年度GPU架构回顾 显示世界的2012(1)(4)
多米诺骨牌
整体而言,一颗芯片在特定工艺下的规模是存在上限的,制造者不可能无限制的放大芯片的规模。而上限的存在又意味着两个截然不同的结局,你可以用更小的规模换取更好的可制造性,或者在触及上限时面对晶体管使用方向的平衡问题。AMD面临的由寄存器导致的多米诺骨牌效应,就是后者作用的结果。
其实这说起来很简单——Tahiti为寄存器付出了10亿甚至更多的晶体管代价,这些晶体管让它更快的达到了芯片规模的上限。如果没有这层负担,Tahiti本来可以获得更小的芯片面积以及更好的功耗表现,或者用这些晶体管来制造更多“针对图形”的单元来获得更好的图形性能。它可以被塑造成一个与开普勒架构的GK104规模相当,功耗表现比现在更加优秀的产品,或者可以用这10亿晶体管来强化并行度设计,也继续补足曲面细分性能,还能增加ALU、Tex或者MC/ROP的规模等等,对于10亿个晶体管来说,有太多美好的可能可供Tahiti去选择了。
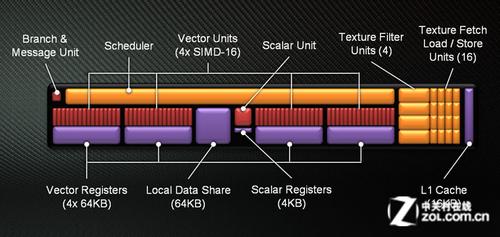
Tahiti构架CU结构细节
但是现在,由于寄存器使用策略和算法的问题,AMD不得不背负这10亿晶体管的负担。少了这10亿晶体管,以上那些美好的可能全都无法实现,Tahiti架构不得不止步于当前的规模,各项针对过去积累架构错误的先进技术改进都没有进行彻底,传统图形领域相对强势的后端优势得不到发挥,而且还要因此而承受规模释放困难,功耗难以控制等各种各样的问题。无论技术改进和愿景多美好,没有晶体管可用,一切都是空谈。所以由寄存器引发的一个又一个不利的因素像多米诺骨牌那样倒下,最终造就了Tahiti“什么改进和技术革新都好就是效果不好”的结局。
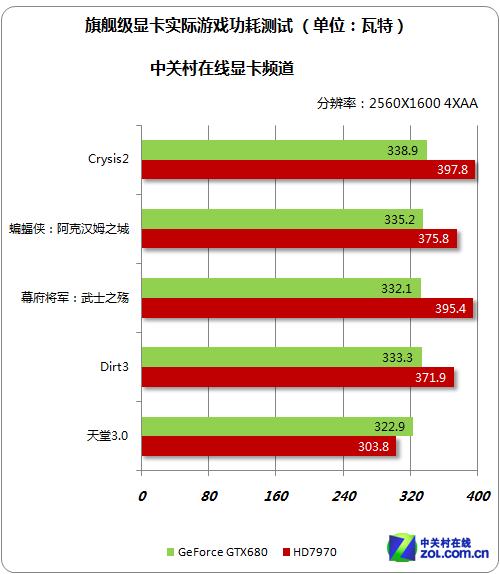
Tahiti架构与开普勒架构在实际游戏测试中的功耗对比
而没有这层负担的开普勒,则利用这份优势强化了并行化结构、曲面细分以及各种各样的图形相关部分,并在突出图形性能和运算性能平衡的同时依旧维持了比Tahiti少8亿的晶体管规模。其所要经历的事情也就非常简单直接了——性能和效率高于Tahiti,芯片面积小于Tahiti,功耗低于Tahiti……
不光开普勒,即便是在GCN阵营内部,同样也存在着Tahiti的对立面,那就是面向甜品级的Pitcairn架构。
评论暂时关闭