由Zookeeper实现监控、选举和切换;文件标识和块管理由独立的MetaServer进行管理,它记录了文件属性、长度以及该文件拥有的块等信息;与Datanode类似,块物理存储和访问由NodeServer负责。客户端在访问XFS时,先通过文件名在Master上获取MetaServer标识和文件标识等信息,然后在指定的MetaServer上获得需要请求的文件信息或者块信息,如果要访问文件的块,则通过NodeServer获取块内容。
实现推测:
1、 master部分实现了一个简单的命名空间如树形结构,文件id,Meta id等,客户端获得这些值到元数据服务器去获得文件的其他属性,及其块映射关系;
2、 客户端通过获得的块位置到相应的NodeServer节点操作相应的数据块;
3、 Master通过Zookeeper实现高可用,元数据服务器可以实现冗余模式保证高可用;
Xfs架构图如下
2.5 MAPR
通过官方介绍,实现了无锁存储服务,据说比hdfs速度快3倍;namenode实现分布式话,默认存储3份,可以指定元数据存储分数,并且具有自动修复功能,如果某台机器坏了,会在其他机器修复该元数据,保存该数据始终有3份。
2.6 Clover
由中科院研发,实现了元数据的分布式冗余
2.7 Ceph
Ceph为一个分布式存储系统,提供了restful及其fuse(目前可能已经实现内核态)接口,元数据存储和对象存储均实现了支持冗余分布式,元数据与对象分开存储,客户端通过元数据服务器获得对象的位置,然后通过客户端直接获取。
CEPH采用元数据和文件数据分开处理的体系结构,由三个子系统组成:客户端(CLIENT),元数据服务器集群(Metadata Cluster)和对象存储集群(Object StorageCluster)。MDS维护全局的名字空间,负责处理元数据相关的请求以及相心的权限管理:对象存储设备负责文
件数据和元数据的存储,为客户端和MDS提供统一的数据读写服务。在CEPH中,元数据保存在对象存储设备中,MDS幂IJ用缓存的数据对外提供服务。由于MDS本身并不
存储数据,所以可以很方便地进行目录子树的复制迁移以实现负载均衡。通过监控访问的热度等进行负载均衡。
2.8 其他
AvatarNode
通过NFS共享EditLog文件,人工切换namenode,可在秒到分钟内完成;
优点:由于采用热备,单个namenodedown掉可以快速切换,提供正常服务;
缺点:同时服务的仅一个namenode,因此仍然存在性能瓶颈;
Cloudera CDH4与AvatarNode类似。
2.9 命名空间
存储系统都涉及到命名空间的概念,从上面的调研已经明确,命名空间一般分为2类:树形命名空间和平坦命名空间。具体如下:
树形命名空间:元数据以树形结构维护,文件系统最大的问题就是扩展性,完全取决于他的树状结构,扩展起来相当困难。
平坦命名空间:元数据以2层或者层数很少来维护,实现对象存储的概念。亚马逊支撑对象数可以支撑上千亿,是现在最大的存储集群。
不同业务,可能命名空间选择不一样。
2.10 元数据管理
动态子树:出现热点数据或者MDS负载过高时可以很方便地进行目录子树的复制和迁
移,易于扩展MDS和负载均衡,但实现较为复杂。
静态子树:元数据与MDS的对应关系一旦确立就不会改变,容易出现负载不均衡。
Hash算法:初始的时候,可以通过良好的设计使得元数据在MDS间均匀分布,整体负载比较均衡,但是在增加或减少MDS的时候,需要重新调整hash函数,会导致人量的数据迁移。
3对比总结
1)腾讯的XFS与百度的HDFS2优点类似,均实现了3层结构:命名空间;文件块管理;数据块管理,Federation和MAPR与这2个架构类似;
2)像HDFS2,ceph动态树是否会影响ls的性能;MAPR等如何满足ls还不清楚;
2)TBFS与XFS和HDFS2均不一致,通过数据库集群保存元数据,同一时刻运行的仅一个Namenode节点;
3)AvatarNode,CDH4等通过NFS等共享存储方式实现高可用性
4 JDFS开发步骤
1)先通过AvatarNode等方式,实现高可用性,如果存储1亿的文件,需要内存空间约38GB,单机可以满足该需求,到一定规模再增加集群;
2)通过HDFS2,XFS,Federation等方式实现namenode的功能分离,将元数据层分为2层:命名空间层和元数据层,并且实现该部分分布式。当然可以考虑基于Federation改造,借鉴Ceph等,考虑是否实现树状命名空间还是平台命名空间或者同时满足;
3)在2)的基础之上借鉴Ceph等再实现冗余,及其自我检查与修复模式;
5 附件
6参考资料
1、 百度分布式文件系统介绍-马如悦
2、 HDFS改造对比
https://github.com/taobao/ADFS/wiki/3.-%E6%96%B9%E6%A1%88%E6%AF%94%E8%BE%83
3、 HDFS元数据的独立服务和独立持久化存储-罗李
4、 HDFS2,一种分布式NN实现-孙桂林
5、 Hadoop的最新进展-马如悦
6、 百度搜索研发部-分布式数据访问调研
http://stblog.baidu-tech.com/?p=438
7、 CEPH动态元数据管理方法分析与改进
8、 DynamicMetadataManagementforPetabyte-scaleFileSystems
9、 Ceph: A Scalable,High-Performance Distributed File System
10、CRUSH: Controlled, Scalable, Decentralized Placement of ReplicatedData
11、RADOS: A Scalable, Reliable Storage Service for Petabyte-sc
评论暂时关闭