年度GPU架构回顾 显示世界的2012(1)(3)
AMD的致命伤——寄存器
开普勒与Tahiti都是双方积蓄许久之后爆发的革新之作,都应用了双方最全面的新技术和各项突破,其中Tahiti架构的革新不仅目的性更强烈而且也应该更加行之有效,但它们在旗舰级领域的对决结局却是出人意料的。尽管提前发布了73天,同时兼顾了大量革新且具有纠偏意义的理念和技术,但基于Tahiti的HD7900系列依旧在性能、功耗和成本等所有环节全部落败。大核心在功耗和成本层面输给小核心尚属正常,但在此基础上还在性能对决中输给小核心,这在GPU发展史上是非常罕见的——即便是功耗和成本令人诟病的GF100,起码也在性能和DirectX 11效率层面保住了面子。
是什么让Tahiti对各项先进技术的整合出现了状况并输掉了竞争呢?这个问题对我们来说既熟悉又陌生——让Tahiti陷入这样境地的根本,来自其架构内部的寄存器设计,而且早在一年半以前的GCN情报分析中,我们就已经对寄存器的隐患提出了预警。
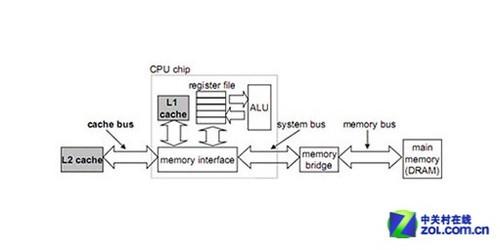
寄存器在处理器中的地位
作为最重要的缓冲单元,寄存器需要面对来自线程Thread)和数据的缓冲需求。如果设计者缺乏寄存器的使用和管理经验,寄存器对于每个线程的复用率较低,或者说每个线程在特定时间片段内可以占用的寄存器数量不足,要满足大并行度Thread的性能需求就必须通过增大寄存器总量的手段来完成。在此基础上,双精度数据通常需要组合单精度寄存器来完成缓冲需求,因此双精度数据对寄存器的需求量要来的更大,如果此时寄存器复用状况不佳,要保证线程充分并行和DP运算的性能需求,唯一的做法就只有进一步加大寄存器总量一途而已了。
为方便理解,我们将寄存器数量折合成3项指标,分别是Reg per Thread每线程寄存器数量),Reg per ALU每ALU寄存器均摊数量)和DP Reg双精度寄存器)。Reg per Thread越高,架构就能以越少的寄存器总量来满足尽可能多的线程并行处理需求,进而在等量寄存器的前提下腾出更多的空间给提升DP性能做准备。Reg per Thread越低,架构就需要以更多地寄存器总量来满足并行处理需求。寄存器的整体需求量可以被不严谨但简单的量化成Reg per ALU数值,一个架构的Reg per Thread越低,它实现更高线程并行度和DP性能所需要的Reg总量就越高,摊到每一个ALU身上的Reg per ALU数值也就越高。
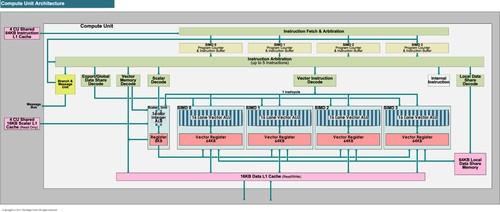
包含缓冲体系的CU单元内部结构
好了,现在我们来到了问题的关键环节。根据AMD和NVIDIA公布的数据,Tahiti架构拥有总计8192KB的32bit Vector Reg,在不考虑Scalar Reg等其他特殊需求寄存器的前提下,其Reg per ALU为4KB,它可以实现1/4速的DP性能。而开普勒架构的Reg per ALU数量则为1.33KB,NVIDIA可以以这一数值的实现1/3速的DP性能GK110)。另外作为参考,Fermi的这一数值为4KB per ALU/半速DP。
4KB per ALU的Tahiti和1.33KB per ALU的开普勒,这样的数据意味着什么事呢?我们来算一笔通俗的帐——1个最基本的1bit sram单元需要6个晶体管来实现,更高的频率以及更低的延迟会让单元的晶体管数量进一步增加,我们并不清楚AMD和NVIDIA目前所处的频率水平需要多少晶体管来实现1bit的寄存器,但即便忽略一切其他相关单元,单纯考虑纯sram部分并用最保守的6晶体管方案来计算,4KB per ALU意味着Tahiti架构每个ALU均摊的寄存器晶体管数为786432个6*32*1024*4),而NVIDIA每个ALU均摊的寄存器所占用的晶体管数则仅为261489个6*32*1024*1.33)。
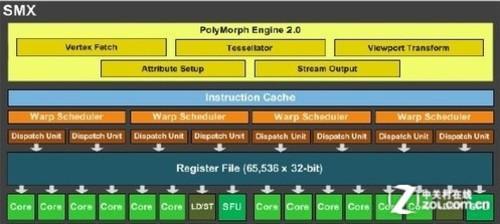
SMX单元中的寄存器数量
对于每一个ALU及其周边资源来说,Tahiti需要比开普勒多付出最少超过50万个晶体管的代价,而Tahiti架构总计拥有2048个Vector ALU,换句话说,就是即便以最保守的方式来计算,AMD在Tahiti架构中为寄存器所多付出的晶体管代价也在10亿以上。如果AMD进一步扩大Tahiti架构的Vector ALU规模,或者在寄存器单元中使用的是可以应对更高频率的7晶体管甚至8晶体管方案,这一数值还将继续扩大。
而Tahiti架构,一共只有4.3个“10亿晶体管”。

Intel 45nm工艺下的6T sram单元
并未超越对手的计算特征和效率、比竞争对手高的Reg per ALU还有更大的DP衰减幅度,这些现象都反映了AMD在寄存器使用策略和算法上的存在的差距,它表明AMD无法完全解决诸如Reg pool以及rename之类许多环节的问题,所以只能以极大的寄存器总量来同时满足Thread性能/DP性能的需求,而这种解决方案恰恰是最致命的。单纯增加规模不仅低效,而且增加出来的晶体管并不会直接产生任何Flops或者图形性能。想要提升DP性能和Thread性能,AMD必须在扩充运算单元规模的同时付出比对手更多的寄存器晶体管代价,而对寄存器的过量使用不仅造成了Tahiti架构更容易受到D线的压迫,让功耗控制变得更加困难,还引发了一系列多米诺骨牌效应并挫伤了其在图形领域的表现。
评论暂时关闭