图解zookeeper FastLeader选举算法,zookeeper
图解zookeeper FastLeader选举算法,zookeeper
zookeeper配置为集群模式时,在启动或异常情况时会选举出一个实例作为Leader。其默认选举算法为FastLeaderElection。
不知道zookeeper的可以考虑这样一个问题:某个服务可以配置为多个实例共同构成一个集群对外提供服务。其每一个实例本地都存有冗余数据,每一个实例都可以直接对外提供读写服务。在这个集群中为了保证数据的一致性,需要有一个Leader来协调一些事务。那么问题来了:如何确定哪一个实例是Leader呢?
问题的难点在于:
- 没有一个仲裁者来选定Leader
- 每一个实例本地可能已经存在数据,不确定哪个实例上的数据是最新的
分布式选举算法正是用来解决这个问题的。
本文基于zookeeper 3.4.6 的源码进行分析。FastLeaderElection算法的源码全部位于FastLeaderElection.java文件中,其对外接口为FastLeaderElection.lookForLeader,该接口是一个同步接口,直到选举结束才会返回。同样由于网上已有类似文章,所以我就从图示的角度来阐述。阅读一些其他文章有利于获得初步印象:
- 深入浅出Zookeeper之五 Leader选举,代码导读
- zookeeper3.3.3源码分析(二)FastLeader选举算法,文字描述较细
主要流程
阅读代码和以上推荐文章可以把整个流程梳理清楚。实现上,包括了一个消息处理主循环,也是选举的主要逻辑,以及一个消息发送队列处理线程和消息解码线程。主要流程可概括为下图:
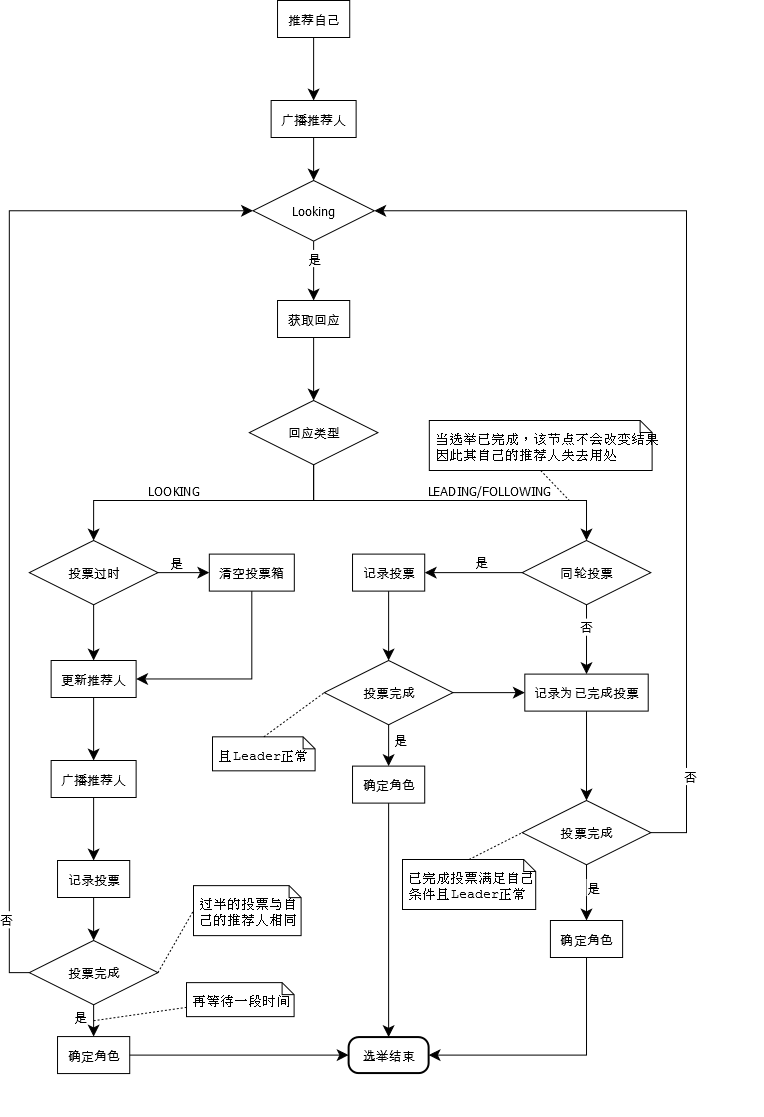
推荐对照着推荐的文章及代码理解,不赘述。
我们从感性上来理解这个算法。
每一个节点,相当于一个选民,他们都有自己的推荐人,最开始他们都推荐自己。谁更适合成为Leader有一个简单的规则,例如sid够大(配置)、持有的数据够新(zxid够大)。每个选民都告诉其他选民自己目前的推荐人是谁,类似于出去搞宣传拉拢其他选民。每一个选民发现有比自己更适合的人时就转而推荐这个更适合的人。最后,大部分人意见一致时,就可以结束选举。
就这么简单。总体上有一种不断演化逼近结果的感觉。
当然,会有些特殊情况的处理。例如总共3个选民,1和2已经确定3是Leader,但3还不知情,此时就走入LEADING/FOLLOWING的分支,选民3只是接收结果。
代码中不是所有逻辑都在这个大流程中完成的。在接收消息线程中,还可能单独地回应某个节点(WorkerReceiver.run):
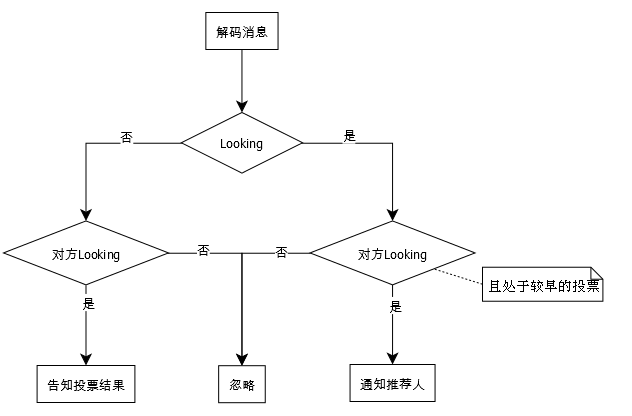
从这里可以看出,当某个节点已经确定选举结果不再处于LOOKING状态时,其收到LOOKING消息时都会直接回应选举的最终结果。结合上面那个比方,相当于某次选举结束了,这个时候来了选民4又发起一次新的选举,那么其他选民就直接告诉它当前的Leader情况。相当于,在这个集群主从已经就绪的情况下,又开启了一个实例,这个实例就会直接使用当前的选举结果。
状态转换
每个节点上有一些关键的数据结构:
- 当前推荐人,初始推荐自己,每次收到其他更好的推荐人时就更新
- 其他人的投票集合,用于确定何时选举结束
每次推荐人更新时就会进行广播,正是这个不断地广播驱动整个算法趋向于结果。假设有3个节点A/B/C,其都还没有数据,按照sid关系为C>B>A,那么按照规则,C更可能成为Leader,其各个节点的状态转换为:
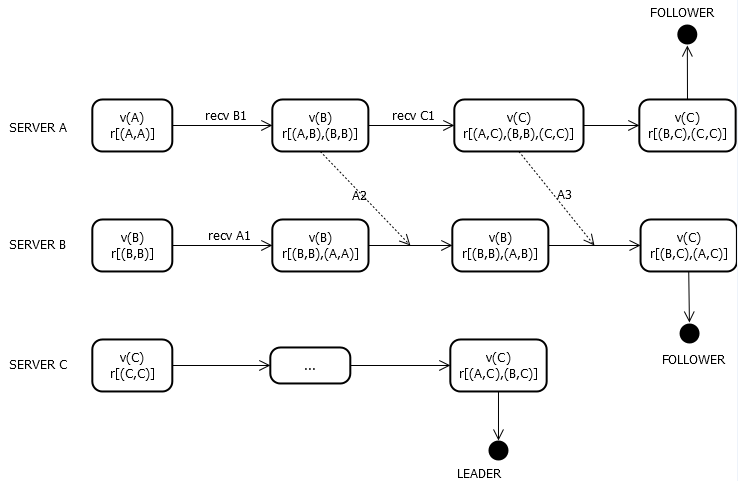
图中,v(A)表示当前推荐人为A;r[]表示收到的投票集合。
可以看看当其他节点已经确定投票结果时,即不再是LOOKING时的状态:
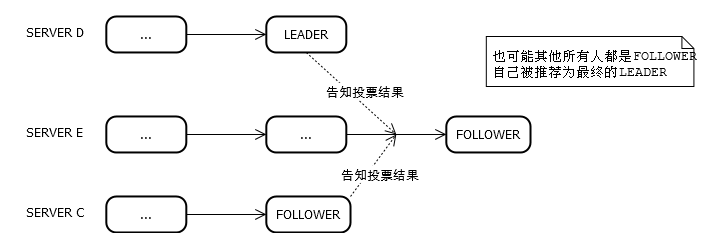
代码中有一个特殊的投票集合outofelection,我理解为选举已结束的那些投票,这些投票仅用于表征选举结果。
当一个新启动的节点加入集群时,它对集群内其他节点发出投票请求,而其他节点已不处于LOOKING状态,此时其他节点回应选举结果,该节点收集这些结果到outofelection中,最终在收到合法LEADER消息且这些选票也构成选举结束条件时,该节点就结束自己的选举行为。注意到代码中会logicalclock = n.electionEpoch;更新选举轮数
完
每个机器节点加入,都发起一次Vote。
zookeeper server节点接受到新一轮的Vote,都返回上一轮的Leader选举的最后Vote结果。如果处于LOOKING,比如第一次加入的机器,则Vote自己
发起Vote的机器,收集完所有server的Vote结果(包括自己),统计一下结果,并且判断一下是否超过半数Java代码 if (result.winningCount > (self.getVotingView().size() / 2)) 注意:这里的>号,所以如果单台机器启动,无法通过给自己Vote,使自己成为Leader。一定要>=2台机器的参与
如果没有超过半数,则记录一下本次的投票结果。下一次Vote时,就直接投给上一轮票数最高的Vote,继续进入步骤3
说明: myid序号大的在Vote选举时比较有优势,同样的票数winner会是myid最大的server,从而保证每次的Vote必然会产生一个唯一的winner。
FastLeaderElection算法:
每个机器节点加入,都向外部建议自己做为Leader。zookeeper server接受到请求后,进行一个抉择: Java代码 if ((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId))) 判断当前的zxid和myid是否大于当前Vote,如果是则更新之,并同样广播给所有的server。注意: Notification中有个epoch标志,表明当前发起的Vote的传递的次数。比如A发给B,B更新了自己的Vote后,再发给C。这时发的通知中epoch=2。 有点类似图论里的概念,如果notice.epoch < 当前最后一次更新Vote的epoch,则不做任何处理。一个逐步收敛的有向环图单个机器上收到了其他所有机器的Vote结果后,判断出最后的winner结果
Leader处理:
启动LearnerCnxAcceptor,监听Follower的请求。针对每个链接的Follower,开启一个新线程LearnerHandler进行处理
然后针对所有的LearnerHandler,while(true)进行心跳检查ping。针对每次ping结果,针对有ack响应的结果进行vote统计,如果发现超过半数失败,则退出当前的Leader模式,这样又是发起新一轮的选举
Follower处理:
建立socket,链接到Leader server上发起一次syncWithLeader同步请求,此时Leader会根据当前的最大的zxid对比客户端的zxid,发送DIFF/TRUNC/SNAP指令给follower上,保证follower和leader之间的数据一致性。同步完成后,就进入while(true){read , process}的工作模式,开始接受Leader的指令并处理PING : 响应AckPROPOSAL : 记录到自己的缓冲队列pendingTxns中,等待sync指令后刷新到zkDataBase中。有点类似2PC阶段事务COMMIT : 刷新pendingTxns中的对应记录SYNC : 客户端的同步request请求Observer处理:建立socket,链接到Leader server上发起一次syncWithLeader同步请求同
步完成后,进入while(true){read ,
process......余下全文>>
想竞选的就写一篇演讲稿,然后演讲,再让大家投票
或让游玩者评价,好的就当
评论暂时关闭