年度GPU架构回顾 显示世界的2012(1)(2)
宿命,开普勒登场
Tahiti的革新可以说是2012年架构革新的一剂强心剂,它不仅让我们看到了希望,更对竞争对手NVIDIA的新架构充满了期待。与Tahiti的开放和释放信心不同,NVIDIA接替Fermi的开普勒架构一直做足了保密工作,直到发布的一瞬间才让整个世界为之一顿。

性能功耗比革新巨大的开普勒
开普勒图形构架拥有超过35亿的晶体管规模,核心面积294平方毫米。与上代的Fermi构架相比,其运算资源总量提升到了1536个ALU,Texture Filter Unit由Fermi的64个增加到了128个,构成后端的ROP则下降为32个。GTX680同样拥有全新设计的MC结构,4个64bit双通道显存控制器组合形成了全新的256bit显存控制单元,GTX680也因此采用了容量达2048MB的显存体系。
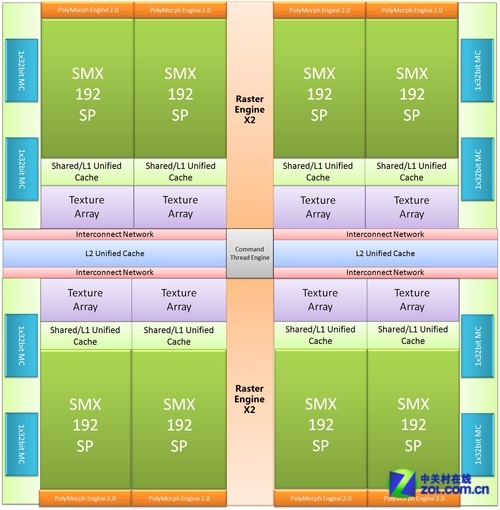
完整的GK104架构
GTX680的特色由六个主要的部分组成:
1、与Tahiti同样基于HKMG的TSMC全新28nm工艺。
2、与Fermi完全相同的4XGPC宏观并行设计。
3、8个包含了几何引擎、光栅化引擎以及线程仲裁管理机制的SMX单元。每个SMX单元包含一组改进型的负责出力几何任务需求的PolyMorph Engine,192个负责处理运算任务及Pixel Shader的ALU,16个负责处理材质以及特种运算任务如卷积、快速傅里叶变换等的Texture Array,二级线程管理机制以及与它们对应的shared+unified cache等缓冲体系。
4、负责完成fillrate过程以及输出最终画面的32个ROP单元阵列,以及对应L2 cache的4个64bit显存控制器MCMemory Controller),负责视频回放及处理的PureVideo HD单元,以及全新的负责视频编码部分的NVENC。
5、根据功耗以及用户自定义负载需求实时调节GPU的GPU Boost功能,全新的TXAA以及抑制画面撕裂和顿挫的Adaptive VSync主动垂直同步技术。

开普勒架构GK104芯片核心照片
开普勒构架与Fermi构架在宏观层面上非常接近,其改进主要集中在微观结构层面,它使用了全新的SMX单元来替代传统ALU团簇结构,弃用了沿用数年的ALU分频机制,进一步改进了包括Cache/shared以及寄存器在内的缓冲体系,调整了线程仲裁机制并引入了全新的scheduling过程,为今后的架构发展做出了铺垫,引入了开创性的功耗性能管理机制,同时还强化了单卡多屏输出等功能性环节。
Tahiti与开普勒在宏观和微观结构对比中互有异同,Tahiti可以被看做是一个不同于AMD既往产品的,对称并行分布、core部分神似larrabee而uncore部分接近Fermi的全新结构,开普勒则可以被看做是一个4GPC并行,内部结构大幅调整优化的同时保留了之前产品优势的作品。Tahiti架构在维持吞吐的同时转向强调灵活性并进行了针对改进,而开普勒则在维持灵活性的前提下做出了平衡性能与功耗的努力。两者都在向着中线,也就是最佳的性能功耗比去靠拢。
评论暂时关闭